This incident retro was tougher than most to share because, despite the seriousness of the issue, it affected only a very small percentage of our user base. However, we learned some incredibly valuable lessons and I think it's only right that I give others the chance to learn from our mistake as well.
Context
On Thursday July 8th, we merged a very large PR that updated our code to start using our new User Settings instead of the deprecated fields on users. The goal of moving these fields to user settings is to lighten up the user model and make these types of settings more configurable on a per-Forem basis.
Problem
On July 9th around midday, it was brought to our attention through a bug report that the comment creation experience on the frontend seemed to be broken. At this point folks on the team started looking into the problem. Using Honeycomb, we were able to confirm that the problem started when the User Settings PR was deployed which made it the prime suspect.
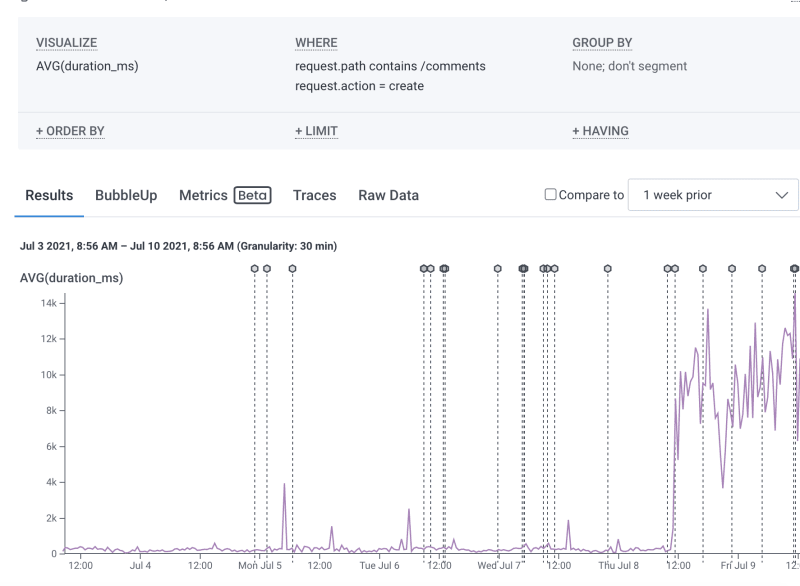
I immediately dove into the PR and quickly found the line of code that had been broken.

We had incorrectly removed the user_ids scope from the filtering used to collect user IDs for sending mobile push notifications. This was causing us to attempt to grab notification settings and IDs for all users with mobile notifications turned on which was often timing out. These timeouts would occur after a comment was created so the comment in most cases still existed but we never returned a success response to the frontend. This caused the frontend to freeze creating a bad experience for the user.
Fix
In order to remedy this situation, we quickly added back the scope and deployed. Immediately the errors and timeouts went away and things returned to normal for comment creation.
At this point, we concluded that possibly some extra notifications had been sent but that the majority of these requests had timed out so we assumed we were in a good state now. I looked for some sort of push notification model in our app where we might have stored unsent notifications but upon not finding one figured we were clear.
More Problems
July 9th ~12pm EDT: Unfortunately, the above assumption was incorrect. Just before midnight eastern, a team member reported she was getting random notifications on her phone. At this point, our mobile engineer jumped in to investigate and found that we had a ton of push notifications enqueued in Redis.
July 9th ~2am EDT: Mobile engineer posts about the issue in our #emergency Slack channel.
July 9th ~7am EDT: On-call engineer wakes up and sees the #emergency Slack message and jumps in to help investigate and try to resolve the issue. Shortly after, I also jumped in. It was at this point that I learned all about how our push notification system worked. We use RPush for communicating with various push-notification services. RPush stores the data about the push notifications in Redis for quick insertion and removal times. We quickly assessed that we had a large number of push notifications enqueued in Redis waiting to be sent, despite the solution deployed the day before.
Fix 2
Upon realizing we had all of these records in Redis, we took the following steps to resolve the issue:
- Removal of the iOS cert from Heroku to prevent sending any notifications. Without this cert we could ensure we would not send anymore bad notifications and that would give us time to fix the data in Redis.
- To be safe, we removed all of the
PushNotifications::DeliveryWorkerjobs from Sidekiq so as not to be pinging Redis for the keys causing our key collection to slow down.- At the same time, we looped through all of the keys in Redis and collected all of the rpush ones. These included all delivered and undelivered keys. There were 1.2 million rpush keys so this process took about 30 mins. We used the below script:
redis = Rails.cache.redis
start = 0
total = 0
key_collection = []
index, keys = redis.scan(start);
while index != "0"
start = index
total += keys.count
keys.each do |key|
key_collection << key if key.include?('rpush:notifications')
end
index, keys = redis.scan(start)
end
- Once we had the keys collected we double checked that they were the keys we wanted and then we deleted them ALL in batches of 10 using this code:
key_collection.each_slice(10){|s| puts redis.del(s)}
- Once the keys were gone, we double checked the count and then added back the iOS cert to Heroku.
- After Heroku restarted, we ran a test to confirm that the notifications were back to sending and that we were recording delivered notifications correctly again in Redis.
Impact
Comment Creation
The comment creation flow on the frontend was broken for 30 hours after the UserSettings PR was deployed on July 8th. However, comment creation levels remained steady.
irb(main):001:0> Comment.where(created_at: 36.hours.ago..Time.now).count
=> 762
irb(main):002:0> Comment.where(created_at: 72.hours.ago..36.hours.ago).count
=> 857
irb(main):003:0> Comment.where(created_at: 108.hours.ago..72.hours.ago).count
=> 852
irb(main):004:0> Comment.where(created_at: 144.hours.ago..108.hours.ago).count
=> 756
irb(main):005:0> Comment.where(created_at: 180.hours.ago..144.hours.ago).count
=> 587
In total, there were 934 comments that were affected by the broken frontend interface.

Push Notifications
Given DEV is early on in its mobile journey, only 0.2% of our users have registered devices that are able to receive push notifications. This means that only 0.2% of our users were affected by this incident. We consider ourselves lucky that we were able to expose some of these issues and have this incident remain very contained.
Since the numbers of users affected was small, we decide to proactively reach out to all of those folks via email to apologize and explain why they might have received erroneous notifications.
Learnings
Large PRs
Large PRs naturally come with more risk. The bug that kicked off this stream of events was a small change in a very large PR that got missed by multiple folks. For starters, the diff for the line was not particularly helpful in recognizing the change that caused the issue. In addition, there were so many lines that it was easy to overlook. Breaking down PRs is one way to prevent this.
However, there are times when large, wide spread changes need to be made and in those cases you have to rely on your test suite.
Missing tests
The feature that broke was completely untested. Had we been testing that feature properly I think there is a good chance the bug could have been caught. Immediately after pushing the hotfix I added a test to ensure this never happens again.
Technical feature education
After fixing the bug, none of us working on the problem were well educated about how our Push Notification systems worked. Being late on a Friday, we skimmed the code and concluded we would be good to go. This ended up being the wrong assumption as we later learned Saturday that push notifications, unlike app ones, are stored and enqueued via Redis. I think it's more important than ever that we are somehow sharing and educating each other about some of these larger features as we roll them out.
Thankfully, we do have some great Push Notification documentation but it was never sought out during the incident. Is there a way we can make docs like this more visible? During the incident we were all heads down in the code, should we maybe have some sort of URL link in the code to the docs?
Being more intentional
I could have very easily reached out to our mobile team on Friday evening to double check that we were in a good state for Push Notifications. Once again, the whole Friday evening and wanting to be done caused me to accept my assumptions rather than challenge and check them.
One easy way to prevent something like this is to use a checklist. A checklist (heavily used in aviation because it has been shown to be key in preventing incidents,) is an easy way to make sure you never miss something and are deliberate and intentional with your decisions. We have great checklists for handling Heroku incidents in our internal Gitbook. However, we don't have a general incident on-call checklist which we plan to add.
Incident Response
Before I dive into specifics, I want to point out that this is the first larger incident we have had in a while. Incidents being rare is GREAT! But, it also means that our incident response was a bit rusty and our documented incident processes were a bit out of date to handle this situation. Going forward we will be taking a closer look at all of these things to ensure we are keeping them relevant and useful based on the current state of our application and team.
Broken Comment Creation Reporting Flow
The initial comment creation problem was reported by a DEV user via a GitHub issue and seen about 11 hours later by our internal engineering team. GitHub Issues are naturally not a very urgent form of reporting for us since they are handled during working hours. One way we could improve this flow would be to further communicate that urgent support issues need to be emailed to yo@forem.com. Our customer success team is always monitoring these channels diligently and could more quickly triage and escalate an issue to the team.
Manual reporting aside, ideally, we should have caught this programmatically with our monitoring by alerting on the increased HTTP request errors that were detected.
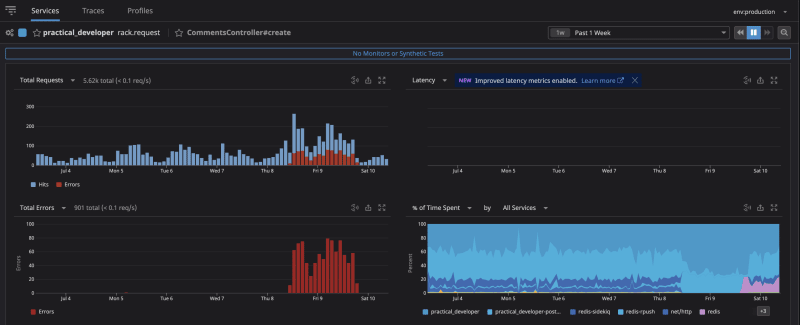
Going forward, we plan to set up a monitor to alert us for these changes so that we are the first to find out, rather than relying on users reporting the issue to us. With the proper monitor in place, we could have caught this within a couple of hours instead of over a day.
Broken Push Notifications Reporting Flow
We responded to the broken comment creation issue immediately when it was surfaced, however, the followup push notification issues were not. Our engineer correctly pinged the #emergency channel when he realized that we were having problems with notifications but did not escalate the issue and wake up the on-call dev via PagerDuty.
One way we could streamline this process would be to see if we could set up our #emergency Slack channel to automatically ping PageDuty when a message is posted. Another option is address some of our incident response rustiness by better educating the team on our desired incident response flows. This probably needs to be a reoccurring training that happens periodically so as to prevent processes and knowledge from getting stale as our systems evolve.
Technical Remediation
One delay we encountered when trying to fix this issue was that the Rpush keys were stored in the same Redis instance as our Rails cache. Given our Rails cache is massive and contains 4+ million keys, looping through all of them to find only the Rpush keys was tedious and took a while. That cache is also very active which caused us to hit some timeouts when we were trying to perform heavier operations on it.
We could have mitigated this friction by having either a separate Redis instance for Rpush OR by having those keys in a separate database away from our Rails cache keys. Going forward, as we grow our mobile platforms, I think we should make one of the above changes to ensure that we have easy access to these keys and records. It will also ensure that as we grow and scale push notifications we don't have to worry about impacting other systems like our core Rails app.
Thanks Everyone 🤗
A lot of people gave up their personal time to come together on Friday and Saturday to mitigate and fix these issues. I truly appreciate the amazing team we have at Forem and their dedication to this software. We learned a lot about our systems in the process which ensures that this incident will not go to waste. I hope others can learn from this as well.


















