
I built chisel.cloud in my spare time to automate something I did to derive insights about my Gitlab pipeline times.
In this blog post I’m going to show you how I did it in the hope that it might be useful to you too.

As you can see from the picture above, Chisel is still pretty early stage. I decided to publish it anyway because I’m curious to know whether something like this can be useful to you too or not.
Understanding deployment time
The goal of this exercise was for me to better understand the deployment time (from build to being live in production) of my project and have a data-driven approach as to what to do next.
Since the project in question uses Gitlab CI/CD, I thought of taking advantage of its API to pull down this kind of information.
Gitlab Pipelines API
The Gitlab pipelines API is pretty straightforward but a few differences between the /pipelines and the /pipelines/:id APIs means that you have to do a little composition work to pull down interesting data.
Here’s how I did it.
1. Pull down your successful pipelines
First thing I did was fetching the successful pipelines for my project.
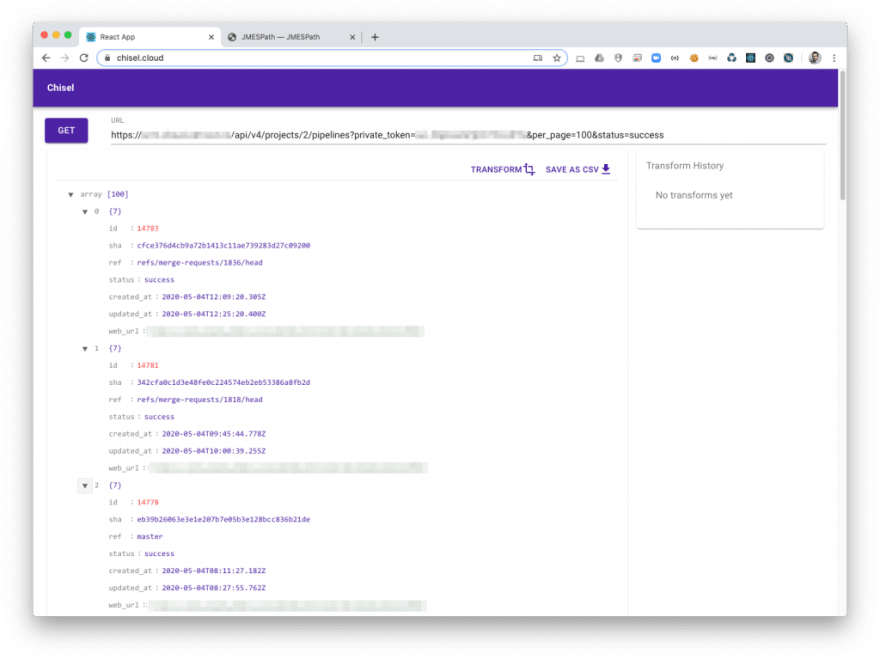
As you can see, this API returns minimal information about each pipeline. What I needed to do next in order to understand pipeline times was to fetch further details for each pipeline.
Chisel – Transform
Chisel provides a handy transformation tool that uses JMESPath to help you manipulate the JSON returned by the API you are working with. I used it to extract the pipeline IDs from the returned response.
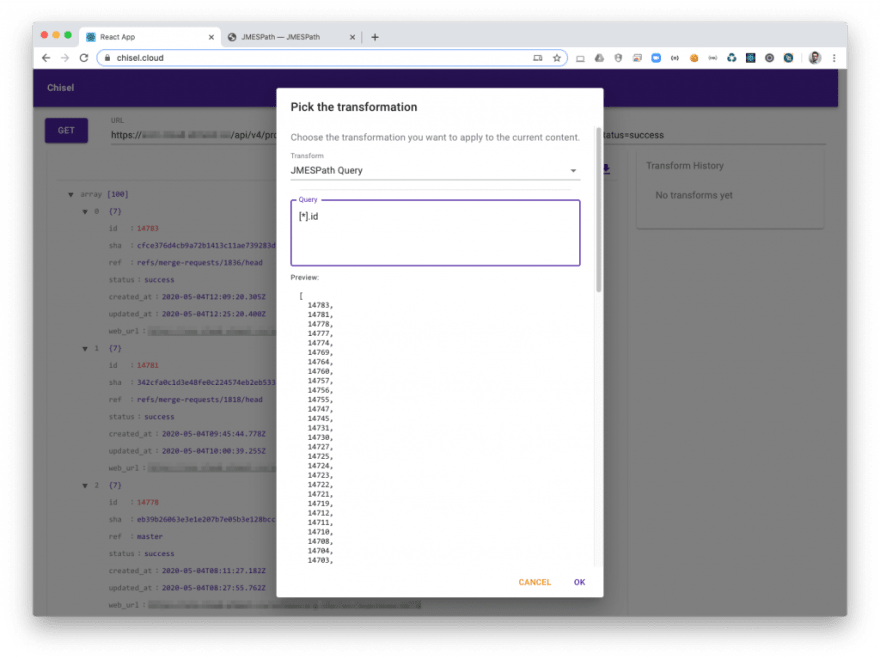
Chisel shows you an live preview of your transformation. Something as simple as [*].id is enough for now. The result is an array of pipeline IDs.
Right after obtaining all the IDs I need I can apply another transformation to turn those IDs into pipeline objects with all the relevant information I need for my stats.
Chisel has another kind of transformation type called Fetch that helps you transform the selected values into the result of something fetched from a URL.

In particular, you can use the ${1} placeholder to pass in the mapped value. In my case, each ID is being mapped to the /pipelines/${1} API.
The result is pretty straightforward.
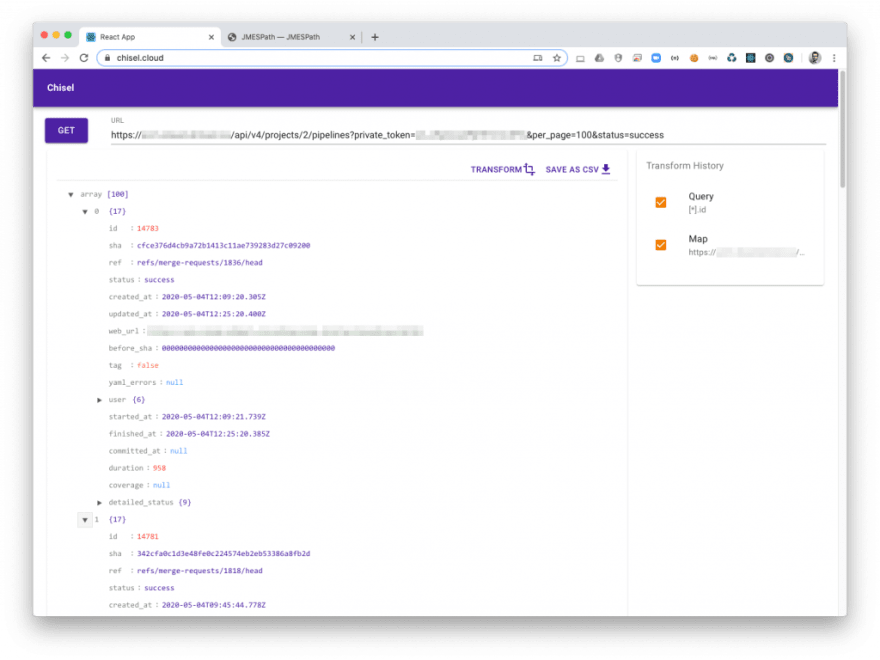
2. Filter out what you don’t need
As you can see, some of the returned pipelines have a before_shaof value 0000000000000000000000000000000000000000. Those are pipelines triggered outside of merges into master so I’m not interested in them.
Filtering those out is as simple as [?before_sha != '0000000000000000000000000000000000000000]

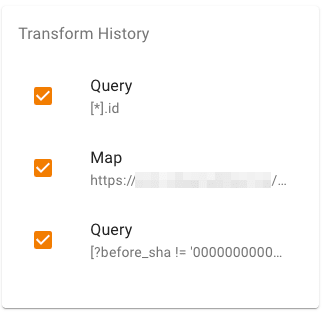
The transformation history
As you can see, on the right of the screen there’s a little widget that shows you the transformations you have applied. You can use it to go back and forth in the transformation history and rollback/reapply the modifications to your data.
3. The last transformation
The last transformation I need to be able to start pulling out useful information has to turn my output into a set of records.
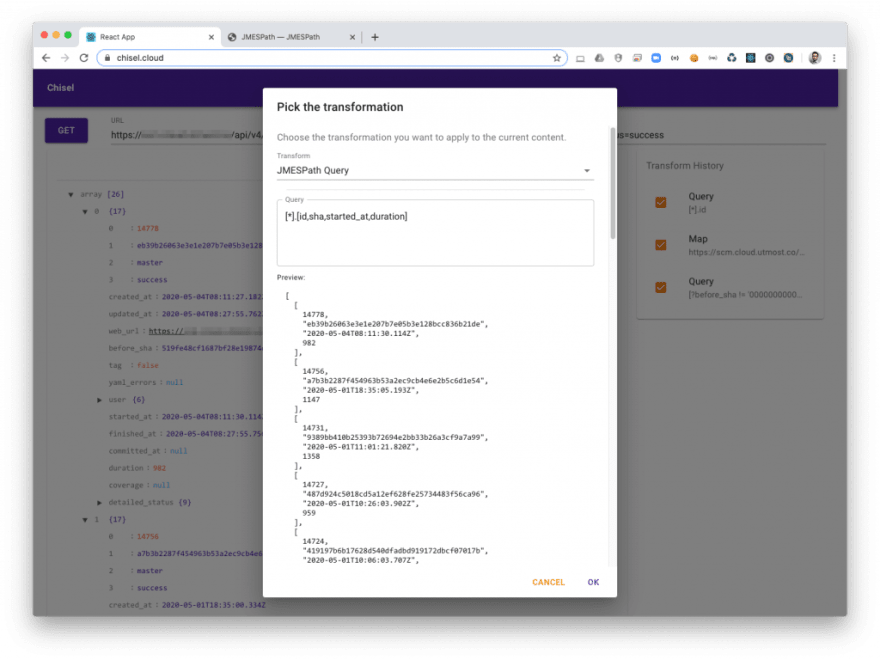
I’m selecting only a few fields and turning the result into an array of array. This is the right format to be able to export it as a CSV.
Google Sheets
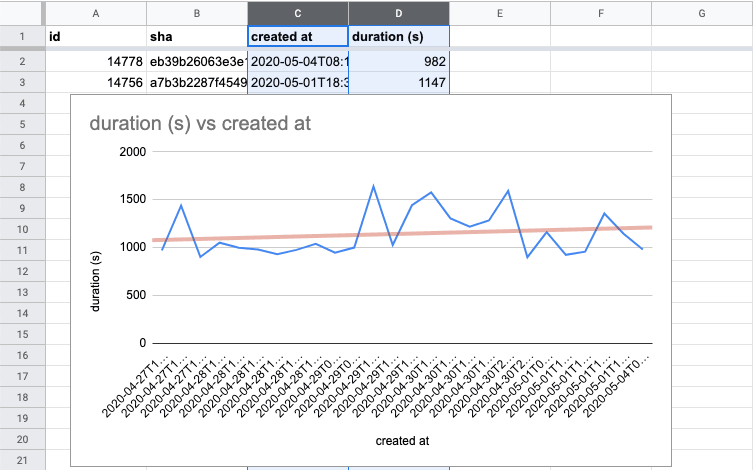
Finally, I can upload my CSV export to Google Sheets and plot the information I need.
Conclusion
Chisel is still at its earliest stage of development and it is pretty much tailored on my specific use case but if you see this tool can be useful to you too, please head to the Github repo and suggest the improvements you’d like to see.
If you liked this post and want to know more about Chisel, follow me on Twitter!
Featured image by Dominik Scythe on Unsplash
The post How I used Chisel to pull Gitlab pipelines stats appeared first on Alessandro Diaferia.


















