Hey dear developer! Welcome to the first chapter of My journey of building Skott, an open-source Node.js library, a little series in which I'll talk about different steps I've been through building the Skott project.
Before diving into the subject of today, here is the blog post introducing the project which is not mandatory to read to make this article valuable though, but it can help providing some background.
Ok without further ado, let's talk about the topic of the day: building a static analysis tool.
What is a Static Analysis?
A Static Analysis represents the process of analyzing the source code without running the application. You probably know many tools leveraging Static Analysis behind the scenes for example:
Linters are a set of tools fully leveraging Static Analyzes to flag programming errors, bugs, stylistic errors and suspicious constructs without having to run the code.

As you can see on the image above, ESLint is able to detect unused variables and flag them as errors (according to the provided configuration).
How does the Static Analysis work behind the scenes?
The answer to that question will be done in three steps:
1. What is a Parser
2. What is an Abstract Syntax Tree
3. How to use an Abstract Syntax Tree
Building static analysis tools is not a trivial task, so we'll only scratch the surface here, but you should have some basics to go further if you want!
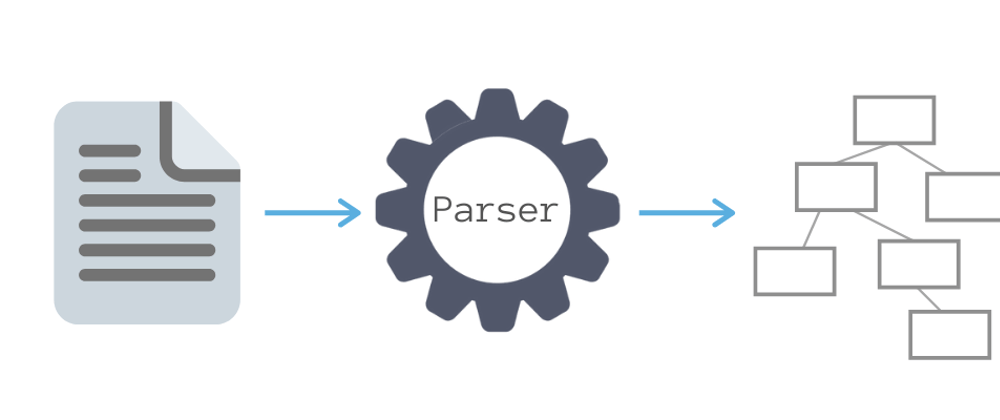
1. What is a Parser
A Parser is a program generating an intermediary data structure from an input string. Parsing is a is most typically done in two phases:
- Lexical Analysis (also known as Lexer, Tokenizer)
The goal of this tokenization phase is to generate tokens from the input program, which is only a raw string at this point (any programming language file in fact, .js, .rs, .go, .py, etc).
Tokens are a collection of characters allowing to describe pieces of code.
- Syntactic Analysis
Following the tokenization, the Syntactic Analysis takes produced tokens and generates an intermediary data structure describing precisely these tokens and their relationships. Spoiler: this intermediary data structure is most of the time an Abstract Syntax Tree (AST).
Here is a schema of a common parsing process:

2. What is an Abstract Syntax Tree
As already said in the previous section, an Abstract Syntax Tree is one of the data structure that can be generated while parsing source code (other structures can be used instead such as Concrete Syntax Trees depending on the use case).
The goal of this intermediate representation is to have a standardized way of representing the code that is easy to work with (but without any loss of information).
The most important keyword here is probably standardized, which is one of the main characteristics an AST should respect to be useful. As the AST is an intermediary data structure, the overall goal is to be able to transform the tree to anything we want for example transform the tree to produce a program in an entirely new language e.g. generating JavaScript from Scala or most commonly JavaScript from TypeScript, etc 😎

To allow that, each ecosystem/language has strict specifications describing what should be the standard shape of its own Abstract Syntax Tree. For the JavaScript language, this is the ESTree spec. This standardized format has the advantage of allowing any type of Parser (written using any programming language) to produce a common AST (following the ESTree spec) that can be then interpreted by any Interpreter (written in any language).
3. How to use an Abstract Syntax Tree
Generally speaking for compilers, an Abstract Syntax Tree is as I said multiple times an intermediary data structure which can be then transformed to produce byte code or any other source target e.g. TypeScript emits JavaScript using its own AST.

Nevertheless in the context of a Static Analysis, an Abstract Syntax Tree will most likely represent our final data structure needed as it will allow us to inspect the source code patterns directly from it (no need further transformations that a compiler would do).
By using the spec describing the shape of the AST, we're able (as Static Analysis tools developers) to rely on it to determine whatever static rule/condition, it's just a matter of finding data structure combinations.
To explore a little bit further the structure of ASTs for various languages, I like a lot AST Explorer
Let's wrap it up by example
To demonstrate a little Static Analysis tool in action, I'll show one use case of Skott, a library that builds a Directed Graph of relationships between files of a Node.js project.
If you are not fully sure of the purpose of Directed Graphs, you can check series I wrote on the topic here
To build that Directed Graph, Skott has to:
1. Use the entrypoint of the project and parse it
2. Statically find imports/exports statements of the entrypoint from the AST
3. Recursively follow imported/exported files and keep doing it until all files have been discovered
Let's do this.
1. Use the entrypoint of the project and parse it
index.js
import { runMain } from "./program.js";
import { makeDependencies } from "./dependencies.js";
// do something with runMain and makeDependencies
Once we read the entrypoint file, we can use Skott to extract import statements (here is above a simplified snippet from the Skott's codebase):

At line 3, we import parseScript from meriyah which is a JavaScript parser (could have been babel, acorn, swc, etc doesn't matter for our use case as long as they correctly implement the spec).
After that, we can parse the file content that will return us the root node of the Abstract Syntax Tree. Once the AST is generated by meriyah, the only thing left to do is to traverse the whole tree recursively and find the import statements.
To simplify the example, we only track ECMAScript modules here, but Skott also tries to deal with CommonJS modules.
How to find an import statement from within the AST?
Okay so now you might wonder how we can use the AST data structure to find import statements 🧐
Let's first take a look at the ESTree spec for es2015 to see how an import statement is represented in the AST:

Well, pretty simple!
Anytime we meet a node with type === "ImportDeclaration" we know that's an import statement.
So here's the function to detect if an AST node is a es2015 import statement:

Great, we're now able to find all import statements from any JavaScript file! Using the AST we could also get back information about where the import is located in the file and make it red highlighted in vscode for instance (but I'll let that vscode thing for 2023).
Thanks to our wonderful Skott performing Static Analysis, we're now able to generate and display the graph from all collected imports:
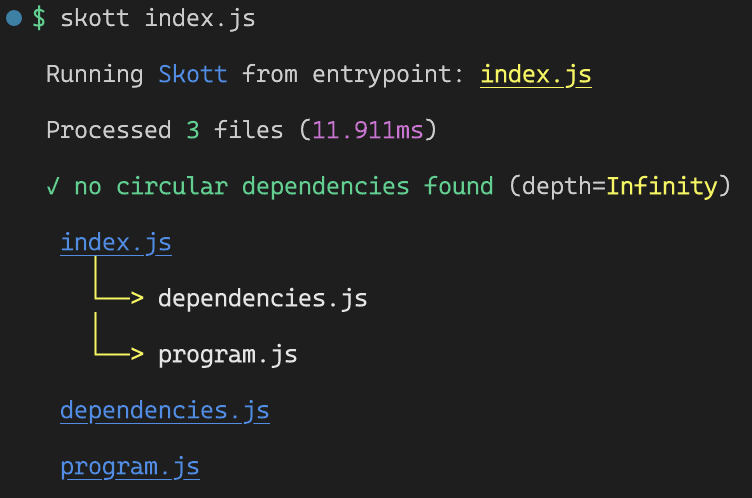
As we can see, three nodes have been found (the only three files of the sample project) and dependencies have been established between index.js and its two children being imported!
Conclusion
If you made it this far, thanks, I appreciate it :) But it also means that you've probably understood foundations about Parsers and Abstract Syntax Trees and that's even nicer!
Be sure to follow me if you're interested in discovering other topics I've covered throughout the journey of building Skott 💥
For the next episode of this series, I'm planning to talk about Test-Driven Development & Dependency Injection.
Last but not least don't hesitate to bring stars ⭐️, issues, feedbacks directly on GitHub here as it will allow me to drive the project where it will bring the most value for each developer.
Wish everyone a wonderful day ☀️


















