
[ UPDATED 23/03/2024 ]
PrivateGPT is a production-ready AI project that allows you to ask questions about your documents using the power of Large Language Models (LLMs), even in scenarios without an Internet connection. 100% private, no data leaves your execution environment at any point.
Running it on Windows Subsystem for Linux (WSL) with GPU support can significantly enhance its performance. In this guide, I will walk you through the step-by-step process of installing PrivateGPT on WSL with GPU acceleration.
Installing this was a pain in the a** and took me 2 days to get it to work. Hope this can help you on your own journey… Good luck !
Prerequisites
Before we begin, make sure you have the latest version of Ubuntu WSL installed. You can choose from versions such as Ubuntu-22–04–3 LTS or Ubuntu-22–04–6 LTS available on the Windows Store.
Updating Ubuntu
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install build-essential
ℹ️ “upgrade” is very important as python stuff will explode later if you don’t
Cloning the PrivateGPT repo
git clone https://github.com/imartinez/privateGPT
Setting Up Python Environment
To manage Python versions, we’ll use pyenv. Follow the commands below to install it and set up the Python environment:
sudo apt-get install git gcc make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev zlib1g-dev libncursesw5-dev libgdbm-dev libc6-dev zlib1g-dev libsqlite3-dev tk-dev libssl-dev openssl libffi-dev
curl https://pyenv.run | bash
export PATH="/home/$(whoami)/.pyenv/bin:$PATH"
Add the following lines to your .bashrc file:
export PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
Reload your terminal
source ~/.bashrc
Install important missing pyenv stuff
sudo apt-get install lzma
sudo apt-get install liblzma-dev
Install Python 3.11 and set it as the global version:
pyenv install 3.11
pyenv global 3.11
pip install pip --upgrade
pyenv local 3.11
Poetry Installation
Install poetry to manage dependencies:
curl -sSL https://install.python-poetry.org | python3 -
Add the following line to your .bashrc:
export PATH="/home/<YOU USERNAME>/.local/bin:$PATH"
ℹ️ Replace by your WSL username ($ whoami)
Reload your configuration
source ~/.bashrc
poetry --version # should display something without errors
Installing PrivateGPT Dependencies
Navigate to the PrivateGPT directory and install dependencies:
cd privateGPT
poetry install --extras "ui embeddings-huggingface llms-llama-cpp vector-stores-qdrant"
In need of a free and open-source Multi-Agents framework built for running local LLMs?
Nvidia Drivers Installation
Visit Nvidia’s official website to download and install the Nvidia drivers for WSL. Choose Linux > x86_64 > WSL-Ubuntu > 2.0 > deb (network)
Follow the instructions provided on the page.
Add the following lines to your .bashrc:
export PATH="/usr/local/cuda-12.4/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH"
ℹ️ Maybe check the content of “/usr/local” to be sure that you do have the “cuda-12.4” folder. Yours might have a different version.
Reload your configuration and check that all is working as expected
source ~/.bashrc
nvcc --version
nvidia-smi.exe
ℹ️ “nvidia-smi” isn’t available on WSL so just verify that the .exe one detects your hardware. Both commands should displayed gibberish but no apparent errors.
Building and Running PrivateGPT
Finally, install LLAMA CUDA libraries and Python bindings:
CMAKE_ARGS='-DLLAMA_CUBLAS=on' poetry run pip install --force-reinstall --no-cache-dir llama-cpp-python
Let private GPT download a local LLM for you (mixtral by default):
poetry run python scripts/setup
To run PrivateGPT, use the following command:
make run
This will initialize and boot PrivateGPT with GPU support on your WSL environment.
ℹ️ You should see “blas = 1” if GPU offload is working.
...............................................................................................
llama_new_context_with_model: n_ctx = 3900
llama_new_context_with_model: freq_base = 1000000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CUDA0 KV buffer size = 487.50 MiB
llama_new_context_with_model: KV self size = 487.50 MiB, K (f16): 243.75 MiB, V (f16): 243.75 MiB
llama_new_context_with_model: graph splits (measure): 3
llama_new_context_with_model: CUDA0 compute buffer size = 275.37 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 15.62 MiB
AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
18:50:50.097 [INFO ] private_gpt.components.embedding.embedding_component - Initializing the embedding model in mode=local
ℹ️ Go to 127.0.0.1:8001 in your browser
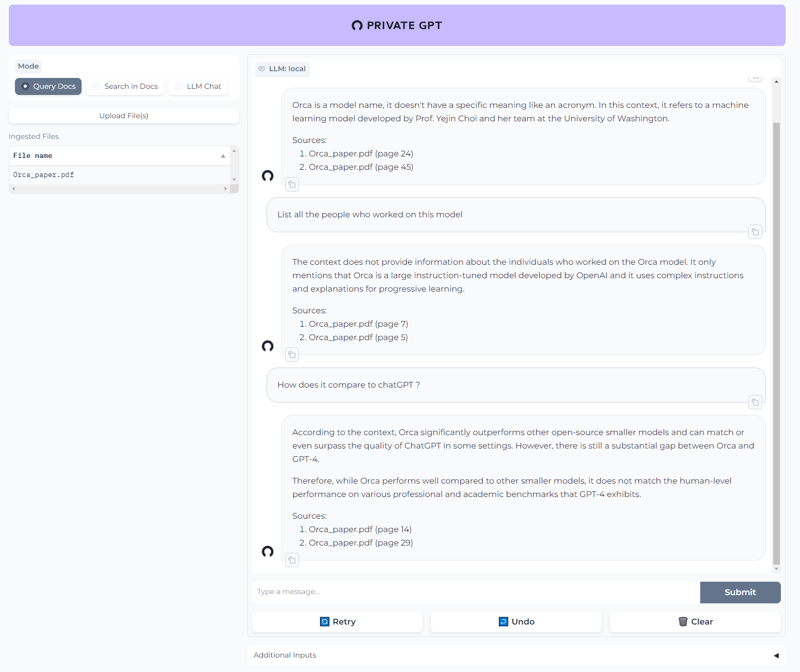
Uploaded the Orca paper and asking random stuff about it.
Conclusion
By following these steps, you have successfully installed PrivateGPT on WSL with GPU support. Enjoy the enhanced capabilities of PrivateGPT for your natural language processing tasks.
If something went wrong then open your window and throw your computer away. Then start again at step 1.
You can also remove the WSL with:
wsl.exe --list -v
wsl --unregister <name of the wsl to remove>
If this article help you in any way consider giving it a like ! Thx
Troubleshooting
Having a crash when asking a question or doing make run ? Here are the issues I encountered and how I fixed them.
- Cuda error
CUDA error: the provided PTX was compiled with an unsupported toolchain.
current device: 0, in function ggml_cuda_op_flatten at /tmp/pip-install-3kkz0k8s/llama-cpp-python_a300768bdb3b475da1d2874192f22721/vendor/llama.cpp/ggml-cuda.cu:9119
cudaGetLastError()
GGML_ASSERT: /tmp/pip-install-3kkz0k8s/llama-cpp-python_a300768bdb3b475da1d2874192f22721/vendor/llama.cpp/ggml-cuda.cu:271: !"CUDA error"
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
make: *** [Makefile:36: run] Aborted
This one comes from downloading the latest CUDA stuff and your drivers are not up to date. So open the Nvidia "Geforce experience" app from Windows and upgrade to the latest version and then reboot.
- CPU only
If privateGPT still sets BLAS to 0 and runs on CPU only, try to close all WSL2 instances. Then reopen one and try again.
If it's still on CPU only then try rebooting your computer. This is not a joke… Unfortunatly.
A note on using LM Studio as backend
I tried to use the server of LMStudio as fake OpenAI backend. It does work but not very well. Need to do more tests on that and I’ll update here.
For now what I did is start the LMStudio server on the port 8002 and unchecked “Apply Prompt Formatting”.
On PrivateGPT I edited “settings-vllm.yaml” and updated “openai > api_base” to “http://localhost:8002/v1" and the model to “dolphin-2.7-mixtral-8x7b.Q5_K_M.gguf” which is the one I use in LMStudio. It’s displayed in LMStudio if your wondering.
Other authors you might like
the-rise-of-human-based-botnets-unconventional-threats-in-cyberspace


















