
Anomaly detection has quickly moved out of computer science theory into practical everyday use by data scientists. Now, it's an essential part of data cleaning and KPI reviews for many businesses across the world. Overall, it greatly increases the accuracy of predictive models and can help businesses identify and respond to anomalies quickly.
To help you get started with this dense subject today, we'll explore a 5-minute crash course on what anomaly detection is, why it's used, and some basic algorithms.
Here’s what we’ll cover today:
What is anomaly detection?
Anomaly detection is a mathematical process used by data scientists to detect abnormalities within supervised and unsupervised numerical data based on how different a data point is from its surrounding data points or from the standard deviation.
There are many different anomaly detection techniques, sometimes called outlier detection algorithms, that each have different criteria for outlier detection and are therefore used for different use cases. Anomaly detection is used across all the major data science technologies such as Python and Scikit-learn (SKlearn).
All forms of anomaly detection rely on first building an understanding of standard results, or normal instances, using time series data.
Time series data is essentially a collection of values of the same variable over a period of time. This does not typically mean constant or the same but rather changing in an expected way. Each technique uses different estimator criteria to form the benchmark.
Example: Ice cream sales
For example, an ice cream store may record a drop in sales during the winter months and a peak in sales during the summer months. This trend is consistent year after year and is therefore used as the expected standard.
Even though a drop in sales is a notable change compared to summer month sales, it's not an anomaly. However, the system would flag an anomaly if ice cream sales suddenly spiked 40% above normal during a winter month because that's outside of our expected sales behavior. This would allow the ice cream store to analyze why that anomaly occurred and make informed business decisions on how to increase sales again in the future.
Why is anomaly detection important?
Anomaly detection is an essential part of every modern machine-learning technique. It helps you build more adaptive regression systems, clean defects from classifier system training data, and remove anomalous data from supervised learning programs. This mathematical approach is especially useful for big data and data mining applications because it's nearly impossible for the human eye to notice outliers in data visualizations that feature several thousand data points.
Due to its diverse number of use cases, businesses from different sectors have all been implementing anomaly detection in their data strategies. For example, many companies have opted to use anomaly detection methods to track their key performance indicators (KPIs). This allows them to notice anomalous trends quicker on paper and be more agile in shifting real-world markets.
Anomaly detection has also been adopted by cybersecurity experts for advanced artificial intelligence-powered fraud detection and intrusion detection systems. These systems use advanced data analysis techniques to track and flag suspicious user behavior in real-time.
Basic anomaly detection algorithms
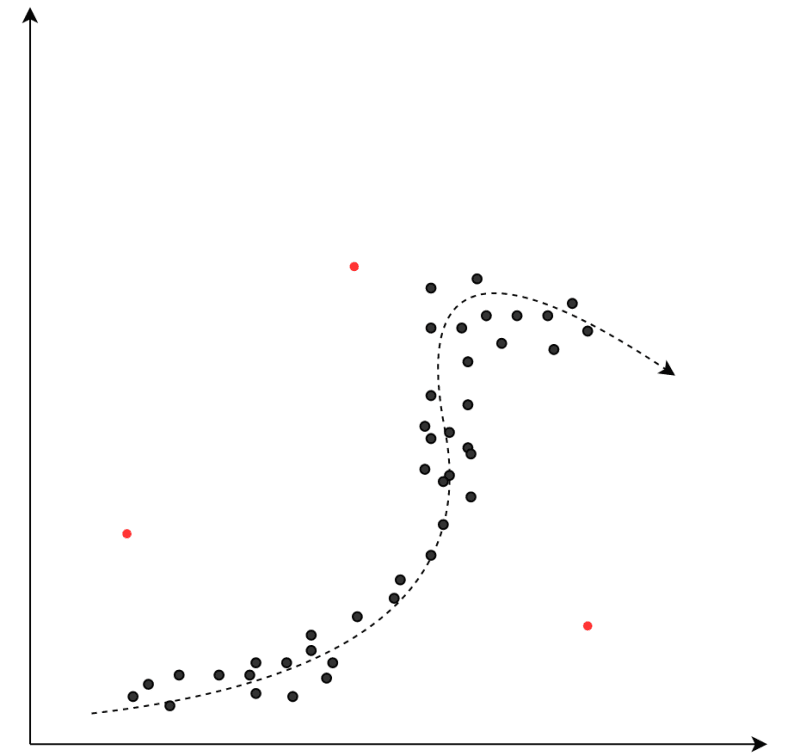
Density-based techniques
Density-based techniques encompass common techniques like K-Nearest Neighbor (KNN), Local Outlier Factor (LOF), Isolation Forests (similar to decision trees), and more. These techniques can be used for regression or classification systems.
Each of these algorithms generates an expected behavior by following the line of highest data point density. Any points that fall a statistically significant amount outside of these dense zones are flagged as an anomaly. Most of these techniques rely on distance between points, meaning it's essential to normalize the units and scale across the dataset to ensure accurate results.
For example, in a KNN system, data points are weighted by a value of 1/k, in which k is the distance to the data point's nearest neighbor. This means data points that are closer together are weighted heavily and therefore influence what's standard more than distant data points. The system then flags outliers by looking at points that have a low 1/k value.
Use Case
You have normalized, unlabeled data that you want to scan for anomalies, but you're not interested in algorithms with complex computations.
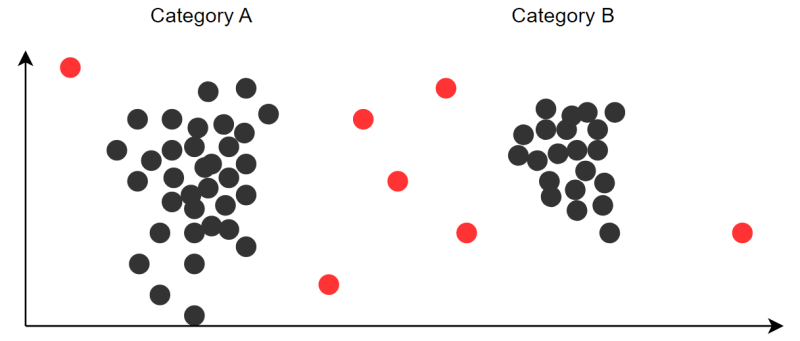
One-class support vector machine
The one-class support vector machine (one-class SVM) algorithm is a supervised learning model that produces a robust prediction model. It's mainly used for classification. The system uses a training set of examples, each marked as being part of one of two categories. The system then creates criteria with which to sort new examples into each category. The algorithm maps examples to points in space to maximize the differentiation between both categories.
The system flags an outlier if it falls too far out of either category's space. If you don't have labeled data, you can use an unsupervised learning approach that looks for clustering among examples to define categories.
Use Case
You have data that should mostly fit within two expected categories and want to find which data points lay outside of either category.
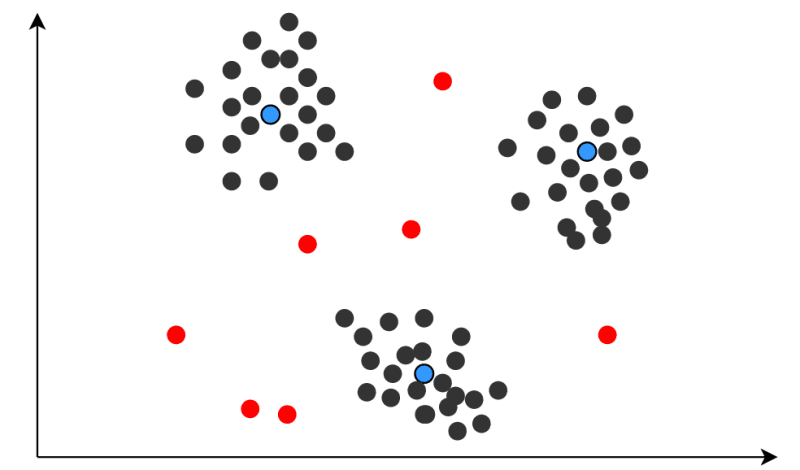
K-means clustering anomaly detection algorithm
The K-means clustering algorithm is a classification algorithm similar to KNN approaches because it relies on the closeness of each data point to other nearby points and is similar to SVM because it primarily focuses on classification into different categories.
Each data point is split into categories based on its features. Each category has a central point, or centroid, that serves as a prototype for all other data points within the cluster. Other points are then compared against these prototypes to determine their k-mean value, which essentially acts as a metric of difference between the prototype and the current data point. Higher k-mean data points are mapped closer to the prototype, creating a cluster.
K-means clustering can detect anomalies by flagging points that do not closely align with any of the established categories.
Use Case
You have unlabeled data composed of many different types of data that you want to organize by likeness to learned prototypes.
Algorithms to learn next
There are many other advanced algorithms out there, each with its own advantages. Some specialize in unsupervised anomaly detection, and others can measure multivariate data sets. As you continue your anomaly detection journey, check out these intermediate algorithms.
- Gaussian: An alternative version of the K-means algorithm that uses Gaussian distribution versus standard deviation.
- Bayesian: An alternative algorithm that leverages the Bayesian understanding of probability to detect anomalies.
- Autoencoders: A form of neural network that bounces expectations between input and output. The system uses the input to create encoded rules for expected output and vice versa. Any values that fall outside these recurring layers of analysis are flagged as anomalous. This learning algorithm is mainly used for anomaly detection problems of dimensionality.
To help you continue to develop your anomaly detection skills, Educative has created the course Simple Anomaly Detection using SQL. This brief course is the ideal crash course to get you hands-on with anomaly detection in just a few short lessons. With step-by-step directions through each step of the process, this course will walk you through building your first anomaly detection system using SQL. Complete this course for free using our 1-week free trial.
Happy learning!
Continue learning about machine learning and data science on Educative
- Deep learning vs. machine learning: Deep dive
- Data Science in 5 minutes: What is Data Cleaning?
- PyTorch tutorial: a quick guide for new learners
Start a discussion
What algorithms are your favorite to use? Was this article helpful? Let us know in the comments below!


















