While following through the Statistical Learning course, I came across this part on doing regression with boosting. Then reading through the material, and going through it makes me wonder, the same method may be adapted to Erik Bernhardsson's annoy algorithm.
Then I started to prototype again, but unlike my previous attempts (here and here), I am not interested in finding the nearest neighbours, so I did not reuse the code there. Instead I built a very rough proof-of-concept code with purely numpy code.
from functools import reduce
def distance(points, plane_normal, d):
return np.divide(np.add(d, np.sum(np.multiply(points, plane_normal), axis=1).reshape(-1,1)),
np.sqrt(np.sum(np.power(plane_normal, 2))))
def split_points(x):
idx = np.random.randint(x.shape[0], size=2)
points = x[idx,]
plane_normal = np.subtract(*points)
return split_points(x) if np.all(plane_normal == 0) else (points, plane_normal)
def tree_build(penalty, x, y):
points, plane_normal = split_points(x)
plane_point = np.divide(np.add(*points), 2)
d = 0 - np.sum(np.multiply(plane_normal, plane_point))
dist = distance(x, plane_normal, d)
return {'plane_normal': plane_normal,
'd': d,
'points': (y[dist >= 0].size, y[dist < 0].size),
'mean': (penalty * np.mean(y[dist >= 0]),
penalty * np.mean(y[dist < 0]))}
def boost_annoy(B, penalty, x, y):
return [tree_build(penalty, x, y) for b in range(B)]
def boost_annoy_transform(forest, x):
result = np.zeros((x.shape[0], 1))
for tree in forest:
dist = distance(x, tree['plane_normal'], tree['d'])
result = np.add(result, np.where(dist >= 0, tree['mean'][0], tree['mean'][1]))
return result
So the tree is built to somehow mirror the behavior of a boosting tree building algorithm, and hence it is somewhat limited by a penalty tuning parameter. Another parameter that affects the prediction is also taken from the boosting model, which is the number of trees, B. Also because this was meant to be a quick prototype, so I only branch out once.
Supplying these values to the model for training is shown as follows
x = np.random.normal(size=(1000, 10))
y = np.random.normal(size=(1000, 1))
forest = boost_annoy(B, 0.0001, x, y)
y_hat = boost_annoy_transform(forest, x)
While I don't have real world data to test, I tested by generating a bunch of random observations and responses, then use scikit-learn's KFold utility function to run through a bunch of test with different values of B for observations in 10-dimensional space.
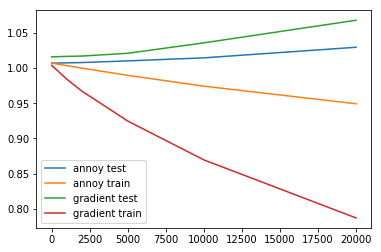
And the testing notebook is here.
As seen in the graph, while the training error of the algorithm does not go down as significantly as boosting's training error, the test error on the other hand is generally lower than boosting's test error. This is a rather interesting result for the first proof-of-concept type of prototype.
Of course there are a couple of things I need to fix, for instance proper branching (i.e. more than 1 level), some performance issues etc. However I am quite happy with the current result, hopefully I get to put in more time in making this into something proper.
postscript: Ah well, I screwed up a little bit on the sample generation lol, so in real life data it is a lot of work to be done, will see if I have time to do a proper follow up to this post.


















