Common sense says that application logging is a good thing. But common advice doesn’t answer questions like: what to log, when to log, or the format to log, which can get really frustrating especially if you’re looking for precise guidance on to structure your logs. Today, we’re going to change that.

After years of struggling to find a canonical this-is-how-you-should-log advice I came across a concept of: one-per-service logs. But be warned: It’s a heretical idea that challenges common logging advice. But after my own experiments with the one-per-service logging, I’ve found it to have considerable benefits.
By the end of this article you will understand what a one-per-service Phat Event log is and why they can be superior to regular log entries.
Before I get into the detail of what a one-per-service Phat Event log is and how they can improve our monitoring, let’s start by discussing old-school regular logging. Because if we start there we can start to see some of the difficulties you may run into when using a more traditional approach to application logging.
The Problem With Regular Logging
In order to start to dissect regular logging — and understand it’s difficulties — we should first define it. For the purposes of this article I’m pulling together a bunch of advice that you’ll see in different log related articles. Here are some of those common-sense approaches to application logging:
- Emit as much log data as you can (within reason).
- Emit log data wherever you think is necessary.
- Structure your logs in a machine readable format, like JSON.
- Group related log events together with a correlation ID.
- Emit log data using log levels to control the amount of emitted data.
That’s pretty much it: Log often, log frequently. Log. Log. Log.
And it’s pretty good advice. If you’ve got no real logging currently, then structuring your logs, like adding correlation ID’s and levels could start to make a big difference in your ability to understand your running application. But, as your application grows, some cracks will soon start to show.
What do I mean by cracks? Well, it’s these difficulties that I wanted to discuss upfront before we get to discussing Phat Event’s. And some of these difficulties are a little nuanced, so let’s take our time and go through some of the ways regular logging can start to fall apart…
There’s No Clear Pattern

Service Integration Logs
When it comes to regular structured logs, there’s no clear format for your structured log entries. Yes, there are some guidelines on what to include in a structured log. But the guidelines rarely go into the finer details necessary. Let me explain…
Imagine you have a service that makes a request out to another service. It’s logical thinking that you would want to log the input to the request, the output and any errors — right? It would be logical to think this as it will help you debug your service later. But here’s where the problem starts…
There’s no standard on how to log inputs and outputs from service integrations. What tends to happen is each software engineer logs the message in a way that makes sense for them, in their scenario. Before we know it we have 100 different patterns for logging service integration requests.
The problem of not having a pattern is two-fold. Firstly, it’s harder to search through multiple services if they’re all using different patterns as you’ll have to sit with the code open in on one screen, and logs on another. Not only that, but it also creates an unnecessary slow-down every time a developer has to implement these logs as they have to re-think everything again.
Regular Logs Are Hard to Test

Jest Test Output
Testing regular logs is hard. To test logs you’d typically spy on a log function and ensure that it’s called with the correct values that you expect. But these tests are fairly low value, whenever the code changes these tests are going to break. In the end most software engineers wouldn’t bother.
But, the problem with ignoring logs in tests will arrive when you rely on them for instrumentation such as dashboards, alerts, etc. Broken logs can then lead to broken instrumentation which might not be discovered until you really need it.
It’s Hard to Correlate Data
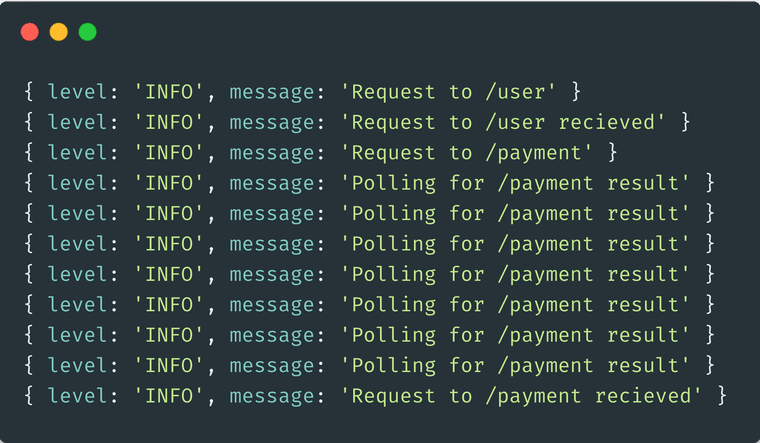
Example Log Entries
The difficulty with regular logs is that you have many lines of them it’s hard to correlate between log entries. At this point you might be wondering what I mean by correlate exactly? So let’s break it down with an example…
Imagine you’re getting integration failures between two services. And you suspect that the failures are only happening for a certain type of users. You think that the errors could be caused only by users in a given region but you want to test that idea.
To test your hypothesis (with regular log data you’d have to stitch together two log entries, both the log entry that emits user data and the log entry that records integration failures. And it’s the stitching together that can be hard. Simply having log data isn’t useful if you can’t easily query it.
The Solution: Phat Event Logs

So we know that having many log line entries can be a problem, they’re hard to standardise and hard to test.
And that’s where my investigation into Phat Events began. After experimenting with the idea in various services, I’ve found that one-per-service logs can start to address some of these issues we face with regular logging. Let’s start to understand the idea by having a look at the characteristics of this type of log.
One-per-service logs (Phat Events) can be defined as:
- One event per-service / per-request
- The event is structured (i.e JSON)
- The event can follow a schema
Of course, I appreciate our criteria is quite vague, so for the visual amongst you here is how that could look in a log entry:

Phat Event
At this point the eagle-eyed readers will be thinking: But that’s just the log output. What about the implementation? So let’s take a look at that now.
How Would You Implement A Phat Event?

Instrumenting With Phat Logs
Before we look at implementation I must say that the above syntax is using a library that I created called phat-event. This article is not intended as a sales pitch for phat-event. I want to talk instead about the generic merits of emitting large one-per-service events.
The concept of a large object emitting from a service is agnostic of library or language. The pattern would apply no matter what language you use. Generally the implementations I have used involve wrapping logic in a try/catch and emitting the log event on success or failure of the computation.
By this point hopefully you’re starting to get more of an idea about what a Phat Event is (a large, one-per-service log). But at the start of the article we did discuss the difficulties of regular logging, and I even made the bold claim that Phat Event’s could be the solution. So let’s take some time now to dig into the specifics of how Phat Events can improve your logging…
Phat Events Allow Us To Correlate Data
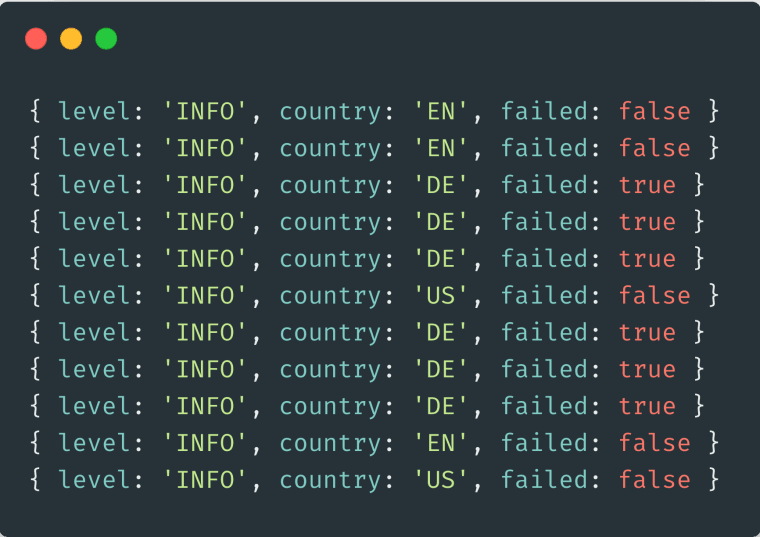
Let’s start with the greatest advantage of emitting large one-per-service logs: the ability to easily correlate data.
To take our previous example we discussed correlating between a user region and an integration for a service failing. With separate log entries we’d have to stitch these log entries back together to perform our calculation.
However, if we have all the log data grouped in a singe event the task becomes far easier. If we use the log output in the above image as an example, when we group by country we easilysee that an individual country contains 100% of the errors rates. This is vital information for debugging.
Phat Events Are Easier to Test

Asserting Phat Events
We talked before how regular logs are hard to test. The reason is that asserting that a function is receiving certain data only gives a small view of the full picture of a service. However, by emitting single one-per-service events things become a lot easier for testing.
Why? With Phat Events we’re calling our emit event only once. That means we only need (at a minimum) one test which says: given these service inputs, expect this logged output. One event is much easier to manage than many small function mocks. And it gives a full picture of the service.
And when we have a single event emitted it gives us an opportunity to sit down and consider that structured log event as a sort-of API. We can analyse the structure of the event, and understand whether it has all of the data that we’d need to operate our service. You don’t get this level of visibility with ad-hoc logging.
Phat Events Reduce Logging Noise

Log Lines To Phat Events
When we have many log events per request our log files get larger, and harder to manage. With a one-per-service log event we only have one entry per request. Which can drastically reduce the amount of log data that we’re storing.
Why the name phat-event?
Before I wrap up the article, I did say I’d explain the name phat-event. Whilst reading a lot about one-per-service events from Charity Majors, I saw her refer to the events as “phat”. The (I believe) tongue-in-check wording was pretty amusing and somewhat accurately described the nature of these log events.
Initialize the empty debugging event when the request enters the service. Stuff any and all interesting details while executing into that event. Ship your Phat Event off right before you exit or error the service. (Catch alll the signals.)
— Charity Majors (@mipsytipsy) September 21, 2018
Naming things is hard, and so we have the name: phat-event.
I would also like to extend attribution to Charity as she was the reason that started me pondering the idea which lead to my own experimentation. But despite being inspired, I was short on details. I’m hoping over the coming weeks, month & years I can start to add some detail and share with you more about the idea of large one-per-service log events.
Why Not Give Phat-Events a Go
Before we wrap up I’d like to add: using log events are not a silver bullet.
With log events you still have to think hard about the structure itself and what goes in the log event. And you still have to be diligent instrumenting your application. And whilst having single events makes it easier to enforce schemas, no official schema exists at this point (that I’m aware of).
But I do hope that I’ve given you some more insight into what Phat Events, or one-per-service events are, why they are important and why you might want to consider using them in your application. I’ll be following up in the future with more information on the concept and diving deeper into the topic.
If you’re interested in the concept, give it a go, let me know what other libraries you find, the difficulties you have and the (hopefully) jubilation you feel when you’ve got a service that is far easier to monitor than before.
The post You’re Logging Wrong: What One-Per-Service (“Phat Event”) Logs Are and Why You Need Them. appeared first on The Dev Coach.
Lou is the editor of The Cloud Native Software Engineering Newsletter a Newsletter dedicated to making Cloud Software Engineering easier, every 2 weeks you get news and articles that cover the fundamental topics of Cloud Native in your inbox.


















