Before starting, the odds that at least some of you had run into some issues within pagination are pretty high, so we’d love to hear your experiences and solutions!
Now, pagination is undoubtedly complex, though there are silver linings to its complexity. Primarily, the fundamentals of pagination usually fall into four broad categories, which will be examined along with a practical example and code in Python.
Let’s start!
What is pagination in web design?
Most websites contain huge amounts of data to the point where displaying all of it on a page becomes impossible. Even if it's a small data set, all the records make the page massive. The solution is to show limited records per page and provide access to the remaining records by using pagination.
Within pagination in web design, a user interface component, often known as a pager, is placed at the bottom of the page. This pager can contain the links or buttons to move the next page, previous page, last page, first page, or a specific page, although The actual implementation varies with every site.
Types of pagination
Even though each website has its way of using pagination, most of these pagination implementations fall into one of these four categories:
With Next button
Page Numbers without Next button
Pagination with infinite scroll
Pagination with Load More
In this article, we will examine these scenarios while scraping web data.
Pagination with a Next link
Let’s start with a simple example. Head over to the Books to Scrape web page. Scroll down to the bottom of the page and notice the pagination:
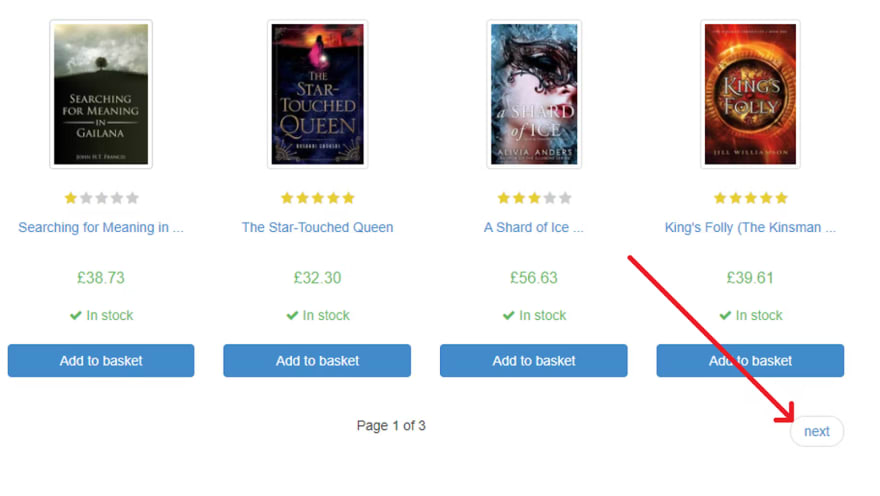
This site has the Next button. If this button is clicked, the browser loads the next page.

Note that now this site displays a previous button along with a Next button. If we keep clicking Next until the last page is reached, this is how it looks:

Moreover, with every click, the URL changes:
- Page 1 –
http://books.toscrape.com/catalogue/category/books/fantasy_19/index.html
- Page 2 –
http://books.toscrape.com/catalogue/category/books/fantasy_19/page-2.html
- Page 3 –
http://books.toscrape.com/catalogue/category/books/fantasy_19/pag
-3.html
The next step is to inspect the HTML markup of the next link. This could be done by pressing F12, or Ctrl+Alt+I, or by right-clicking the Next link and selecting Inspect.

In the Inspect window, it can be seen that the Next button is an anchor element and we can find the URL of the next page by looking for it.
Python code to handle pagination
Let’s start with writing a basic web scraper.
First, prepare your environment with the required packages. Open the terminal, activate the virtual environment (optional), and execute this command to install requests, beautifulsoup4 and lxml. The requests will be used for HTTP requests, the beautifulsoup4 will be used for locating the Next button in the HTML while the lxml is the back-end for beautifulsoup4.
pip install requests beautifulsoup4 lxml
Initially, write a simple code that fetches the first page and prints the footer. Note that we are printing the footer so that we can keep track of the page that is being parsed. In a real-world application, you would replace it with a proper logging and tracking solution, or forgo having visibility for performance reasons.
"""Handling pages with the Next button"""
import requests
from bs4 import BeautifulSoup
url = 'http://books.toscrape.com/catalogue/category/books/fantasy_19/index.html
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
footer_element = soup.select_one('li.current')
print(footer_element.text.strip())
The output of this code will be simply the footer of the first page:
Page 1 of 3
Few points to note here are as follows:
requests library is sending a GET request to the specified URL;
The soup object is being queried using CSS Selector. This CSS selector is website-specific.
Let’s modify this code to locate the Next button.
next_page_element = soup.select_one('li.next > a')
If the next_page_element is found, we can get the value of the href attribute, which holds the URL of the next page. One important thing to note here is that often the href will be a relative url. In such cases, one can use urljoin method from urllib.parse module to make the URL into an absolute one.
By wrapping the code that scrapes a single page with a while loop and the termination condition being the lack of any more pages, we can reach all pages linked to by pagination.
"""Handling pages with the Next button"""
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
url = 'http://books.toscrape.com/catalogue/category/books/fantasy_19/index.html
while True:
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
footer_element = soup.select_one('li.current')
print(footer_element.text.strip())
# Do more with each page.
# Find the next page to scrape in the pagination.
next_page_element = soup.select_one('li.next > a')
if next_page_element:
next_page_url = next_page_element.get('href')
url = urljoin(url, next_page_url)
else:
break
The output of this code will be the footer of all three pages:
Page 1 of 3
Page 2 of 3
Page 3 of 3
Pagination without Next button
Some websites will not show the Next button, but just page numbers. For example, here is an example of the pagination from
https://www.gosc.pl/doc/791526.Zaloz-zbroje.
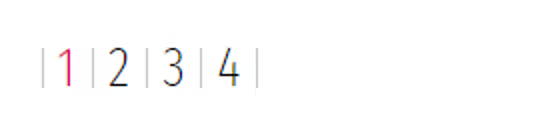
If we examine the HTML markup for this page, something interesting can be seen:
<span class="pgr_nrs">
<span>1</span>
<a href="/doc/791526.Zaloz-zbroje/2">2</a>
<a href="/doc/791526.Zaloz-zbroje/3">3</a>
<a href="/doc/791526.Zaloz-zbroje/4">4</a>
</span>
The HTML contains the links to all of the following pages. This makes visiting all these pages easy. The first step is to get to the first page. Next, we can use BeautifulSoup to extract all these links to other pages. Finally, we can write a for loop that scrapes all these links:
"""Handling pages without the Next button"""
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
# Get the first page.
url = 'https://www.gosc.pl/doc/791526.Zaloz-zbroje
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
page_link_el = soup.select('.pgr_nrs a')
# Do more with the first page.
# Make links for and process the following pages.
for link_el in page_link_el:
link = urljoin(url, link_el.get('href'))
response = requests.get(link)
soup = BeautifulSoup(response.text, 'lxml')
print(response.url)
# Do more with each page.
Pagination with infinite scroll
This kind of pagination does not show page numbers or the next button.
Let’s take the Quotes to Scrape website as an example. This site shows a limited number of quotes when the page loads. As you scroll down, it dynamically loads more items, a limited number at a time. Do note that the URL does not change as more pages are loaded.
In such cases, websites use an asynchronous call to an API to get more content and show this content on the page using JavaScript. The actual data returned by the API can be HTML or JSON.
Handling sites with JSON response
Before you load the site, press F12 to open Developer Tools, head over to the Network tab, and select XHR. Now go to
http://quotes.toscrape.com/scroll
and monitor the traffic. Scroll down to load more content.
You will notice that as you scroll down, more requests are sent to quotes?page=x, where x is the page number.

As the number of pages is not known beforehand, you have to figure out when to stop scraping. This is where has_next in the response from quotes?page=x is going to be useful.
We can write a while loop as we did in the previous section. This time, there is no need for BeautifulSoup because the response is JSON and we can parse it directly with json. Following is the code for the web scraper:
import requests
url = 'http://quotes.toscrape.com/api/quotes?page={}'
page_number = 1
while True:
response = requests.get(url.format(page_number))
# Do more with each page.
data = response.json()
print(response.url)
if data.get('has_next'):
page_number += 1
else:
Break
Once we can use the information that even the browser uses to handle pagination, replicating it ourselves for web scraping is quite easy.
Handling sites with HTML response
Previously we looked at JSON responses to figure out when to stop scraping. The example had a clear indication of when the last page was reached. Unfortunately, some websites do not provide structured responses and/or indications when there are no more pages to scrape, so you’d have to do more work to extract meaning from what is available. The next example is of a website that requires some creativity to properly handle its pagination.
Open Developer Tools by pressing F12 in your browser, go to the Network tab and then select XHR. Navigate to
https://techinstr.myshopify.com/collections/all.
You will notice that initially 8 products are loaded.
If we scroll down, the next 8 products are loaded. Also, notice the following:
The total number of products is 132.
The URL of the index page is different from the remaining pages.
The response is HTML, with no clear way to identify when to stop.

To handle pagination for this site, we will first load the index page and extract the number of products. We have already observed that 8 products are loaded in one request. With this data we can now calculate the number of pages as follows:
page_count = 132/8 = 16.5
By using math.ceil function we will get the last page, which will give us 17. Note that if you use the round function, you may end up missing one page in some cases. For example, if there are 132 products and each request loads 5 products, it means that there are 132/5 = 26.4 pages. In practice, it would mean that we do have to check 27 pages. Using ceil function ensures that pages are always rounded up. In this example, math.ceil will return 27, while round will return 26.
In addition to not providing a clear stop condition, this website also requires you to make the requests after the first one while providing the relevant session data. Otherwise, it redirects back to the first page. In order to continue using the session data received from the first page, we will also need to reuse a session instead of creating a new one for each of the pages.
This is the complete web scraper code:
import math
import requests
from bs4 import BeautifulSoup
index_page = 'https://techinstr.myshopify.com/collections/all'
url = 'https://techinstr.myshopify.com/collections/all?page={}'
session = requests.session()
response = session.get(index_page)
soup = BeautifulSoup(response.text, "lxml")
count_element = soup.select_one('.filters-toolbar__product-count')
count_str = count_element.text.replace('products', '')
total_count = int(count_str)
# Do more with the first page.
page_count = math.ceil(total_count/8)
for page_number in range(2, page_count+1):
response = session.get(url.format(page_number))
soup = BeautifulSoup(response.text, "lxml")
first_product = soup.select_one('.product-card:nth-child(1) > a > span')
print(first_product.text.strip())
# Do more with each of the pages.
Pagination with Load More button
Load More works very similar to infinite scroll. The only difference is how loading the next page is triggered on the browser. Because we are not using a browser but a script, the only difference will be the analysis of the pagination, not the scraping itself.
Open
https://smarthistory.org/americas-before-1900/
with Developer Tools (F12) and click Load More in the page.
You will see that the response is in JSON format with an attribute remaining. The key observations are as follows:
Each request gets 12 results
The value of remaining decreases by 12 with every click of Load More
If we set the value page to 1 in the API URL, it gets the first page of the results
– https://smarthistory.org/wp-json/smthstapi/v1/objects?tag=938&page=1

In this case, the user agent also needs to be set for this to work correctly. The following code handles this kind of pagination in web scraping:
import math
import requests
from bs4 import BeautifulSoup
url = 'https://smarthistory.org/wp-json/smthstapi/v1/objects?tag=938&page={}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
}
page_number = 1
while True:
response = requests.get(url.format(page_number), headers=headers) data = response.json()
print(response.url)
# Do more with each page.
if data.get('remaining') and int(data.get('remaining')) > 0:page_number += 1
else:
break
Conclusion
In this article, we explored various examples of pagination in web scraping, and let’s be honest; it’s hard to say that the process was very easy. There can be many ways websites use to display pagination, although to understand how it works, it is essential to look at the HTML markup, as well as the network traffic using the Developer Tools. Do note that this tutorial examined four broad types of pagination and how to handle them; therefore, it should be rather helpful even if you encounter a new issue.


















