Você realmente precisa de um cache? A operação do sistema é tão demorada assim? Ou o problema são as dependências do sistema? Existem muitas justificativas para se usar um cache e com ele vem diversos benefícios e malefícios, então antes de dizer "Coloca um cache aí que resolve" analise a situação.
Benefícios
- Entrega rápida para as consultas realizadas (milisegundos)
- Diminui uso de CPU: por que recalcular a mesma coisa se posso servir o que já calculei.
Malefícios
- Invalidação de cache
- Invalidação de cache
- Invalidação de cache
- Arquitetura começa a ficar complexa
Sim, eu repeti "Invalidação de cache" três vezes, e poderia repetir mais umas vezes. Invalidar cache é difícil. Se eu invalido muito seguido, o cache deixa de ser efetivo. Se eu não invalido nunca, estou servindo dados ruins. Como isso depende do contexto do sistema não existe receita de bolo pra saber se o cache é bom ou ruim. Então o jeito é medir.
Se você tem um cache, você deve medir pelo menos a taxa de cache hit e cache miss. Se a taxa de cache miss for maior do que a de hits, então provavelmente esse cache não serve para muita coisa. Se o cache mistura diversos tipos de dados diferentes, meça por tipo de chave e não globalmente.
Básico

Talvez isso seja básico, mas não custa revisar. Na figura acima temos um cache com poucos objetos guardados. Cada objeto tem uma etiqueta A, B, C, e um tempo de vida ttl — nem todo o cache tem um ttl associado, por exemplo caches de cpu. Podemos recuperar um objeto de forma rápida utilizando a etiqueta adequada. Conforme a aplicação roda, outros objetos vão sendo adicionados até o momento em que o cache está cheio. E agora? o que e eu faço para adicionar outro objeto? E se o objeto for muito maior do que os outros?
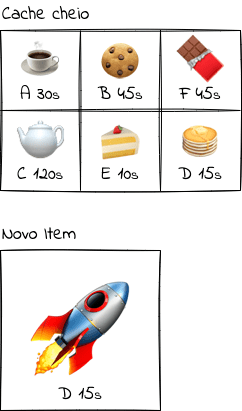
Nesse momento o comportamento do cache vai depender da implementação, existem diversas formas de lidar com esse momento — a Wikipedia lista 19 políticas diferentes. Saber como a biblioteca ou sistema de cache vai funcionar nessas situação é extremamente importante, pode ser o diferencial entre um cache sendo bem utilizado de um que não serve para nada.
Ainda há outras classes de problemas se o cache for distribuído, como o modelo de consistência que o cache utiliza, ou o fato de que duas instâncias da aplicação tentem atualizar uma mesma chave. Não tenho a pretensão de tentar explicar isso, mas é importante saber que esses problemas existem. O livro Designing Data-Intensive Applications explica todos esses detalhes de uma forma muito clara. Vale a leitura para os que querem conhecer mais sobre dados em sistemas distribuídos.
Ter ideia desses conceitos facilita muito na hora de discutirmos estratégias e melhorias nos sistemas. Evitamos que uma melhoria na verdade tenha um impacto negativo por uma má escolha de cache.
Usando caches
Seu time já entendeu as vantagens, desvantagens, diferenças da arquitetura e é hora de usar um cache, mas não conversamos sobre os dados que vamos armazenar lá. Será que existe alguma relação entre dados e cache? Será que o ciclo de vida dos dados tem alguma relação com o cache? Quais os impactos ao produto se servimos um conteúdo antigo?
Diferentes tipos de dados têm requisitos de caches diferentes. Para dados com um ciclo de vida muito curto não faz sentido colocar um tempo de vida extremamente alto. Agora, se o dado só é alterado poucas vezes na semana, um tempo de vida de um dia pode ser interessante — caso exista um volume de acesso que justifique isso, obviamente. Aqui temos que levar em conta os requisitos do produto. Em um sistema de bolsa de valores, exibir um conteúdo antigo pode significar uma perda de muito dinheiro. Entender a dinâmica do conteúdo servido é importante, até para definir se é necessário um mecanismo (bom o suficiente) de invalidação de cache.
Numa página web, com baixa taxa de alterações no HTML servido, você quer cachear o máximo possível nos servidores de borda e nos navegadores dos clientes. Por máximo possível entende-se o maior tempo que não gere impacto negativo ao negócio — seja por uma falha encontrada, ou porque às alterações tem que ser vistas de forma mais rápida. O negócio vai dizer o que fazer. E aqui, obviamente, entram custos: menos cache na borda significam mais requests em todo o backend e mais tráfego nos subsistemas — o impacto pode ser brutal dependendo da arquitetura.
Onde fica o cache?
Podemos ter diversos tipos de cache: dentro da aplicação, num sistema separado, ou ainda remoto no browser ou aplicativos dos clientes. Os caches ainda podem ser persistidos ou em memória. São muitas escolhas e muitos sistemas usam mais de um tipo. Mas independente de onde vamos deixar o cache, temos que lembrar de qual será o comportamento do sistema quando o cache estiver zerado, isto é o que acontece quando temos um cold cache.
Uma aplicação que utiliza um cache em memória dentro de cada instância vai perder essas informações quando uma reiniciar, ou fizermos um novo deploy. Será que isso afetará o sistema? Bem provável que sim. Se for um impacto pequeno, dentro do esperado pelo negócio, estamos bem. Caso contrário devemos estudar um outro método, ou rever a necessidade desse cache. Outro aspecto que surge num cache em memória dentro da aplicação é o sincronismo de dados: todas as instâncias possuem o mesmo valor para um determinada chave? Qual a percepção do usuário se apresentarmos diferentes dados? Um cache rodando num sistema separado pode resolver esse problema.
Não há bala de prata
Caches não resolvem tudo.
São uma ótima ferramenta, ajudam bastante a melhorar o desempenho do sistema. Te levam até um certo patamar de escalabilidade — que pode estar bem além da sua escala atual. Para ultrapassar essa barreira temos que repensar os sistemas, o modelo de dados, o consumo desses dados, os algoritmos utilizados. Só pense nessa barreira quando a hora chegar, não crie um sistema mais complexo do que a sua escala atual.


















