
Retrieval-augmented generation (RAG) integrates external information retrieval into the process of generating responses by Large Language Models (LLMs). It searches a database for information beyond its pre-trained knowledge base, significantly improving the accuracy and relevance of the generated responses.
Language models have exploded on the internet ever since ChatGPT came out, and rightfully so. They can write essays, code entire programs, and even make memes (though we’re still deciding on whether that's a good thing).
But as brilliant as these chatbots become, they still have limitations in tasks requiring external knowledge and factual information.
Yes, it can describe the honeybee's waggle dance in excruciating detail. But they become far more valuable if they can generate insights from any data that we provide, rather than just their original training data.
Since retraining those large language models from scratch costs millions of dollars and takes months, we need better ways to give our existing LLMs access to our custom data.
While you could be more creative with your prompts, it is only a short-term solution. LLMs can consider only a limited amount of text in their responses, known as a context window.
Some models like GPT-3 can see up to around 12 pages of text (that’s 4,096 tokens of context). That’s not good enough for most knowledge bases.
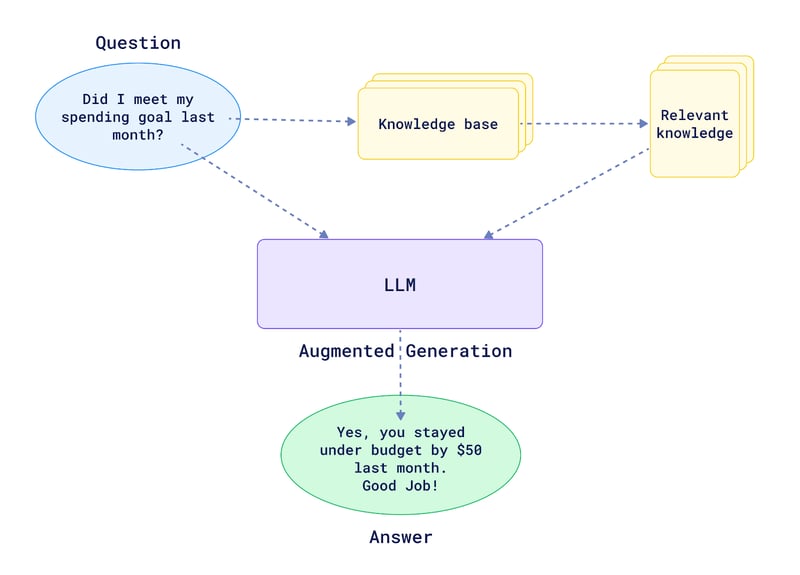
The image above shows how a basic RAG system works. Before forwarding the question to the LLM, we have a layer that searches our knowledge base for the "relevant knowledge" to answer the user query. Specifically, in this case, the spending data from the last month.
Our LLM can now generate a relevant non-hallucinated response about our budget.
As your data grows, you’ll need efficient ways to identify the most relevant information for your LLM's limited memory. This is where you’ll want a proper way to store and retrieve the specific data you’ll need for your query, without needing the LLM to remember it.
Vector databases store information as vector embeddings. This format supports efficient similarity searches to retrieve relevant data for your query. For example, Qdrant is specifically designed to perform fast, even in scenarios dealing with billions of vectors.
This article will focus on RAG systems and architecture. If you’re interested in learning more about vector search, we recommend the following articles: What is a Vector Database? and What are Vector Embeddings?.
RAG architecture
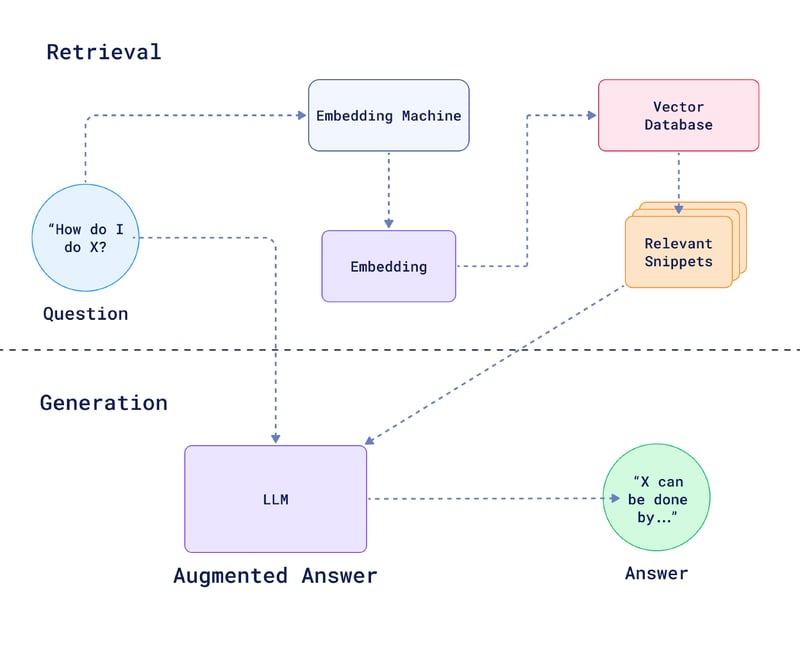
At its core, a RAG architecture includes the retriever and the generator. Let's start by understanding what each of these components does.
The Retriever
When you ask a question to the retriever, it uses similarity search to scan through a vast knowledge base of vector embeddings. It then pulls out the most relevant vectors to help answer that query. There are a few different techniques it can use to know what’s relevant:
How indexing works in RAG retrievers
The indexing process organizes the data into your vector database in a way that makes it easily searchable. This allows the RAG to access relevant information when responding to a query.
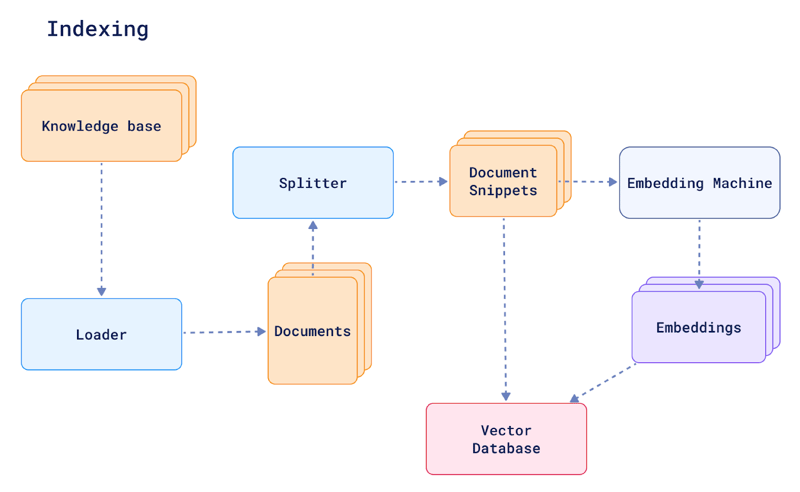
As shown in the image above, here’s the process:
- Start with a loader that gathers documents containing your data. These documents could be anything from articles and books to web pages and social media posts.
- Next, a splitter divides the documents into smaller chunks, typically sentences or paragraphs.
- This is because RAG models work better with smaller pieces of text. In the diagram, these are document snippets.
- Each text chunk is then fed into an embedding machine. This machine uses complex algorithms to convert the text into vector embeddings.
All the generated vector embeddings are stored in a knowledge base of indexed information. This supports efficient retrieval of similar pieces of information when needed.
Query vectorization
Once you have vectorized your knowledge base you can do the same to the user query. When the model sees a new query, it uses the same preprocessing and embedding techniques. This ensures that the query vector is compatible with the document vectors in the index.
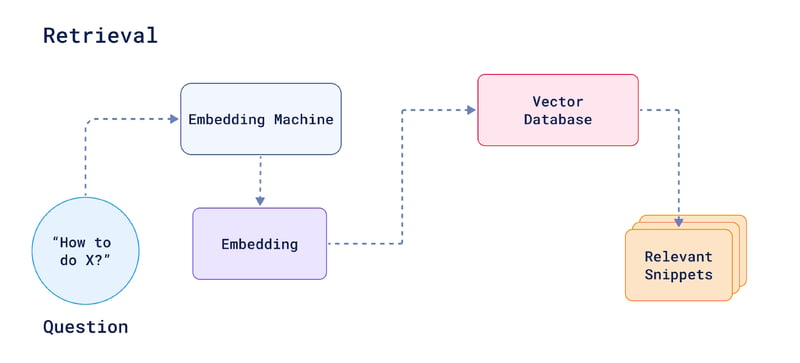
Retrieval of relevant documents
When the system needs to find the most relevant documents or passages to answer a query, it utilizes vector similarity techniques. Vector similarity is a fundamental concept in machine learning and natural language processing (NLP) that quantifies the resemblance between vectors, which are mathematical representations of data points.
The system can employ different vector similarity strategies depending on the type of vectors used to represent the data:
Sparse vector representations
A sparse vector is characterized by a high dimensionality, with most of its elements being zero.
The classic approach is keyword search, which scans documents for the exact words or phrases in the query. The search creates sparse vector representations of documents by counting word occurrences and inversely weighting common words. Queries with rarer words get prioritized.
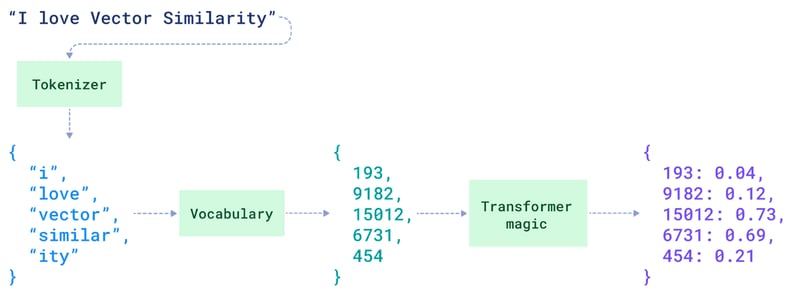
TF-IDF (Term Frequency-Inverse Document Frequency) and BM25 are two classic related algorithms. They're simple and computationally efficient. However, they can struggle with synonyms and don't always capture semantic similarities.
If you’re interested in going deeper, refer to our article on Sparse Vectors.
Dense vector embeddings
This approach uses large language models like BERT to encode the query and passages into dense vector embeddings. These models are compact numerical representations that capture semantic meaning. Vector databases like Qdrant store these embeddings, allowing retrieval based on semantic similarity rather than just keywords using distance metrics like cosine similarity.
This allows the retriever to match based on semantic understanding rather than just keywords. So if I ask about "compounds that cause BO," it can retrieve relevant info about "molecules that create body odor" even if those exact words weren't used. We explain more about it in our What are Vector Embeddings article.
Hybrid search
However, neither keyword search nor vector search are always perfect. Keyword search may miss relevant information expressed differently, while vector search can sometimes struggle with specificity or neglect important statistical word patterns. Hybrid methods aim to combine the strengths of different techniques.
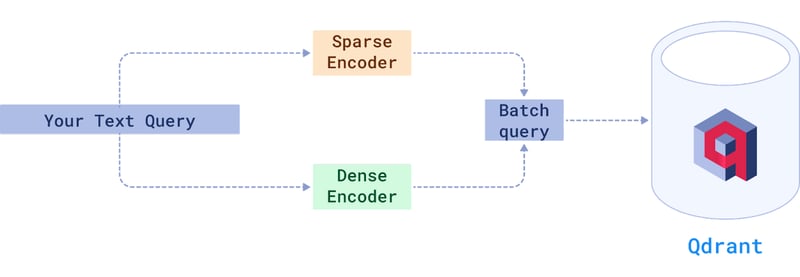
Some common hybrid approaches include:
- Using keyword search to get an initial set of candidate documents. Next, the documents are re-ranked/re-scored using semantic vector representations.
- Starting with semantic vectors to find generally topically relevant documents. Next, the documents are filtered/re-ranked e based on keyword matches or other metadata.
- Considering both semantic vector closeness and statistical keyword patterns/weights in a combined scoring model.
- Having multiple stages were different techniques. One example: start with an initial keyword retrieval, followed by semantic re-ranking, then a final re-ranking using even more complex models.
When you combine the powers of different search methods in a complementary way, you can provide higher quality, more comprehensive results. Check out our article on Hybrid Search if you’d like to learn more.
The Generator
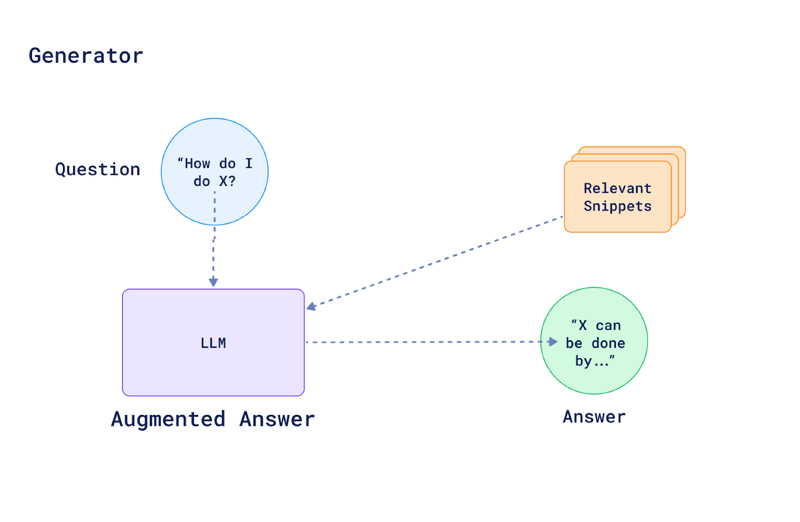
With the top relevant passages retrieved, it's now the generator's job to produce a final answer by synthesizing and expressing that information in natural language.
The LLM is typically a model like GPT, BART or T5, trained on massive datasets to understand and generate human-like text. It now takes not only the query (or question) as input but also the relevant documents or passages that the retriever identified as potentially containing the answer to generate its response.
The retriever and generator don't operate in isolation. The image bellow shows how the output of the retrieval feeds the generator to produce the final generated response.
Where is RAG being used?
Because of their more knowledgeable and contextual responses, we can find RAG models being applied in many areas today, especially those who need factual accuracy and knowledge depth.
Real-World Applications:
Question answering: This is perhaps the most prominent use case for RAG models. They power advanced question-answering systems that can retrieve relevant information from large knowledge bases and then generate fluent answers.
Language generation: RAG enables more factual and contextualized text generation for contextualized text summarization from multiple sources
Data-to-text generation: By retrieving relevant structured data, RAG models can generate product/business intelligence reports from databases or describing insights from data visualizations and charts
Multimedia understanding: RAG isn't limited to text - it can retrieve multimodal information like images, video, and audio to enhance understanding. Answering questions about images/videos by retrieving relevant textual context.
Creating your first RAG chatbot with Langchain, Groq, and OpenAI
Are you ready to create your own RAG chatbot from the ground up? We have a video explaining everything from the beginning. Daniel Romero’s will guide you through:
- Setting up your chatbot
- Preprocessing and organizing data for your chatbot's use
- Applying vector similarity search algorithms
- Enhancing the efficiency and response quality
After building your RAG chatbot, you'll be able to evaluate its performance against that of a chatbot powered solely by a Large Language Model (LLM).
What’s next?
Have a RAG project you want to bring to life? Join our Discord community where we’re always sharing tips and answering questions on vector search and retrieval.
Learn more about how to properly evaluate your RAG responses: Evaluating Retrieval Augmented Generation - a framework for assessment.


















