
In this guide, we'll explain how to scrape LinkedIn data - the most popular career-related social media platform out there.
We'll scrape LinkedIn information from search, job, company, and public profile pages. All of which through straightforward Python code along with a few parsing tips and tricks. Let's get started!
#Legal Disclaimer and Precautions
This tutorial covers popular web scraping techniques for education. Interacting with public servers requires diligence and respect and here's a good summary of what not to do:
- Do not scrape at rates that could damage the website.
- Do not scrape data that's not available publicly.
- Do not store PII of EU citizens who are protected by GDPR.
- Do not repurpose the entire public datasets which can be illegal in some countries.
Scrapfly does not offer legal advice but these are good general rules to follow in web scraping
and for more you should consult a lawyer.
Latest LinkedIn Scraper Code
Why Scrape LinkedIn?
Web scraping LinkedIn allows to extract valuable information for both businesses and individuals through different use cases.
- Market Research Market trends and qualifications are fast-changing. Hence, LinkedIn web scraping is beneficial for keeping up with these changes by extracting industry-related data from company or job pages.
- Personalized Job Research LinkedIn includes thousands of job listing posts across various domains. Scraping data from LinkedIn enables creating alerts for personalized job preferences while also aggregating this data to identify patterns, in-demand skills, and job requirements.
- Lead Generation Scraping LinkedIn data from company pages provides businesses with a wide range of opportunities by identifying potential leads with common interests. This lead data empowers decision-making and helps attract new clients.
For further details, have a look at our introduction to web scraping use cases.
Setup
In this LinkedIn data scraping guide, we'll use Python with a few web scraping tools:
- httpx: To request the LinkedIn pages and retrieve the data as HTML.
- parsel: To parse the retrieved HTML using XPath or CSS selectors for data extraction.
- JMESPath: To refine and parse the LinkedIn JSON datasets for the useful data only.
- loguru: To log and monitor our LinkedIn scraper tool using colored terminal outputs.
- asyncio: To increase our web scraping speed by executing the code asynchronously.
Note that asyncio is included with Python and to install the other packages we can use the following pip command:
pip install httpx parsel loguru
Alternatively, httpx can be replaced with any other HTTP client, such as requests. Another alternative to Parsel is the BeautifulSoup package.
How to Scrape LinkedIn Public Profile Pages?
In this section, we'll extract data from publicly available data on LinkedIn profiles. If we take a look at any LinkedIn profile page (like the one for Bill Gates) we can see loads of valuable public data:
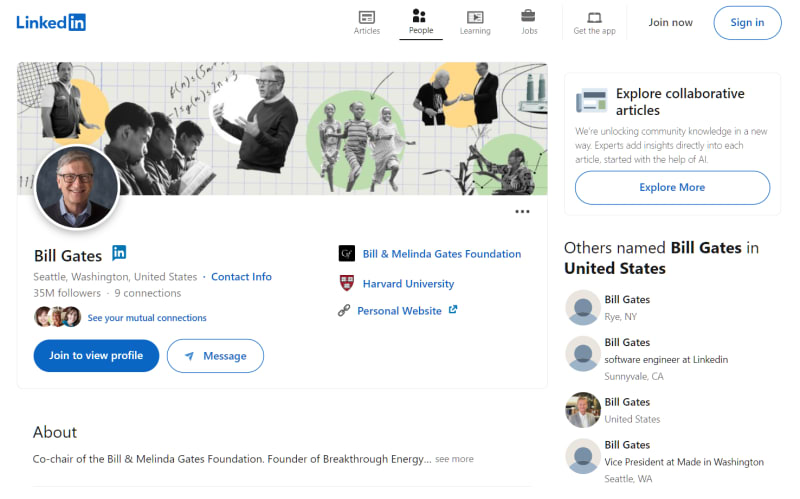
LinkedIn public profile page
To collect this data, we can manually parse each data point from the HTML or extract hidden web data.
To locate this hidden data, we can follow these steps:
- Open the browser developer tools by pressing the
F12key. - Search for the selector:
//script[@type='application/ld+json'].
This will lead to a script tag with the following details:

This gets us the core details available on the page, though a few fields like the job title are missing, as the page is viewed publicly. To scrape it, we'll extract the script and parse it.
Python:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def refine_profile(data: Dict) -> Dict:
"""refine and clean the parsed profile data"""
parsed_data = {}
profile_data = [key for key in data["@graph"] if key["@type"]=="Person"][0]
profile_data["worksFor"] = [profile_data["worksFor"][0]]
articles = [key for key in data["@graph"] if key["@type"]=="Article"]
for article in articles:
selector = Selector(article["articleBody"])
article["articleBody"] = "".join(selector.xpath("//p/text()").getall())
parsed_data["profile"] = profile_data
parsed_data["posts"] = articles
return parsed_data
def parse_profile(response: Response) -> Dict:
"""parse profile data from hidden script tags"""
assert response.status_code == 200, "request is blocked, use the ScrapFly codetabs"
selector = Selector(response.text)
data = json.loads(selector.xpath("//script[@type='application/ld+json']/text()").get())
refined_data = refine_profile(data)
return refined_data
async def scrape_profile(urls: List[str]) -> List[Dict]:
"""scrape public linkedin profile pages"""
to_scrape = [client.get(url) for url in urls]
data = []
# scrape the URLs concurrently
for response in asyncio.as_completed(to_scrape):
response = await response
profile_data = parse_profile(response)
data.append(profile_data)
log.success(f"scraped {len(data)} profiles from Linkedin")
return data
ScrapFly:
import json
from typing import Dict, List
from parsel import Selector
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass linkedin.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
"headers": {
"Accept-Language": "en-US,en;q=0.5"
}
}
def refine_profile(data: Dict) -> Dict:
"""refine and clean the parsed profile data"""
parsed_data = {}
profile_data = [key for key in data["@graph"] if key["@type"]=="Person"][0]
profile_data["worksFor"] = [profile_data["worksFor"][0]]
articles = [key for key in data["@graph"] if key["@type"]=="Article"]
for article in articles:
selector = Selector(article["articleBody"])
article["articleBody"] = "".join(selector.xpath("//p/text()").getall())
parsed_data["profile"] = profile_data
parsed_data["posts"] = articles
return parsed_data
def parse_profile(response: ScrapeApiResponse) -> Dict:
"""parse profile data from hidden script tags"""
selector = response.selector
data = json.loads(selector.xpath("//script[@type='application/ld+json']/text()").get())
refined_data = refine_profile(data)
return refined_data
async def scrape_profile(urls: List[str]) -> List[Dict]:
"""scrape public linkedin profile pages"""
to_scrape = [ScrapeConfig(url, **BASE_CONFIG) for url in urls]
data = []
# scrape the URLs concurrently
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
profile_data = parse_profile(response)
data.append(profile_data)
log.success(f"scraped {len(data)} profiles from Linkedin")
return data
Run the code:
async def run():
profile_data = await scrape_profile(
urls=[
"https://www.linkedin.com/in/williamhgates"
]
)
# save the data to a JSON file
with open("profile.json", "w", encoding="utf-8") as file:
json.dump(profile_data, file, indent=2, ensure_ascii=False)
if __name__ == " __main__":
asyncio.run(run())
In the above LinkedIn profile scraper, we define three functions. Let's break them down:
-
scrape_profile(): To request LinkedIn profile URLs concurrently and utilize the parsing logic to extract each profile data. -
parse_profile(): To parse thescripttag containing the profile data. -
refine_profile(): To refine and organize the extracted data.
Here's a sample output of the results we got:
[
{
"profile": {
"@type": "Person",
"address": {
"@type": "PostalAddress",
"addressLocality": "Seattle, Washington, United States",
"addressCountry": "US"
},
"alumniOf": [
{
"@type": "EducationalOrganization",
"name": "Harvard University",
"url": "https://www.linkedin.com/school/harvard-university/",
"member": {
"@type": "OrganizationRole",
"startDate": 1973,
"endDate": 1975
}
}
],
"awards": [],
"image": {
"@type": "ImageObject",
"contentUrl": "https://media.licdn.com/dms/image/D5603AQHv6LsdiUg1kw/profile-displayphoto-shrink_200_200/0/1695167344576?e=2147483647&v=beta&t=XAUf_Aqfa5tAmMqvOXPJ26wXV73tOHvI-rygpb_WpQA"
},
"jobTitle": [
" **-*****",
" *******",
" **-*******"
],
"name": "Bill Gates",
"sameAs": "https://www.linkedin.com/in/williamhgates",
"url": "https://www.linkedin.com/in/williamhgates",
"memberOf": [],
"worksFor": [
{
"@type": "Organization",
"name": "Bill & Melinda Gates Foundation",
"url": "https://www.linkedin.com/company/bill-&-melinda-gates-foundation",
"member": {
"@type": "OrganizationRole"
}
}
],
"knowsLanguage": [],
"disambiguatingDescription": "Top Voice",
"interactionStatistic": {
"@type": "InteractionCounter",
"interactionType": "https://schema.org/FollowAction",
"name": "Follows",
"userInteractionCount": 0
},
"description": "Co-chair of the Bill & Melinda Gates Foundation. Founder of Breakthrough Energy…"
},
"posts": [
{
"@type": "Article",
"name": "How to power a clean tomorrow",
"author": {
"@type": "Person",
"name": "Bill Gates",
"url": "https://www.linkedin.com/in/williamhgates"
},
"articleBody": "....",
"url": "https://www.linkedin.com/pulse/how-power-clean-tomorrow-bill-gates-ddckc"
},
....
]
}
]
With this scraper, we can successfully scrape public LinkedIn profiles. Next, let's explore how to scrape company data!
How to Scrape LinkedIn Company Pages?
LinkedIn company pages include various valuable data fields like the company's industry label, addresses, number of employees, jobs, and related company pages. Moreover, the company pages are public, meaning that we can scrape their full details!
Let's start by taking a look at a company profile page on LinkedIn such as Microsoft:
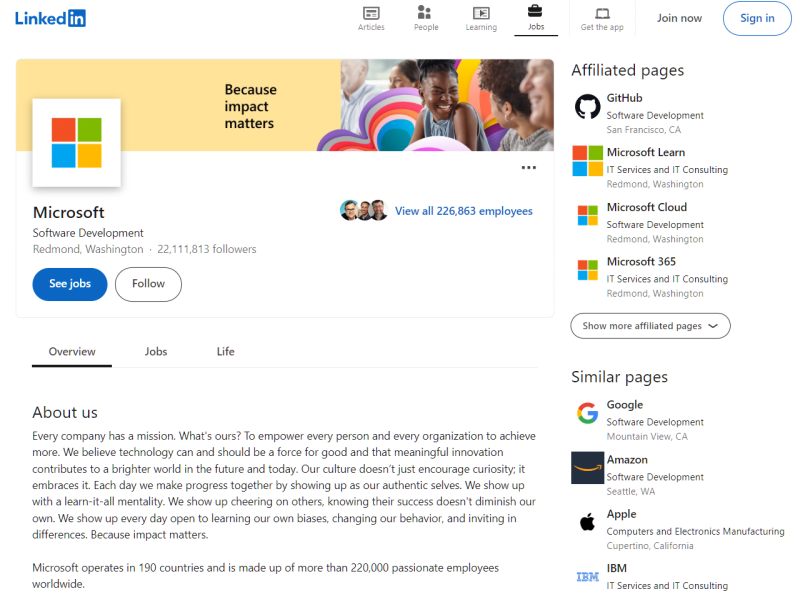
LinkedIn company page
Just like with people pages, the LinkedIn company page data can also be found in hidden script tags:

From the above image, we can see that the script tag doesn't contain the full company details. Therefore to extract the entire company dataset, we'll use a bit of HTML parsing as well.
Python:
import jmespath
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
follow_redirects=True
)
def strip_text(text):
"""remove extra spaces while handling None values"""
return text.strip() if text != None else text
def parse_company(response: Response) -> Dict:
"""parse company main overview page"""
assert response.status_code == 200, "request is blocked, use the ScrapFly codetabs"
selector = Selector(response.text)
script_data = json.loads(selector.xpath("//script[@type='application/ld+json']/text()").get())
script_data = jmespath.search(
"""{
name: name,
url: url,
mainAddress: address,
description: description,
numberOfEmployees: numberOfEmployees.value,
logo: logo
}""",
script_data
)
data = {}
for element in selector.xpath("//div[contains(@data-test-id, 'about-us')]"):
name = element.xpath(".//dt/text()").get().strip()
value = element.xpath(".//dd/text()").get().strip()
data[name] = value
addresses = []
for element in selector.xpath("//div[contains(@id, 'address') and @id != 'address-0']"):
address_lines = element.xpath(".//p/text()").getall()
address = ", ".join(line.replace("\n", "").strip() for line in address_lines)
addresses.append(address)
affiliated_pages = []
for element in selector.xpath("//section[@data-test-id='affiliated-pages']/div/div/ul/li"):
affiliated_pages.append({
"name": element.xpath(".//a/div/h3/text()").get().strip(),
"industry": strip_text(element.xpath(".//a/div/p[1]/text()").get()),
"address": strip_text(element.xpath(".//a/div/p[2]/text()").get()),
"linkeinUrl": element.xpath(".//a/@href").get().split("?")[0]
})
similar_pages = []
for element in selector.xpath("//section[@data-test-id='similar-pages']/div/div/ul/li"):
similar_pages.append({
"name": element.xpath(".//a/div/h3/text()").get().strip(),
"industry": strip_text(element.xpath(".//a/div/p[1]/text()").get()),
"address": strip_text(element.xpath(".//a/div/p[2]/text()").get()),
"linkeinUrl": element.xpath(".//a/@href").get().split("?")[0]
})
data = { **script_data,** data}
data["addresses"] = addresses
data["affiliatedPages"] = affiliated_pages
data["similarPages"] = similar_pages
return data
async def scrape_company(urls: List[str]) -> List[Dict]:
"""scrape prublic linkedin company pages"""
to_scrape = [client.get(url) for url in urls]
data = []
for response in asyncio.as_completed(to_scrape):
response = await response
data.append(parse_company(response))
log.success(f"scraped {len(data)} companies from Linkedin")
return data
ScrapFly
import json
import jmespath
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass linkedin.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
"headers": {
"Accept-Language": "en-US,en;q=0.5"
}
}
def strip_text(text):
"""remove extra spaces while handling None values"""
return text.strip() if text != None else text
def parse_company(response: ScrapeApiResponse) -> Dict:
"""parse company main overview page"""
selector = response.selector
script_data = json.loads(selector.xpath("//script[@type='application/ld+json']/text()").get())
script_data = jmespath.search(
"""{
name: name,
url: url,
mainAddress: address,
description: description,
numberOfEmployees: numberOfEmployees.value,
logo: logo
}""",
script_data
)
data = {}
for element in selector.xpath("//div[contains(@data-test-id, 'about-us')]"):
name = element.xpath(".//dt/text()").get().strip()
value = element.xpath(".//dd/text()").get().strip()
data[name] = value
addresses = []
for element in selector.xpath("//div[contains(@id, 'address') and @id != 'address-0']"):
address_lines = element.xpath(".//p/text()").getall()
address = ", ".join(line.replace("\n", "").strip() for line in address_lines)
addresses.append(address)
affiliated_pages = []
for element in selector.xpath("//section[@data-test-id='affiliated-pages']/div/div/ul/li"):
affiliated_pages.append({
"name": element.xpath(".//a/div/h3/text()").get().strip(),
"industry": strip_text(element.xpath(".//a/div/p[1]/text()").get()),
"address": strip_text(element.xpath(".//a/div/p[2]/text()").get()),
"linkeinUrl": element.xpath(".//a/@href").get().split("?")[0]
})
similar_pages = []
for element in selector.xpath("//section[@data-test-id='similar-pages']/div/div/ul/li"):
similar_pages.append({
"name": element.xpath(".//a/div/h3/text()").get().strip(),
"industry": strip_text(element.xpath(".//a/div/p[1]/text()").get()),
"address": strip_text(element.xpath(".//a/div/p[2]/text()").get()),
"linkeinUrl": element.xpath(".//a/@href").get().split("?")[0]
})
data = { **script_data,** data}
data["addresses"] = addresses
data["affiliatedPages"] = affiliated_pages
data["similarPages"] = similar_pages
return data
async def scrape_company(urls: List[str]) -> List[Dict]:
"""scrape prublic linkedin company pages"""
to_scrape = [ScrapeConfig(url, **BASE_CONFIG) for url in urls]
data = []
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
data.append(parse_company(response))
log.success(f"scraped {len(data)} companies from Linkedin")
return data
Run the code
async def run():
profile_data = await scrape_company(
urls=[
"https://linkedin.com/company/microsoft"
]
)
# save the data to a JSON file
with open("company.json", "w", encoding="utf-8") as file:
json.dump(profile_data, file, indent=2, ensure_ascii=False)
if __name__ == " __main__":
asyncio.run(run())
In the above LinkedIn scraping code, we define two functions. Let's break them down:
-
parse_company(): To parse the company data fromscripttags while using JMESPath to refine it and parse other HTML elements using XPath selectors. -
scrape_company(): To request the company page URLs while utilizing the parsing logic.
Here's an example output of the scraped data we got:
[
{
"name": "Microsoft",
"url": "https://www.linkedin.com/company/microsoft",
"mainAddress": {
"type": "PostalAddress",
"streetAddress": "1 Microsoft Way",
"addressLocality": "Redmond",
"addressRegion": "Washington",
"postalCode": "98052",
"addressCountry": "US"
},
"description": "....",
"numberOfEmployees": 226717,
"logo": {
"contentUrl": "https://media.licdn.com/dms/image/C560BAQE88xCsONDULQ/company-logo_200_200/0/1630652622688/microsoft_logo?e=2147483647&v=beta&t=lrgXR6JnGSOHh9TMrOApgjnVMkQeZytbf87qVfOaiuU",
"description": "Microsoft",
"@type": "ImageObject"
},
"Website": "",
"Industry": "Software Development",
"Company size": "10,001+ employees",
"Headquarters": "Redmond, Washington",
"Type": "Public Company",
"Specialties": "Business Software, Developer Tools, Home & Educational Software, Tablets, Search, Advertising, Servers, Windows Operating System, Windows Applications & Platforms, Smartphones, Cloud Computing, Quantum Computing, Future of Work, Productivity, AI, Artificial Intelligence, Machine Learning, Laptops, Mixed Reality, Virtual Reality, Gaming, Developers, and IT Professional",
"addresses": [
"1 Denison Street, North Sydney, NSW 2060, AU",
....
],
"affiliatedPages": [
{
"name": "GitHub",
"industry": "Software Development",
"address": "San Francisco, CA",
"linkeinUrl": "https://www.linkedin.com/company/github"
},
....
],
"similarPages": [
{
"name": "Google",
"industry": "Software Development",
"address": "Mountain View, CA",
"linkeinUrl": "https://www.linkedin.com/company/google"
},
....
]
}
]
The above data represents the "about" section of the company pages. Next, we'll scrape the dedicated section for company jobs.
Scraping Company Jobs
The company jobs are found in a dedicated section of the main page, under the /jobs path of the primary LinkedIn URL for a company:
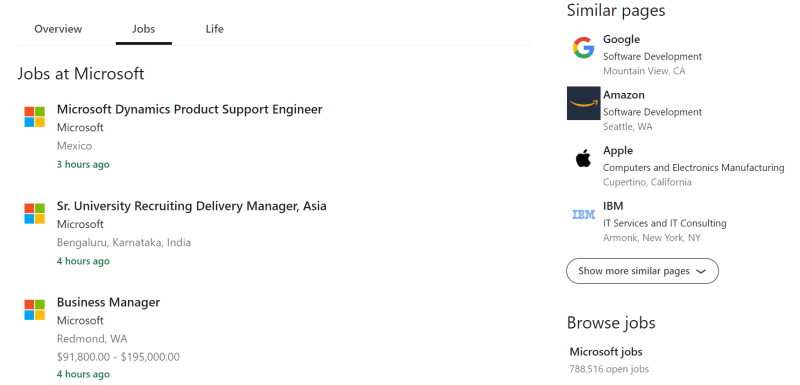
LinkedIn company job page
The page data here is being loaded dynamically on mouse scroll. We could use a real headless browser to emulate a scroll action though this approach isn't practical, as the job pages can include thousands of results!
Instead, we'll utilize a more efficient data extraction approach: scraping hidden APIs!
When a scroll action reaches the browser, the website sends an API request to retrieve the following page data as HTML. We'll replicate this mechanism in our scraper.
First, to find this hidden API, we can use our web browser:
- Open the browser developer tools.
- Select the network tab and filter by
Fetch/XHRrequests. - Scroll down the page to activate the API.
The API requests should be captured as the page is being scrolled:
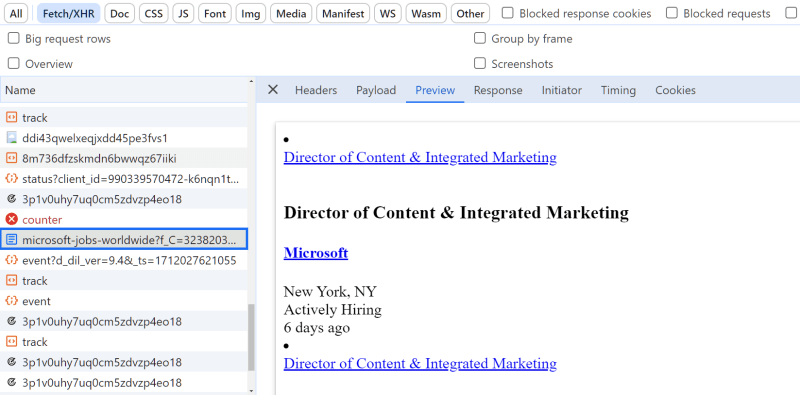
Hidden LinkedIn jobs API
We can see that the results are paginated using the start URL query parameter:
https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/microsoft-jobs-worldwide?start=75
To scrape LinkedIn company jobs, we'll request the first job page to get the maximum results available and then use the above API endpoint for pagination.
Python:
import json
import asyncio
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def strip_text(text):
"""remove extra spaces while handling None values"""
return text.strip().replace("\n", "") if text != None else text
def parse_jobs(response: Response) -> List[Dict]:
"""parse job data from job search pages"""
selector = Selector(response.text)
total_results = selector.xpath("//span[contains(@class, 'job-count')]/text()").get()
total_results = int(total_results.replace(",", "").replace("+", "")) if total_results else None
data = []
for element in selector.xpath("//section[contains(@class, 'results-list')]/ul/li"):
data.append({
"title": element.xpath(".//div/a/span/text()").get().strip(),
"company": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/text()").get().strip(),
"address": element.xpath(".//div/div[contains(@class, 'info')]/div/span/text()").get().strip(),
"timeAdded": element.xpath(".//div/div[contains(@class, 'info')]/div/time/@datetime").get(),
"jobUrl": element.xpath(".//div/a/@href").get().split("?")[0],
"companyUrl": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/@href").get().split("?")[0],
"salary": strip_text(element.xpath(".//span[contains(@class, 'salary')]/text()").get())
})
return {"data": data, "total_results": total_results}
async def scrape_jobs(url: str, max_pages: int = None) -> List[Dict]:
"""scrape Linkedin job search"""
first_page = await client.get(url)
data = parse_jobs(first_page)["data"]
total_results = parse_jobs(first_page)["total_results"]
# get the total number of pages to scrape, each page contain 25 results
if max_pages and max_pages * 25 < total_results:
total_results = max_pages * 25
log.info(f"scraped the first job page, {total_results // 25 - 1} more pages")
# scrape the remaining pages using the API
search_keyword = url.split("jobs/")[-1]
jobs_api_url = "https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/" + search_keyword
to_scrape = [
client.get(jobs_api_url + f"&start={index}")
for index in range(25, total_results + 25, 25)
]
for response in asyncio.as_completed(to_scrape):
response = await response
page_data = parse_jobs(response)["data"]
data.extend(page_data)
log.success(f"scraped {len(data)} jobs from Linkedin company job pages")
return data
ScrapFly
import json
import asyncio
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass linkedin.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
"headers": {
"Accept-Language": "en-US,en;q=0.5"
}
}
def strip_text(text):
"""remove extra spaces while handling None values"""
return text.strip() if text != None else text
def parse_jobs(response: ScrapeApiResponse) -> List[Dict]:
"""parse job data from Linkedin company pages"""
selector = response.selector
total_results = selector.xpath("//span[contains(@class, 'job-count')]/text()").get()
total_results = int(total_results.replace(",", "").replace("+", "")) if total_results else None
data = []
for element in selector.xpath("//section[contains(@class, 'results-list')]/ul/li"):
data.append({
"title": element.xpath(".//div/a/span/text()").get().strip(),
"company": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/text()").get().strip(),
"address": element.xpath(".//div/div[contains(@class, 'info')]/div/span/text()").get().strip(),
"timeAdded": element.xpath(".//div/div[contains(@class, 'info')]/div/time/@datetime").get(),
"jobUrl": element.xpath(".//div/a/@href").get().split("?")[0],
"companyUrl": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/@href").get().split("?")[0],
"salary": strip_text(element.xpath(".//span[contains(@class, 'salary')]/text()").get())
})
return {"data": data, "total_results": total_results}
async def scrape_jobs(url: str, max_pages: int = None) -> List[Dict]:
"""scrape Linkedin company pages"""
first_page = await SCRAPFLY.async_scrape(ScrapeConfig(url, **BASE_CONFIG))
data = parse_jobs(first_page)["data"]
total_results = parse_jobs(first_page)["total_results"]
# get the total number of pages to scrape, each page contain 25 results
if max_pages and max_pages * 25 < total_results:
total_results = max_pages * 25
log.info(f"scraped the first job page, {total_results // 25 - 1} more pages")
# scrape the remaining pages using the API
search_keyword = url.split("jobs/")[-1]
jobs_api_url = "https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/" + search_keyword
to_scrape = [
ScrapeConfig(jobs_api_url + f"&start={index}", **BASE_CONFIG)
for index in range(25, total_results + 25, 25)
]
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
page_data = parse_jobs(response)["data"]
data.extend(page_data)
log.success(f"scraped {len(data)} jobs from Linkedin company job pages")
return data
Run the code:
async def run():
job_search_data = await scrape_jobs(
url="https://www.linkedin.com/jobs/microsoft-jobs-worldwide",
max_pages=3
)
# save the data to a JSON file
with open("company_jobs.json", "w", encoding="utf-8") as file:
json.dump(job_search_data, file, indent=2, ensure_ascii=False)
if __name__ == " __main__":
asyncio.run(run())
Let's break down the above LinkedIn scraper code:
-
parse_jobs(): For parsing the jobs data on the HTML using XPath selectors. -
scrape_jobs(): For the main scraping tasks. It requests the company page URL and the jobs hidden API for pagination.
Here's an example output of extracted data we got:
[
{
"title": "Data Analyst: University Students and Recent Graduates",
"company": "Microsoft",
"address": "Redmond, WA",
"timeAdded": "2024-03-26",
"jobUrl": "https://www.linkedin.com/jobs/view/data-analyst-university-students-and-recent-graduates-at-microsoft-3868955104",
"companyUrl": "https://www.linkedin.com/company/microsoft",
"salary": null
},
...
]
Next, as we have covered the parsing logic for job listing pages, let's apply it to another section of LinkedIn - job search pages.
How to Scrape LinkedIn Job Search Pages?
LinkedIn has a robust job search system that includes millions of job listings across different industries across the globe. The job listings on these search pages have the same HTML structure as the ones listed on the company profile page. Hence, we'll utilize almost the same scraping logic as in the previous section.
To define the URL for job search pages on LinkedIn, we have to add search keywords and location parameters, like the following:
https://www.linkedin.com/jobs/search?keywords=python%2Bdeveloper&location=United%2BStates
The above URL uses basic search filters. However, it accepts further parameters to narrow down the search, such as date, experience level, or city.
We'll request the first page URL to retrieve the total number of results and paginate the remaining pages using the jobs hidden API.
Python:
import asyncio
import json
from urllib.parse import urlencode, quote_plus
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def strip_text(text):
"""remove extra spaces while handling None values"""
return text.strip().replace("\n", "") if text != None else text
def parse_job_search(response: Response) -> List[Dict]:
"""parse job data from job search pages"""
selector = Selector(response.text)
total_results = selector.xpath("//span[contains(@class, 'job-count')]/text()").get()
total_results = int(total_results.replace(",", "").replace("+", "")) if total_results else None
data = []
for element in selector.xpath("//section[contains(@class, 'results-list')]/ul/li"):
data.append({
"title": element.xpath(".//div/a/span/text()").get().strip(),
"company": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/text()").get().strip(),
"address": element.xpath(".//div/div[contains(@class, 'info')]/div/span/text()").get().strip(),
"timeAdded": element.xpath(".//div/div[contains(@class, 'info')]/div/time/@datetime").get(),
"jobUrl": element.xpath(".//div/a/@href").get().split("?")[0],
"companyUrl": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/@href").get().split("?")[0],
"salary": strip_text(element.xpath(".//span[contains(@class, 'salary')]/text()").get())
})
return {"data": data, "total_results": total_results}
async def scrape_job_search(keyword: str, location: str, max_pages: int = None) -> List[Dict]:
"""scrape Linkedin job search"""
def form_urls_params(keyword, location):
"""form the job search URL params"""
params = {
"keywords": quote_plus(keyword),
"location": location,
}
return urlencode(params)
first_page_url = "https://www.linkedin.com/jobs/search?" + form_urls_params(keyword, location)
first_page = await client.get(first_page_url)
data = parse_job_search(first_page)["data"]
total_results = parse_job_search(first_page)["total_results"]
# get the total number of pages to scrape, each page contain 25 results
if max_pages and max_pages * 25 < total_results:
total_results = max_pages * 25
log.info(f"scraped the first job page, {total_results // 25 - 1} more pages")
# scrape the remaining pages concurrently
other_pages_url = "https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?"
to_scrape = [
client.get(other_pages_url + form_urls_params(keyword, location) + f"&start={index}")
for index in range(25, total_results + 25, 25)
]
for response in asyncio.as_completed(to_scrape):
response = await response
page_data = parse_job_search(response)["data"]
data.extend(page_data)
log.success(f"scraped {len(data)} jobs from Linkedin job search")
return data
ScrapFly:
import json
import asyncio
from typing import Dict, List
from loguru import logger as log
from urllib.parse import urlencode, quote_plus
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
"asp": True,
"country": "US",
"headers": {
"Accept-Language": "en-US,en;q=0.5"
}
}
def strip_text(text):
"""remove extra spaces while handling None values"""
return text.strip() if text != None else text
def parse_job_search(response: ScrapeApiResponse) -> List[Dict]:
"""parse job data from job search pages"""
selector = response.selector
total_results = selector.xpath("//span[contains(@class, 'job-count')]/text()").get()
total_results = int(total_results.replace(",", "").replace("+", "")) if total_results else None
data = []
for element in selector.xpath("//section[contains(@class, 'results-list')]/ul/li"):
data.append({
"title": element.xpath(".//div/a/span/text()").get().strip(),
"company": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/text()").get().strip(),
"address": element.xpath(".//div/div[contains(@class, 'info')]/div/span/text()").get().strip(),
"timeAdded": element.xpath(".//div/div[contains(@class, 'info')]/div/time/@datetime").get(),
"jobUrl": element.xpath(".//div/a/@href").get().split("?")[0],
"companyUrl": element.xpath(".//div/div[contains(@class, 'info')]/h4/a/@href").get().split("?")[0],
"salary": strip_text(element.xpath(".//span[contains(@class, 'salary')]/text()").get())
})
return {"data": data, "total_results": total_results}
async def scrape_job_search(keyword: str, location: str, max_pages: int = None) -> List[Dict]:
"""scrape Linkedin job search"""
def form_urls_params(keyword, location):
"""form the job search URL params"""
params = {
"keywords": quote_plus(keyword),
"location": location,
}
return urlencode(params)
first_page_url = "https://www.linkedin.com/jobs/search?" + form_urls_params(keyword, location)
first_page = await SCRAPFLY.async_scrape(ScrapeConfig(first_page_url, **BASE_CONFIG))
data = parse_job_search(first_page)["data"]
total_results = parse_job_search(first_page)["total_results"]
# get the total number of pages to scrape, each page contain 25 results
if max_pages and max_pages * 25 < total_results:
total_results = max_pages * 25
log.info(f"scraped the first job page, {total_results // 25 - 1} more pages")
# scrape the remaining pages concurrently
other_pages_url = "https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?"
to_scrape = [
ScrapeConfig(other_pages_url + form_urls_params(keyword, location) + f"&start={index}", **BASE_CONFIG)
for index in range(25, total_results + 25, 25)
]
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
page_data = parse_job_search(response)["data"]
data.extend(page_data)
log.success(f"scraped {len(data)} jobs from Linkedin job search")
return data
Run the code:
async def run():
job_search_data = await scrape_job_search(
keyword="Python Developer",
location="United States",
max_pages=3
)
# save the data to a JSON file
with open("job_search.json", "w", encoding="utf-8") as file:
json.dump(job_search_data, file, indent=2, ensure_ascii=False)
if __name__ == " __main__":
asyncio.run(run())
Here, we start the scraping process by defining the job page URL using the search query and location. Then, request and parse the pages the same way we've done in the previous section.
Here's an example output of the above code for scraping LinkedIn job search:
[
{
"title": "Python Developer",
"company": "LTIMindtree",
"address": "Charlotte, NC",
"timeAdded": "2024-03-05",
"jobUrl": "https://www.linkedin.com/jobs/view/python-developer-at-ltimindtree-3842154964",
"companyUrl": "https://in.linkedin.com/company/ltimindtree",
"salary": null
},
....
]
We can successfully scrape the job listings. However, the data returned doesn't contain the details. Let's scrape them from their dedicated pages!
How to Scrape LinkedIn Job Pages?
To scrape LinkedIn job pages, we'll utilize the hidden web data approach once again.
To start, search for the selector //script[@type='application/ld+json'], and you will find results similar to the below:

If we take a closer look at the description field, we'll find the job description encoded in HTML. Therefore, we'll extract the script tag hidden data and parse the description field to get the full job details.
Python:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def parse_job_page(response: Response):
"""parse individual job data from Linkedin job pages"""
selector = Selector(response.text)
script_data = json.loads(selector.xpath("//script[@type='application/ld+json']/text()").get())
description = []
for element in selector.xpath("//div[contains(@class, 'show-more')]/ul/li/text()").getall():
text = element.replace("\n", "").strip()
if len(text) != 0:
description.append(text)
script_data["jobDescription"] = description
script_data.pop("description") # remove the key with the encoded HTML
return script_data
async def scrape_jobs(urls: List[str]) -> List[Dict]:
"""scrape Linkedin job pages"""
to_scrape = [client.get(url) for url in urls]
data = []
# scrape the URLs concurrently
for response in asyncio.as_completed(to_scrape):
response = await response
data.append(parse_job_page(response))
log.success(f"scraped {len(data)} jobs from Linkedin")
return data
ScrapFly
import json
import asyncio
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly API key")
BASE_CONFIG = {
# bypass linkedin.com web scraping blocking
"asp": True,
# set the proxy country to US
"country": "US",
"headers": {
"Accept-Language": "en-US,en;q=0.5"
}
}
def parse_job_page(response: ScrapeApiResponse):
"""parse individual job data from Linkedin job pages"""
selector = response.selector
script_data = json.loads(selector.xpath("//script[@type='application/ld+json']/text()").get())
description = []
for element in selector.xpath("//div[contains(@class, 'show-more')]/ul/li/text()").getall():
text = element.replace("\n", "").strip()
if len(text) != 0:
description.append(text)
script_data["jobDescription"] = description
script_data.pop("description") # remove the key with the encoded HTML
return script_data
async def scrape_jobs(urls: List[str]) -> List[Dict]:
"""scrape Linkedin job pages"""
to_scrape = [ScrapeConfig(url, **BASE_CONFIG) for url in urls]
data = []
# scrape the URLs concurrently
async for response in SCRAPFLY.concurrent_scrape(to_scrape):
data.append(parse_job_page(response))
log.success(f"scraped {len(data)} jobs from Linkedin")
return data
Run the code:
async def run():
job_data = await scrape_jobs(
urls=[
"https://www.linkedin.com/jobs/view/python-developer-internship-at-mindpal-3703081824",
"https://www.linkedin.com/jobs/view/python-developer-at-donato-technologies-inc-3861152070",
"https://www.linkedin.com/jobs/view/python-developer-at-ltimindtree-3846584680"
]
)
# save the data to a JSON file
with open("jobs.json", "w", encoding="utf-8") as file:
json.dump(job_data, file, indent=2, ensure_ascii=False)
if __name__ == " __main__":
asyncio.run(run())
Similar to our previous LinkedIn scraping logic, we add the job page URLs to a scraping list and request them concurrently. Then, we use the parse_job_page() function to parse the job data from the hidden script tag, including the HTML inside the description field.
Here's what the above code output looks like:
[
{
"@context": "http://schema.org",
"@type": "JobPosting",
"datePosted": "2024-03-07T14:20:22.000Z",
"employmentType": "FULL_TIME",
"hiringOrganization": {
"@type": "Organization",
"name": "LTIMindtree",
"sameAs": "https://in.linkedin.com/company/ltimindtree",
"logo": "https://media.licdn.com/dms/image/D4D0BAQH26vEc2KRwsQ/company-logo_200_200/0/1704351215489?e=2147483647&v=beta&t=lunasZKbztyfyb5IDwied0q7Eys_PeGNRKNN2hiRxwI"
},
"identifier": {
"@type": "PropertyValue",
"name": "LTIMindtree"
},
"image": "https://media.licdn.com/dms/image/D4D0BAQH26vEc2KRwsQ/company-logo_100_100/0/1704351215489?e=2147483647&v=beta&t=dxemJZvZTahW-4UnXsmpLdShnPvj5GbPutcBfJ01TjE",
"industry": "Banking",
"jobLocation": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"addressCountry": "US",
"addressLocality": "Charlotte",
"addressRegion": "NC",
"streetAddress": null
},
"latitude": 35.223785,
"longitude": -80.84114
},
"skills": "",
"title": "Python Developer",
"validThrough": "2024-06-03T15:32:45.000Z",
"educationRequirements": {
"@type": "EducationalOccupationalCredential",
"credentialCategory": "bachelor degree"
},
"baseSalary": {
"@type": "MonetaryAmount",
"currency": "USD",
"value": {
"@type": "QuantitativeValue",
"minValue": 98015,
"maxValue": 146600,
"unitText": "YEAR"
}
},
"jobDescription": [
"Comprehensive Medical Plan Covering Medical, Dental, Vision",
"Short Term and Long-Term Disability Coverage",
"401(k) Plan with Company match",
"Life Insurance",
"Vacation Time, Sick Leave, Paid Holidays",
"Paid Paternity and Maternity Leave"
]
},
....
]
The job page scraping code can be extended with further crawling logic to scrape their pages after they are retrieved from the job search pages.
With this last feature, our LinkedIn scraper tool is complete. It can successfully scrape profile, company, and job data. However, attempts to increase the scraping rate will lead the website to detect and block the IP address origin. Let's have a look at a solution!
Bypass LinkedIn Web Scraping Blocking
ScrapFly is a web scraping API with millions of residential proxy IPs, which can bypass LinkedIn IP address blocking. Moreover, ScrapFly allows for scraping at scale by providing features like:
- Anti-scraping protection bypass - For bypassing websites' anti-scraping protection mechanisms, such as Cloudflare.
- JavaScript rendering - For scraping dynamic web pages through cloud headless browsers without running them yourself.
- Easy to use Python and Typescript SDKs, as well as Scrapy integration.
- And much more!

ScrapFly service does the heavy lifting for you
To scrape LinkedIn data without getting blocked using ScrapFly all we have to do is replace our HTTP client with the ScrapFly client, enable the asp parameter, and select a proxy country:
# standard web scraping code
import httpx
from parsel import Selector
response = httpx.get("some linkedin.com URL")
selector = Selector(response.text)
# in ScrapFly becomes this 👇
from scrapfly import ScrapeConfig, ScrapflyClient
# replaces your HTTP client (httpx in this case)
scrapfly = ScrapflyClient(key="Your ScrapFly API key")
response = scrapfly.scrape(ScrapeConfig(
url="website URL",
asp=True, # enable the anti scraping protection to bypass blocking
country="US", # set the proxy location to a specfic country
proxy_pool="public_residential_pool",
render_js=True # enable rendering JavaScript (like headless browsers) to scrape dynamic content if needed
))
# use the built in Parsel selector
selector = response.selector
# access the HTML content
html = response.scrape_result['content']
FAQ
To wrap up this guide on web scraping LinkedIn, let's have a look at a few frequently asked questions.
Is it legal to scrape LinkedIn data?
Yes, public LinkedIn pages such as public people profiles, company pages and job listings are perfectly legal to scrape as long as the scraper doesn't damage the LinkedIn website.
Are there public APIs for LinkedIn?
Yes, LinkedIn offers paid APIs for developers. That being said, scraping LinkedIn is straightforward, and you can use it to create your own scraper APIs.
Are there alternatives for web scraping LinkedIn?
Yes, other popular platforms for job data collection are Indeed, Glassdoor, and Zoominfo, which we have covered earlier. For more guides on scraping similar target websites, refer to our #scrapeguide blog tag.
Latest LinkedIn Scraper Code
Summary
In this guide, we explained how to scrape LinkedIn with Python. We went through a step-by-step guide on extracting different data types from LinkedIn:
- Company and public profile pages.
- Jobs and their search pages
For this LinkedIn scraper, we have used httpx as an HTTP client and parsel to parse the HTML. We have also used some web scraping tricks, such as extracting hidden data from JavaScript tags and using hidden APIs.


















