
My name is Sebastian, and I have been working as a TypeScript & JavaScript developer for many years, primarily as a freelancer.
Throughout my career, I have worked on various projects, ranging from monolithic architectures and cloud microservice architectures to Lambda/FaaS architectures.
I have experience working in small teams as well as global distributed multi-team environments.
Currently, I am working on a TypeScript-based backend framework called PURISTA.
In this article, I aim to explain why there is a need for new frameworks for backend development.
The issues I would like to address with my framework are as follows:
- The decision regarding how the software will be deployed must be made early on, at the beginning of the project.
- The choice between monolithic, microservice, or Lambda architectures cannot be easily changed or reverted.
- Single developers, small teams, and small startups can work faster if they don't have to worry about infrastructure or deployment and can focus solely on business requirements.
- Monolithic architectures are generally harder to scale when multiple developers and teams are involved in the project.
In short, the goal is to build software quickly, focusing on business requirements, in a cost-efficient manner, without losing flexibility for the future.
There are various architecture options available, including monoliths, distributed microservices, and applications built with multiple Lambda functions.
Each architecture has its own advantages and disadvantages, and the choice depends on the specific project, codebase, and team dynamics.
Based on my experience, I would like to make two general statements:
Statement 1: When transitioning from a monolithic approach to a distributed approach, the complexity and workload required to manage the software significantly increase.
Statement 2: Converting a monolith into a distributed system requires extensive refactoring and work, especially if the original implementation lacks modularity and separation.
These statements may vary depending on the project, codebase, and team size.
The core idea of my framework is to build software in a similar style to Lambdas and FaaS, utilizing a message-based communication approach inspired by event-driven architectures. Each endpoint, GraphQL query/resolver, or task is treated as a single isolated function.
I have categorized these functions into two types: Commands and Subscriptions.
A Command is a function triggered by someone or something, expecting a response as a result.
On the other hand, a Subscription listens for specific events or message patterns.
The producer of these events or messages has no knowledge of the consuming Subscriptions. Moreover, a Subscription can generate its own events or messages that can be consumed by other Subscriptions.
Commands and Subscriptions are organized into a Service, which can be considered as a domain. A Service primarily provides general configuration and should not contain any business functionality.
So far, so good, right? Now you might be wondering, where is the key to this approach?
The key lies in the fact that the communication and deployment mechanisms are abstracted away by the framework.
The implementation is done against interfaces, allowing flexibility in choosing the communication and deployment strategies.

For example, let's consider two services: the User service with the registerNewUser command and the Email service with the sendWelcomeMail subscription, which sends an email to every user registered by the registerNewUser command.
In a simple monolithic deployment scenario, the index or main file would look like this:
import { DefaultEventBridge } from '@purista/core'
import { emailV1Service } from './service/email/v1'
import { userV1Service } from './service/user/v1'
const main = async () => {
const eventBridge = new DefaultEventBridge()
await eventBridge.start()
const userService = userV1Service.getInstance(eventBridge)
await userService.start()
const emailService = emailV1Service.getInstance(eventBridge)
await emailService.start()
}
main()
Now, if you want to scale your application, you have two options.
Option one is to simply spin up a new instance, which works well for simple examples. However, in more complex and fault-tolerant scenarios, you may want to distribute the load between instances.
This brings us to option two: adding a message broker to the mix. Currently, there are several possibilities available, with more options constantly emerging. You can currently choose between AMQP (RabbitMQ), MQTT, NATS, and Dapr.
To take your application to the next level, you only need to make a small change in the index or main file:
// import some other event bridge
import { AmqpBridge } from '@purista/amqpbridge'
import { emailV1Service } from './service/email/v1'
import { userV1Service } from './service/user/v1'
const main = async () => {
// change the event bridge
const eventBridge = new AmqpBridge()
await eventBridge.start()
const userService = userV1Service.getInstance(eventBridge)
await userService.start()
const emailService = emailV1Service.getInstance(eventBridge)
await emailService.start()
}
main()
With this configuration, when a new user is created by instance 1, they will receive a welcome email sent by either instance 1 or instance 2. The work will be evenly shared between the instances.
Imagine that your team and product are growing, and you need to scale. You decide to transition to a multi-repository and microservices architecture.
The process is straightforward. Copy the code into multiple repositories and remove the service folders that are not relevant to each repository. Then, open the index or main files and remove the services that are not needed.
The index file for the User repository will look like this:
import { AmqpBridge } from '@purista/amqpbridge'
import { userV1Service } from './service/user/v1'
const main = async () => {
const eventBridge = new AmqpBridge()
await eventBridge.start()
const userService = userV1Service.getInstance(eventBridge)
await userService.start()
}
main()
And the index file for the Email repository will look like this:
import { AmqpBridge } from '@purista/amqpbridge'
import { emailV1Service } from './service/email/v1'
const main = async () => {
const eventBridge = new AmqpBridge()
await eventBridge.start()
const emailService = emailV1Service.getInstance(eventBridge)
await emailService.start()
}
main()
Now, you can deploy each repository as a separate microservice.
Each service can be managed independently, and developers can work on specific repositories without affecting others.
If you find that the microservices architecture does not meet your requirements, you can easily revert the changes.
What about deploying as AWS Lambda or Azure Function?
The approach is similar.
As services are logical groups of commands and subscriptions, you only need to deploy each service individually, with only one command or subscription.
I am currently investigating different approaches to automate this process as much as possible. It is technically feasible, and I aim to provide simple ways to reduce manual steps. This may involve connecting to AWS EventBridge and AWS API Gateway to support real-world scenarios.
As you can see, this approach allows you to postpone the decision between a monolith, microservices, or FaaS-style architecture until later in the development process.
It also provides the flexibility to change your mind and revert the changes without refactoring your entire codebase.
This approach offers the advantage of starting small and easily scaling up. It is particularly suitable for Proof of Concept (PoC) and prototype development, as it allows you to build a stable product that can grow and scale. Additionally, much of the necessary documentation, such as OpenAPI documentation, is automatically generated from your code.
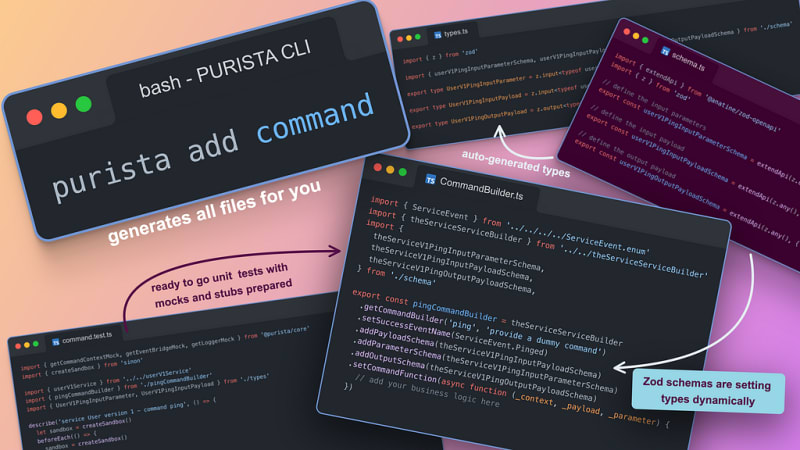
PURISTA also provides a convenient Command Line Interface (CLI) wizard to enhance your efficiency. This CLI allows you to create projects, add services, commands, and subscriptions effortlessly.
If you're interested in trying it out, you can follow the steps outlined in the Handbook's Quickstart guide using the CLI.
Alternatively, you can watch a small presentation for a quick overview of PURISTA.
In addition to these features, PURISTA offers several other functionalities worth mentioning:
- A straightforward CLI for project creation and management, including services, commands, and subscriptions.
- Built-in OpenTelemetry for tracing and observability.
- Strict validation of input/output schemas.
- Automatic generation of TypeScript types and OpenAPI documentation based on input/output schemas.
- Logging capabilities.
- Abstraction of state stores for sharing and persisting business states.
- Abstraction of config stores to centralize configurations.
- Abstraction of secret stores, allowing you to choose the one that suits your needs (e.g., AWS Secret Store, Infisical, Vault).
It's important to note that while not all adapters and brokers are currently available, PURISTA is continuously growing, with plans to abstract file access, such as S3 integration, in the future.
Thank you for taking the time to read my article. I hope you found it enjoyable and not too dull. I invite you to explore my project and share your thoughts, opinions, and ideas with me. Please feel free to reach out to me directly.
Official Website: https://purista.dev
GitHub Repo: https://github.com/sebastianwessel/purista


















