When building a QA test automation framework, it's critical to define the strategy for dealing with test data. For example, what’s wrong with this scenario?
Given the user successfully logs into registration system
When the user searches for course number “ALG-4316”
Then the course is displayed
And the course has title of “Intermediate Algebra”
And the course has credit hours of “4”
Clearly the scenario contains hard-coded test data: course number, course name, and credit hours.
When first building test automation it's easy to start like this. We're testing in the dev environment, we know this course exists in the database, so let's start building some automated tests! Although it's easy to get started like this, it can quickly become impossible to sustain.
Let's take a look at some alternatives for dealing with test data.
Option 1 - Hard-coded test data
Overview
The architecture behind the hard-coded test data option is not too difficult to understand. With this option, the test data is defined within the test process and stored in data files or hard-coded directly in the test.
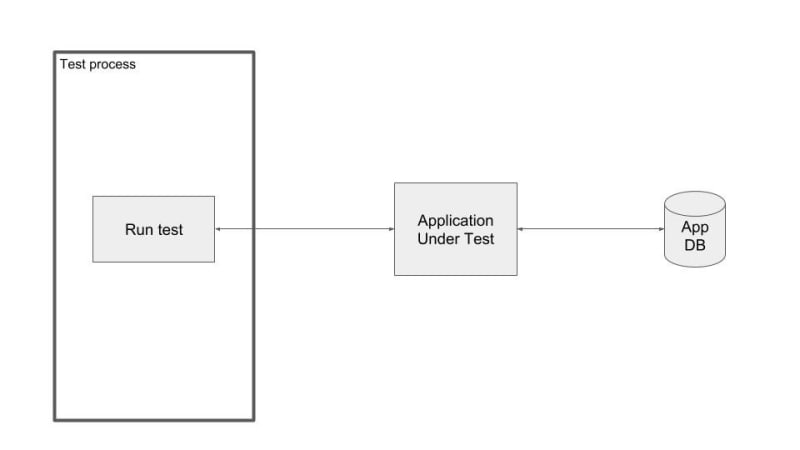
Pros:
- Start building and completing tests quickly
Cons:
- Long term test maintainability and brittleness
- Issues running tests in different environments/databases
- Could require a database restore strategy prior to running the test
When appropriate?
Although all tests may contain some hard-coded test data, it’s really only appropriate for [1] static data that will not change across environments, for [2] data that is not relevant to the test, or for [3] test setups where you can always restore the database to a known state before testing.
OPTION 2 - Real time test data extract
Let’s try the gherkin again and remove the hard-coded test data:
Given the user successfully logs into registration system
When the user searches for an active course
Then the course is displayed
And the course title is correctly displayed
And the course credit hours are correctly displayed
With this option we are no longer defining the test data in the test. The automation code that’s executed behind this test will be responsible for identifying the necessary test data and expected results. But how?
Overview
With real time test data extract, the test process will extract the necessary test data from the application as we execute the test. So instead of hard-coding the course number, we can first extract a valid course number and associated course detail from the application, and then use that data in our test.
As shown in the diagram below, the data can be extracted via an existing application API or by reading it directly from the application database.

Pros:
- Tests are not reliant on specific hard-coded test data
- Tests will work across multiple test environments
Cons:
- Need a reliable mechanism to read from the application (API or DB)
- Assumes the database already contains data you need
- Could have issues with concurrent tests grabbing same test data
When appropriate?
This option is appropriate when [1] the necessary test data exists in the database, [2] there are no concerns with concurrent tests potentially using the same data, and [3] we have read access to the database, either through API or direct database access.
OPTION 3 - Real time seeding
Overview
With real time test data seeding, the test process will inject the necessary test data into the application as we execute the test. So instead of testing with an existing course number, we can first inject a valid course number and associated detail into the application, and then use that data in our test.
As shown in the diagram below, the data can be injected via an existing application API or by inserting it directly from the application database.

Pros:
- Tests are not reliant on specific hard-coded test data
- Tests will work across multiple test environments
- No data sharing issues with concurrent tests
Cons:
- Need a mechanism to write to database (API or direct)
- Seeding data may be more complex that just extracting existing data
When appropriate?
This option is appropriate when [1] the necessary test data may not already exist in the database, [2] tests will run concurrently and can’t share the same data, and [3] we have write access to the database, either through API or direct database access.
OPTION 4 - Decoupled extract
The options describe above may work well for functional testing, but what about performance testing? With performance testing we’ll simulate multiple concurrent users to verify the application can handle the required workload and respond within the expected response times.
Interacting with the application to acquire test data during a performance test will just apply more load to the application. This load is not representative of a real-world scenario, and would likely skew the test results and server performance statistics.
To get around this issue we can decouple the test data creation process from the testing process.

As represented above, the necessary test data is injected into the application prior to the start of the performance testing. In addition to injecting the test data, we’ll also write that test data to a data repository on a server that is separate from the application.
When the performance test starts, it will read test data from that test data repository. This strategy will allow the performance tests to be driven by test data without seeding or extracting it during the test.
Although this process is probably the most complex method for dealing with test data, it does provide an additional bonus; the test data generated for performance testing can also be consumed by the functional UI and API tests, as depicted above.
Conclusion
As you define the test data strategy for your project, there is clearly not one correct way to do it. In fact, you will likely use various options on the same project, depending on the needs of specific tests.
Regardless of your strategy, be sure to think about it up front, and refine it as you learn more about what works and what doesn’t.



















