
This article is a follow up of the article 'what quarks is about':
Quarks - a new mindset ... (https://dev.to/lucpattyn/quarks-a-new-approach-with-a-new-mindset-to-programming-10lk).
There was another article about architecture, but over time the concept has been simplified, hence the new writeup.
Just to recap, Quarks is a fast information write and querying system and so far we have implemented a single isolated individual node. Now it is time for data replication and making multiple nodes work together for a scalable solution.
It would be easier to explain the whole system with a diagram. The diagram discusses 3 stages one after one for data saving and replication:
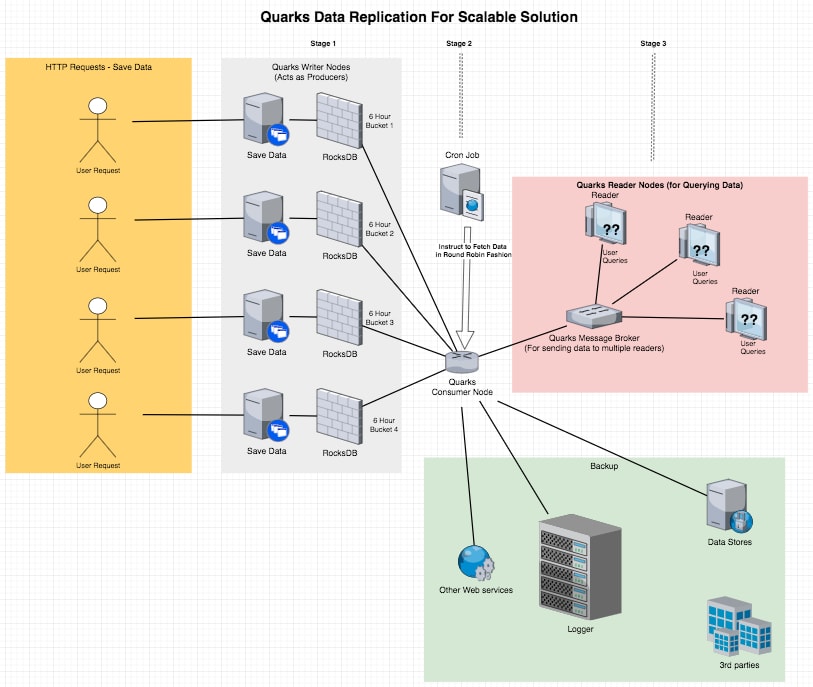
First and foremost we need a scalable system to save the data when there are frequent hits, which we are denoting as stage 1.
At this stage, we are using Quarks Writer nodes (we can use as many depending on the traffic) to save data.
Each node creates multiple rocksdb instances in bucket concept because later when we retrieve data from these buckets, we don't have to go over a lot of data. Once all the data of one bucket has been retrieved and replicated, we will delete the buckets, so not a lot of disk space is used. The diagram shows only one bucket per writer node for keeping the illustration clean, but actually each node will create multiple buckets. Once data saving starts, it is time for stage 2 to fetch data and replicate.
In stage 2, we run a cron job to control a Quarks Consumer node to go through all the available writer nodes in round robin fashion and fetch data in bulks. The consumer gets a bulk of data from node 1 (writer node of-course), sends it to a broker which serialises and maintain a message queue (message object is the data + instructions/hints of what to do with the data) to send to required destinations (the primary destination being the message broker, secondary being logging servers and third parties). Then the consumer picks node 2, performs same action and moves on to node 3 and so on. As data starts filling the message queue in broker node, it is time for stage 3.
In this stage, the broker picks messages from the queue, extracts data, sends to Reader Nodes which basically responds back to clients the data when requested. Quarks supports in memory data store, so if required can fetch and send date to clients really fast.
One thing to note is a single Writer Node don't have all the data. Multiple such nodes together holds the whole data.
The message broker is responsible for aggregating data and ensure individual reader nodes have all the data (since there cannot be inconsistency in data when queried).
Quarks is sharding-enabled by nature. You would be able to write logics in the broker (not implemented yet) to select the right readers for buckets of data based on sharding logic.
To re-iterate, simplicity is at the heart of Quarks, and it aims to build a scalable solutions for modern world software development in server side.


















