
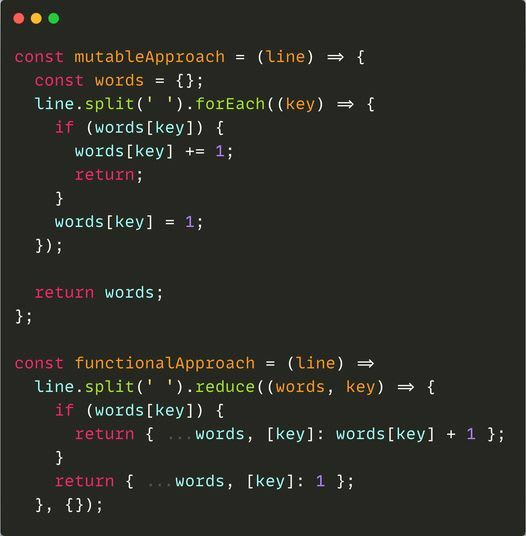
If we are to process unique word counts for input data (read many sentences), the solution is pretty straightforward using a map. Javascript example below:
However, if the number of unique words is huge and there are memory limitations, then finding an optimal solution becomes difficult. In that case we can go with a tree traversal route to save memory. Say, we have a to find the count of few words from input data. Words are "Stack", "Stick", "Stuck", "The", "Then". We can form a multi node tree where the leaf nodes will contain the count. Illustration below:
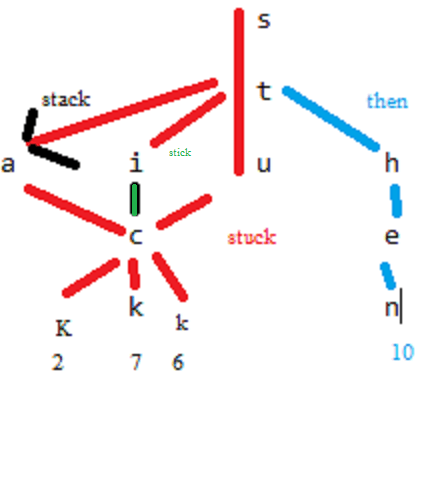
As you can see, instead of having stuck, stack, stick, stuck as separate elements in the map, we are creating a tree to save some letters (bytes) being reused.
Disclaimers note: I don't have the exact algorithms in my head as code yet :) and the representation of "the" and "then" in the image is not exactly right.
Thanks Joynal (https://www.linkedin.com/in/joynaluu/) for bringing up the topic to ponder upon in social media.
signing off,
Mukit


















