
Redis is all about speed. But just because Redis is fast, doesn't mean it still doesn't take up time and resources when you are making requests to it. Those requests, when not made responsibly, can add up and impact the performance of your application. Here is the story about how Kenna learned this lesson the hard way.
Hiding in Plain Sight
One of the largest tables in Kenna's database is vulnerabilities. We currently have almost 4 BILLION. A vulnerability is a weakness which can be exploited by an attacker in order to gain unauthorized access to a computer system. Basically, they are ways a company can be hacked.
We initially store all of these vulnerabilities in MySQL, which is our source of truth. From there, we index the vulnerability data into Elasticsearch.

When we index all of these vulnerabilities into Elasticsearch, we have to make requests to Redis in order to know where to put them. In Elasticsearch, vulnerabilities are organized by client. In order to figure out where a vulnerability belongs, we have to make a GET request to Redis to fetch the index name for that vulnerability.
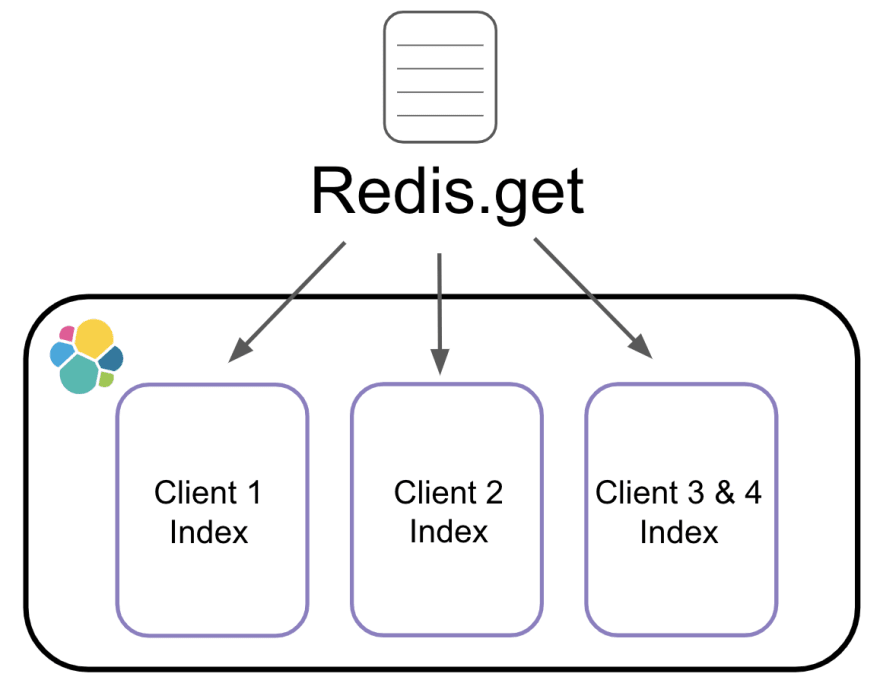
When preparing vulnerabilities for indexing, we gather all the vulnerability hashes up. Then, one of the last things we do before sending them to Elasticsearch, is make that Redis GET request to retrieve the index name for each vulnerability based on its client.
indexing_hashes = vulnerability_hashes.map do |hash|
{
:_index => Redis.get("elasticsearch_index_#{hash[:client_id]}")
:_type => hash[:doc_type],
:_id => hash[:id],
:data => hash[:data]
}
end
Those vulnerability hashes are grouped by client, so that GET request
Redis.get("elasticsearch_index_#{hash[:client_id]}")
is often returning the same information over and over again. All these simple GET requests are blindly fast. They take about a millisecond to run.
(pry)> index_name = Redis.get("elasticsearch_index_#{client_id}")
DEBUG -- : [Redis] command=GET args="elasticsearch_index_1234"
DEBUG -- : [Redis] call_time=1.07 ms
But it doesn't matter how fast your external requests are, if you are making a ton of them it is going to take you a long time. Because we were making so many of these simple GET requests, they were responsible for roughly 65% of the runtime for our indexing jobs. You can see this stat in the table below and it is represented by the brown in the graph.

The solution to eliminating a lot of these requests was a local Ruby cache! We ended up using a Ruby hash to cache the Elasticsearch index name for each client.
client_indexes = Hash.new do |h, client_id|
h[client_id] = Redis.get("elasticsearch_index_#{client_id}")
end
Then, when looping through all of the vulnerability hashes to send to Elasticsearch, instead of hitting Redis for each vulnerability, we would simply reference this client indexes hash.
indexing_hashes = vuln_hashes.map do |hash|
{
:_index => client_indexes[hash[:client_id]]
:_type => hash[:doc_type],
:_id => hash[:id],
:data => hash[:data]
}
end
This meant we only had to hit Redis once per client instead of once per vulnerability.
The Payoff
Let's say we have 3 batches of vulnerabilities that need to be indexed.

In the case of these three batches, no matter how many vulnerabilities we have in each batch, we will only ever need to make a total of 3 requests to Redis. These batches usually contain 1k vulnerabilities each, so this change decreased the hits we were making to Redis by 1000x which led to a 65% increase in job speed.
Even though Redis is fast, using a local cache is always going to be faster! To put it into perspective for you, to get a piece of information from a local cache is like driving from downtown Chicago to O’Hare Airport to get it.

To get that same piece of information from Redis, is like taking a plane from Chicago and flying all the way to Boston to get it.

Redis is so fast that it is easy to forget that you are actually making an external request when you are talking to it. Those external requests can add up and have an impact on the performance of your application. Don't take Redis for granted. Make sure every request you are making to it is absolutely necessary.
If you are interested in other ways to prevent database hits using Ruby checkout my Cache Is King speech from RubyConf which is what inspired this post.


















