
Ever needed to server big JSON files over the network (like 100+ MB files).
The efficient way we can handle this problem is by converting the JSON files to binary and then send it to the client.
Firs lets just convert JSON to .gz file and see the size difference.
Comparison:
File sizes:
Actual - 107MB. Compressed .gz file - 7.2MB.
Download time:
Actual - 60sec (on a 4G network)
compressed - 2sec.
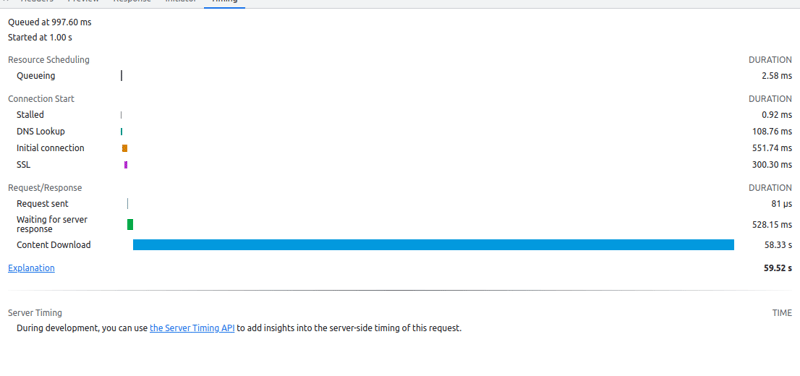
Parsing compressed file:
Time taken by browser (chrome)
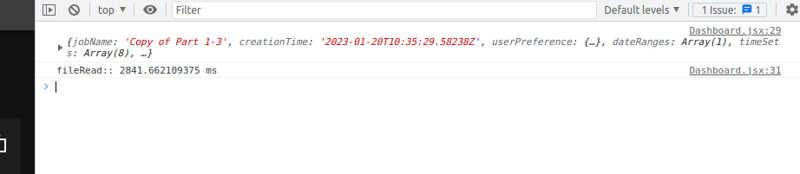
- Pako library takes
2841 ms. - fflate library takes
600 ms
After doing the decompression parsing the JSON will take 600 700 ms for the decompressed string.
Pako running time log
Process
Enough comparision let's start the compression. If you are using a Linux system you can use below command to convert JSON to .gz
gzip filename.json It will convert your file to the .gz file.
But you can also use the Pako, zlib any library to encode you JSON file to .gz Its pretty easy or you can use any online tool to do so.
Now the file size is much much smaller you can store it in s3 bucket or any CDN and easily download it in your frontend APP. What you will have to do is just parse the compressed data and use it.
A useful library to convert binary data to string on frontend is pako.
Use below code in React.js to convert .gz to .json file.
import { inflate } from "pako";
const parse = (bin) => inflate(bin, { to: "string" });
export const fetchJSONFromGZFile = () => {
return fetch("/data/pathLayer/1-3.json.gz").then(
async (response) => {
const blob = await response.blob();
await readSingleFile(blob).then((res) => {
return JSON.parse(parse(res));
});
});
};
export async function readSingleFile(file) {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = function (e) {
resolve(e?.target?.result);
};
reader.readAsArrayBuffer(file);
reader.onabort = reject;
reader.onerror = reject;
});
};
// with axios the get request will be a little different
const { data } = await axios.get("/data/pathLayer/1-3.json.gz", {
responseType: 'arraybuffer', // important
decompress: true,
});
jsonData = JSON.parse(parse);
Also there is another decompression library called fflet which is quite faster than Pako lib.
To use it with fflet lib just replace parse function in earlier code with the below one.
import { strFromU8, decompressSync } from 'fflate';
const parse = (bin) => {
return strFromU8(decompressSync(new Uint8Array(bin)));
}
Parsing the JSON from the decompressed string will be blocking the main thread but we can get around it with the Response interface of JavaScript's Fetch API.
So instead of JSON.parse(data) we can do await new Response(data).json()
Why this article even make sense:
Well recently I was working with deck.gl and had to render big JSON dataset files (over 150+ MB). If the files were locally present that's OK but imagine serving those dataset files from a CDN 😨😨.
For ex. In my app every time I reload a screen which has google map I will have to download a 100MB JSON file again (can add better cache policy).
For the same problem I researched over the internet about how to serve large dataset files efficiently/optimize in deck.gl and found nothing, and at last I end up with doing binary conversion and decoding those files in browser to render map contents.
I know this is not the optimal approach but If anyone has a better approach or has any experience with deck.gl of rendering large datasets. Please comment down below.
Thanks.
References:


















