Introduction.
Data is the new oil. Companies want to make the most of the data they produce. For achieving this goal, there is a need for systems capable of consuming, processing, analysing, and presenting massive volumes of data. These systems need to be easy to use, but they also need to be reliable, able to detect problems and store data correctly. These and other issues are intended to be resolved by Data Platforms.
It is not an easy task to build a Data Platform. Multiple skill sets are needed, from infrastructure and programming to data management.
This article is the first, of what I hope will be a longer series of articles where we'll try to unravel the secrets of how to build a Data Platform that allows you to generate value-added products for your users.
What is a data platform?
We can discover definitions of what is a data platform just using our preferred web search engine. For example, I found the following definitions:
A data platform enables the acquisition, storage, preparation, delivery, and governance of your data, and adds a security layer for users and applications.
https://www.mongodb.com/what-is-a-data-platformA data platform is a complete solution for ingesting, processing, analyzing and presenting the data generated by the systems, processes and infrastructures of the modern digital organization.
https://www.splunk.com/en_us/data-insider/what-is-a-data-platform.html
So, a data platform is a place where we can store data from multiple sources. Also a data platform provides users with the required tools for searching, working and transforming that data, with the goal of creating some kinds of products. These products could be dashboards with useful insights, machine learning products, etc, etc.
What is a data platform? Very simplified diagram.

In this diagram we can find all the basic components that create a data platform (we are not trying to describe a Data Mesh or a Data Management Platform, those things will be left out for other future articles) You can find the same components with other names but same functionality in other diagrams describing other data platforms. In this diagram we can find these components:
Data Sources: databases, REST APIs, event buses, analytics tools, etc, etc.
Consumption: tools for consuming the data sources.
Storage: the place where the consumed data will be located.
Security layer: component in charge of providing authentication, authorization and auditory.
Processing: programs or tools that will enable us to work with the stored data.
Data Catalog: because the amount of stored data will be huge, we need a tool that will make easy for users to find the data that they need.
Tableau, Qlik, Kubeflow, MLflow, etc, etc: data will be used for some goal. Typically this goal could be to create a dashboard with meaningful diagrams, create models for machine learning and many other things.
This first article will be focusing on the storage layer, so from now on, we will talk only about that component.
Storage layer.
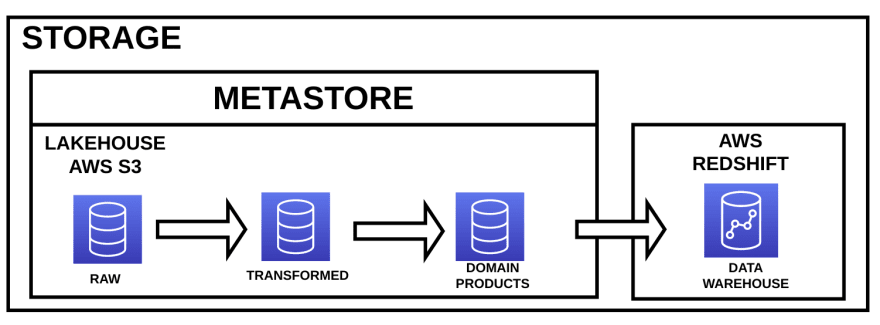
Of course, the storage layer is the place where the data is stored. Because the amount of data to be stored is huge, we can not use HDD or SSD data storages, we need something cheaper. In this case we will be talking about AWS S3 because we are working with Amazon Web Services. For Azure, you could use Azure Data Lake Storage Gen2. If you are working with Google Cloud, you could use Google Cloud Storage. It does not matter what storage you use as long as it is cheap and can store a huge amount of data.
You can see in this diagram three different elements:
- Data Lakehouse: it is the evolution of the traditional Data Lake. Data Lakehouse implements all the capabilities of a Data Lake plus ACID transactions. You can find more information about Lakehouses in this link.
Usually in a Data Lakehouse or a Data Lake you can find different zones for storing data. The number of zones that you can find depends on how you want to classify your data. How to create and classify the data in your Data Lake or Lakehouse is a complicated matter that will be treated in a future article. The Data Lake is the first place where the consumed data is stored. Sometimes it is just meaningless raw data.
Data Warehouse: many times you will need to implement star schemas for creating data marts in order to make easy for users the use of the stored data. Here, users can find meaningful data for creating dashboards, machine learning products or any other thing that users require.
Metastore: data is stored in the blob storage, if you want to use this data as if it was stored in a traditional database we need an element for translating schemas and table names to folders and files in the blob storage. This translation is made by the metastore.
This article does not try to deeply explain how the above three elements work. Those explanations will be left out for other future articles.
Current situation (environment isolation)
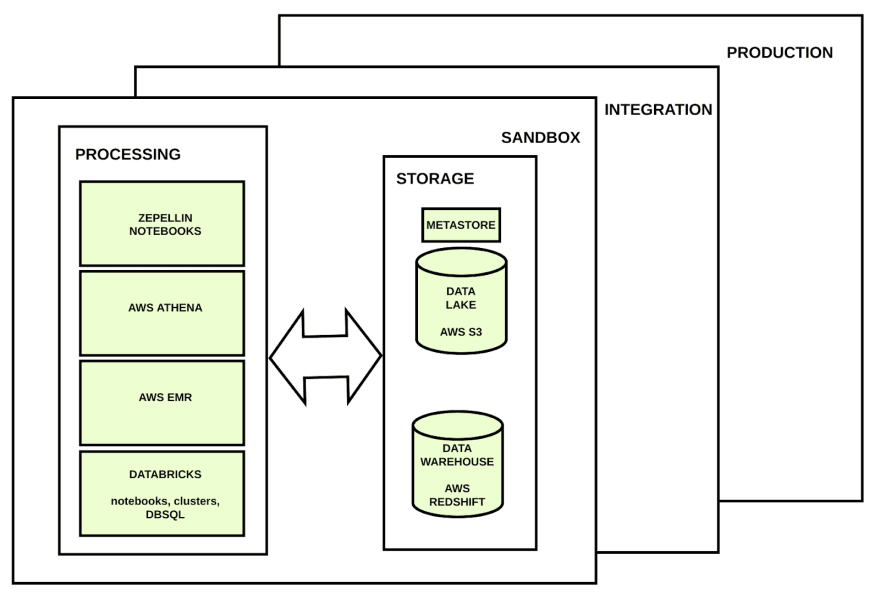
If you want users to create data products as fast as possible, you will need to create at least one environment where these users can mess around with the stored data. In this isolated environment they will be able to break and change as many things as they want. Our production environment must be isolated from this and other environments because we do not want to break productive processes. Different and isolated environments will exist. These environments contain the same processing and storage layers but these layers are isolated in their own environments. So notebooks in the sandbox environment can not break data stored in the storage layer from the production environment.
The problem with data.
Data engineers, data analysts, data scientists and data people in general who work with big data require huge amounts of data in order to implement, develop and test their applications. These applications could be ETLs, ELTs, notebooks, dashboards, etc, etc.
In a healthy system, these users should be able to work in a safe environment where they can be sure that they do not break anything that already works in production when trying to implement new solutions. We need to create isolated environments. These environments could be sandbox, integration, production environment, etc, etc.
The problem with having different and isolated environments is that, in no productive environments, the amount of data will probably be much lower than the one that will be generated in production.
So now, we face the following problem: we want users to be able to work with huge amounts of data in an easy and fast way, but we want them to do that in isolated environments from the productive one because we do not want them to break anything.
The solution 1.
Remember that we have data sources, and those data sources must be connected to our different and isolated environments. We could ask those data sources to send us the same amount of data as they are sending in the productive environment.
The problem with this solution is that, in many cases, those data sources have their own no preproductive environments and it is impossible for them to generate the same amount of data in the rest of the environments as in the production environment. Also, they will not be willing to connect our own no preproductive environments to their productive ones because we could break their environments.

This solution in many cases will not work.
The solution 2.
Another solution could be as simple as implementing a job for copying data from the storage located in the productive environment to the no productive one. For example, a Jenkins job.
The problem with this solution is that copying huge amounts of data is not fast and also, the job can break easily for multiple reasons (not having the right permissions, the right amount of memory for moving all the required data, etc, etc)

This solution does not ease the development of new applications because the copying process is slow, sometimes will not work, and data is not immediately available.
The solution 3.
What our users need is to have access to data generated in the production environment from the tools running in the no productive environments. We need to provide a solution where applications like notebooks running in for example the integration environment can access the storage located in the productive one.

This solution will work in all cases. This is the solution that we are going to explain in this article focusing on the component related to the Data Lake. In a next article we will explain the same solution implemented in a Data Warehouse.
Data Lake, AWS S3.

Notebooks, Spark jobs, clusters, etc, etc, run in Amazon virtual servers called EC2.
These virtual servers require permissions for accessing AWS S3. These permissions are given by IAM Roles.
We will be working with Amazon Web Services. As we said before, because the amount of data to be stored is huge, we can not use HDD or SSD data storages, we need something cheaper. In this case we will be talking about AWS S3.
Also, in order to make easy the use of the Data Lake, we can implement metastores on the top of it. For example, Hive Metastore or Glue Catalog. We are not going to explain deeply how a metastore works, that will be left for another future article.
When using a notebook (for example a Databricks notebook) and having a metastore, the first thing that the notebook will do is to ask the metastore where the data is physically located. Once the metastore responds, the notebook will go to the path in AWS S3 where the data is stored using the permissions given by the IAM Role.
Data Lake, integration and production environments.
In the integration environment we have two options for working with the data. With or without using a metastore.

In the production environment we have the exact same system but isolated from the integration environment. In production we find the exact same two options.
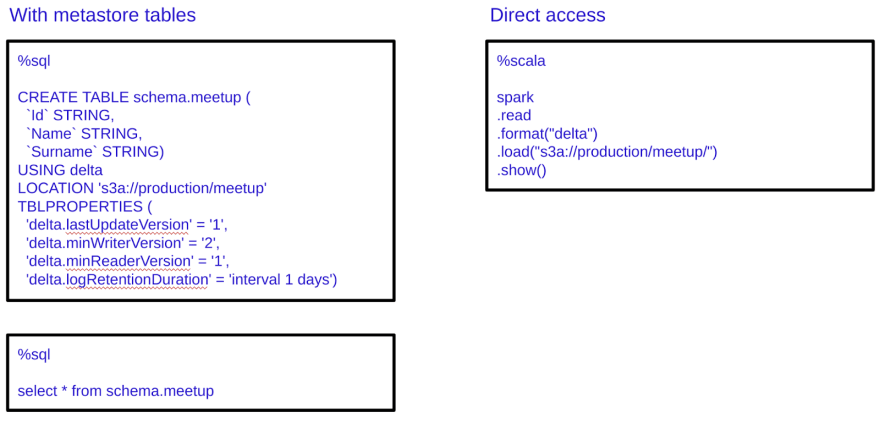
As you can see, the metastore allows us to use the data located in the Data Lake as it was a normal database. Also, we can see that the metastore does not store data but the metadata that allows us to find the real stored data in AWS S3. With the metastore, users can have access to the data in the Data Lake in an easier way because they can use SQL statements as they do in any other database.
Data Lake, sharing data.
When users run their notebooks or any other application from the integration environment they need to have access to the production data located in the storage zone of the production environment.
Remember that those notebooks and applications run in Amazon virtual servers called Amazon EC2 instances, and for accessing the data located in AWS S3 they use IAM Roles (the permissions for accessing the data) We can modify the IAM Role in the (for example) integration environment in order to allow EC2 instances to access data located in the productive storage zone.

IAM Role configuration.
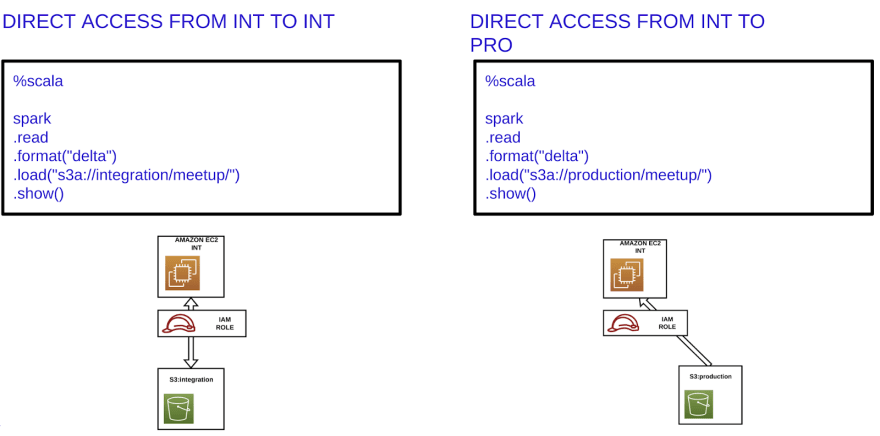
For example, for being able to access to S3 integration and production folders we can configure the IAM Role in the following way:
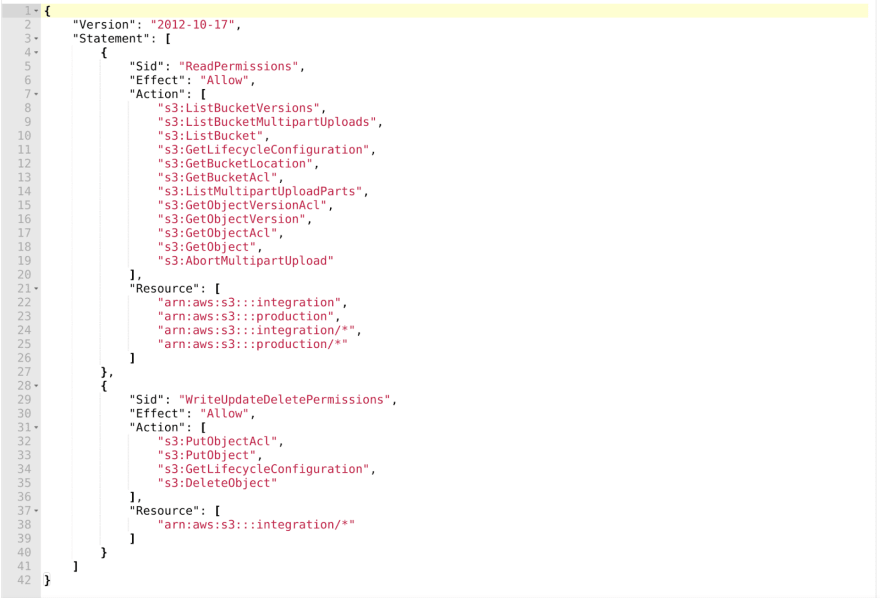
Any application running on a machine with this IAM Role can read data from production and integration and can only modify the data located in the integration environment. So the productive data is not modified in any way.
Applying the solution.
Once we have applied the above configuration in the IAM Role, users have direct access to the data located in the productive environment, for example from the integration environment.
Can we do it better?
With this configuration users, from for example their notebooks, can access the productive data and work with it without being able to modify it. But, we know, by means of a metastore, users can access the data even in an easier way. So the question is: can we use metastores with this solution?
We will see how to do it in the next section of this article.
Data Lake, sharing data. Waggle Dance.
Waggle Dance is a request routing Hive metastore proxy that allows tables to be concurrently accessed across multiple Hive deployments.
In short, Waggle Dance provides a unified endpoint with which you can describe, query, and join tables that may exist in multiple distinct Hive deployments. Such deployments may exist in disparate regions, accounts, or clouds (security and network permitting).
For further information follow this link: https://github.com/ExpediaGroup/waggle-dance
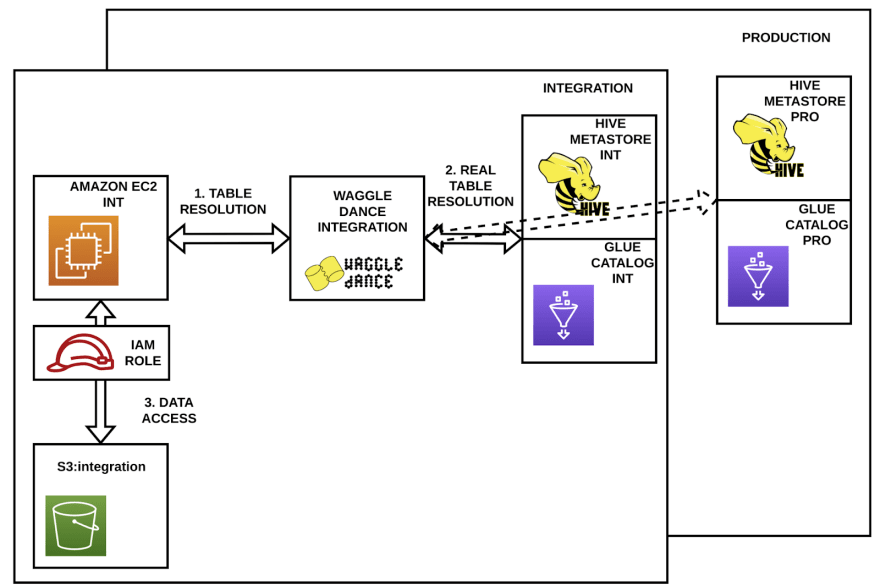
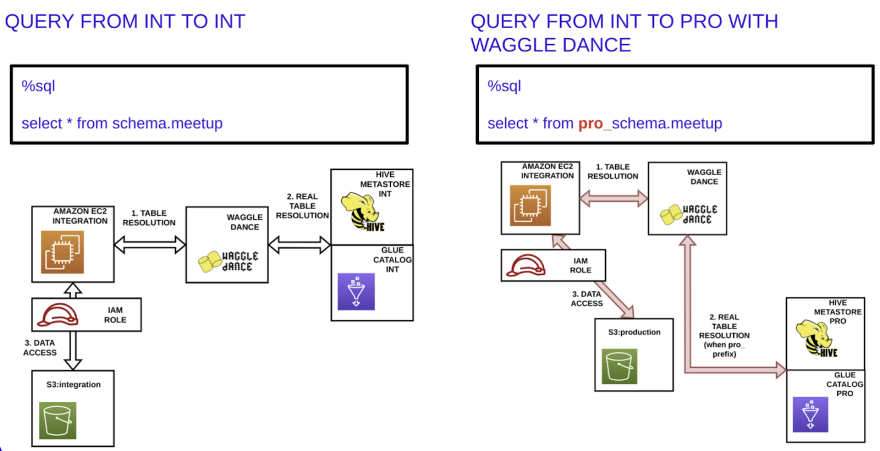
Now, when asking for some table from the integration environment, and based on some configuration, the Waggle Dance living in the integration environment decides if the metastore to be asked resides either in the production or integration environment.
For example, this configuration could be based on some prefix. In the below example, the pro_prefix. When using this prefix the data to be retrieved will be located in the production environment instead of the integration one.
Conclusion.
Through this article we have covered how to resolve the following problems in a Data Lake implemented in AWS S3:
Users (data engineers, data analysts and data scientists) need to work in pre-production environments with the same amount of data as in production.
We want to have different and isolated environments: integration, production, etc.
Users need to work with the data in the easiest possible way.
Stay tuned for the next article about how to share data with AWS Redshift and many others that will follow about how to implement your own Data Platform with success.
I hope this article was useful. If you enjoy messing around with Big Data, Microservices, reverse engineering or any other computer stuff and want to share your experiences with me, just follow me.


















