Introduction.
This article is the second part of the first episode about how to build your own data platform. To catch up, follow this link: https://dev.to/adevintaspain/how-to-build-your-own-data-platform-4l6c
As a short recap, remember that for creating a data platform many parts are involved. For this first episode we are only focusing on the component that we called storage layer. In the storage layer we could find the Lakehouse or Data Lake and the Data Warehouse. In the previous article we talked about how to share data in the Data Lake, in this second part we will be talking about the same but in the Data Warehouse.
Storage layer.
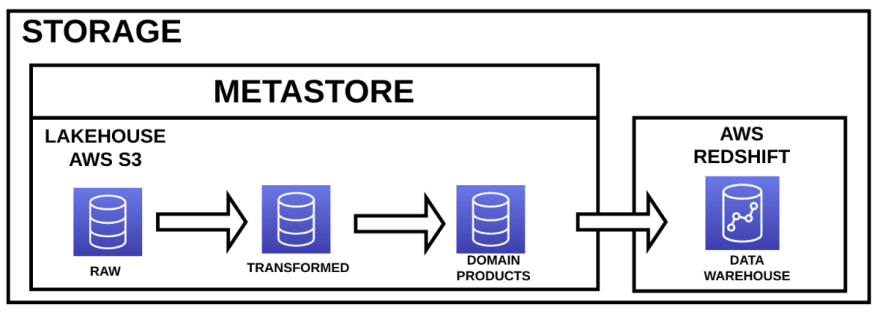
You can see in this diagram three different elements:
Data Lakehouse: we already talked about it in the previous article.
Metastore: also we explained it in the last article. We will talk about it more deeply in the coming articles.
Data Warehouse: many times you will need to implement star schemas for creating data marts. Here, users can find meaningful data for creating dashboards, machine learning products or any other thing that users require. In this case, the Data Warehouse will be implemented on AWS Redshift.
Current situation (environment isolation)
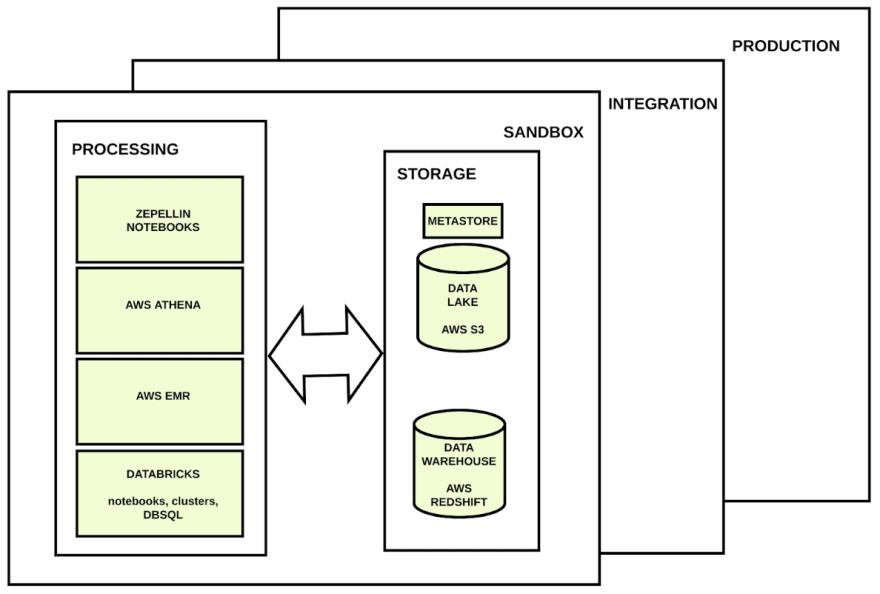
Remember that if you want users to create data products as fast as possible, you will need to create at least one environment where these users can mess around with the stored data. In this isolated environment they will be able to break and change as many things as they want. Our production environment must be isolated from this and other environments because we do not want to break productive processes.
The problem with data.
We want users to be able to work with huge amounts of data in an easy and fast way, but we want them to do that in isolated environments from the productive one because we do not want them to break anything.
Data Warehouse, AWS Redshift.
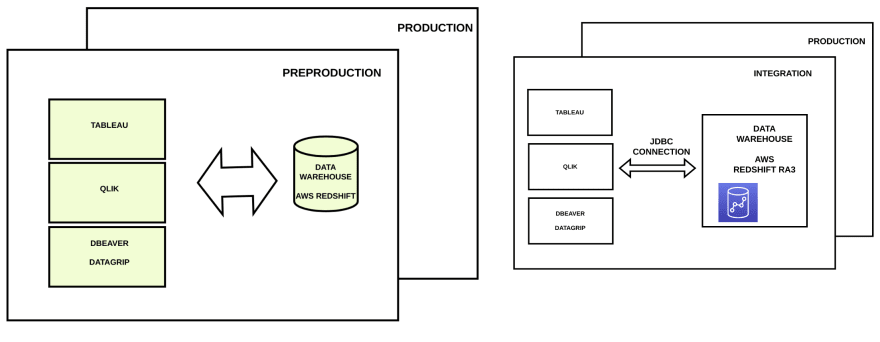
All the environments have the same components but isolated one of each other.
The Data Warehouse is implemented on the top of AWS Redshift. Not many years ago a new service was released by Amazon called AWS Redshift RA3. What makes RA3 different from the old Redshift is that, in the new implementation, computation and storage are separated. Before having RA3, if users needed more storage capabilities, more computation had also to be paid even if computation was not a problem. And in the opposite way, when users needed more computation capabilities, more storage had to be paid. So, Redshift costs were typically high.
Since the release of AWS Redshift RA3, because storage and computation are separated, users can decide if they want to increase either their storage or computational capabilities and only pay for what they need.
We will be using AWS Redshift RA3. Here you can find some useful links that explain further what are AWS Redshift and AWS Redshift RA3:
- https://docs.aws.amazon.com/redshift/latest/mgmt/welcome.html
- https://aws.amazon.com/blogs/big-data/use-amazon-redshift-ra3-with-managed-storage-in-your-modern-data-architecture/
Data Warehouse, Redshift RA3.

With Redshift RA3 storage is located under the component called Redshift Managed Storage located in AWS S3. As you can see on the above diagram, compute nodes are separated from the storage.
You can find more information about RA3 in the following link: https://aws.amazon.com/blogs/big-data/use-amazon-redshift-ra3-with-managed-storage-in-your-modern-data-architecture/
Data Warehouse, integration and production environments.
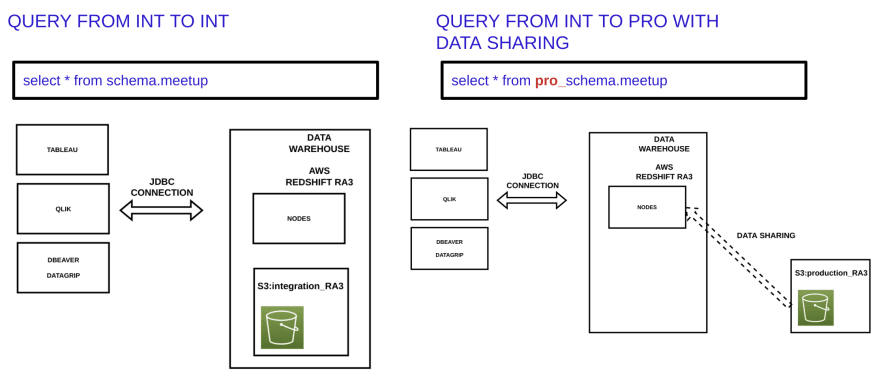
In the integration environment we work with data as you can see in the pictures below.

In the production environment we have the exact same system but isolated from the integration environment. In production we find the exact same statements.

Data Warehouse, sharing data.
AWS Redshift RA3 includes something called data sharing. With data sharing we can access with read only permissions to Redshift data located in other Redshift servers and even in different accounts or environments.
Data sharing provides instant, granular, and high-performance access without copying data and data movement. You can query live data constantly across all consumers on different RA3 clusters in the same AWS account, in a different AWS account, or in a different AWS Region. Queries accessing shared data use the compute resources of the consumer Amazon Redshift cluster and don’t impact the performance of the producer cluster.
- https://aws.amazon.com/blogs/big-data/use-amazon-redshift-ra3-with-managed-storage-in-your-modern-data-architecture/
- https://aws.amazon.com/blogs/big-data/announcing-amazon-redshift-data-sharing-preview/
Data Sharing.
With Data Sharing, we can configure the AWS Redshift in the integration environment for accessing the storage of the AWS Redshift located in the production environment.
You can find more information about it in the following link: https://aws.amazon.com/blogs/big-data/sharing-amazon-redshift-data-securely-across-amazon-redshift-clusters-for-workload-isolation/

Data Sharing, implementation.
In order to create a data sharing between the integration and production AWS Redshift servers, you can follow the next steps.
AWS Redshift RA3, production environment, statements to run:
- CREATE DATASHARE meetup_sharing;
- GRANT USAGE ON DATASHARE meetup_sharing TO ACCOUNT 'INTEGRATION';
- ALTER DATASHARE meetup_sharing ADD SCHEMA schema;
- ALTER DATASHARE meetup_sharing SET INCLUDENEW = TRUE FOR SCHEMA schema;
AWS Redshift RA3, integration environment, statements to run:
- CREATE DATABASE meetup_pro FROM DATASHARE meetup_sharing OF ACCOUNT 'PRODUCTION'
- CREATE EXTERNAL SCHEMA IF NOT EXISTS pro_schema FROM REDSHIFT DATABASE 'meetup_pro' SCHEMA 'schema';
- GRANT USAGE ON SCHEMA pro_schema TO schema;
With the above configuration, when using the pro_ prefix in the integration environment, we will be accessing data located in the production one. This access is read only, so we can not modify that data in any way.
Conclusion.
Through this article we have covered how to resolve the following problems in a Data Lake implemented in AWS S3:
- Users (data engineers, data analysts and data scientists) need to work in pre-production environments with the same amount of data as in production.
- We want to have different and isolated environments: integration, production, etc.
- Users need to work with the data in the easiest possible way.
Stay tuned for the next article about how to implement your own Data Platform with success.
I hope this article was useful. If you enjoy messing around with Big Data, Microservices, reverse engineering or any other computer stuff and want to share your experiences with me, just follow me.


















