
This article was originally posted on Crawlbase Blog.
Explore the intricacies of scraping Amazon reviews with our detailed guide, providing a robust methodology that incorporates JavaScript and the Crawlbase Crawling API, ensuring an unimpeded, successful data extraction process. Navigating through the rich tapestry of Amazon’s customer feedback, this hands-on approach guarantees a wealth of data and a stream of invaluable insights crucial for market research, product refinement, and competitive analysis. Enrich your skills and toolset with this comprehensive walkthrough, and transform Amazon reviews into a strategic asset, paving the way for informed decision-making and astute market positioning.
I. Why Scrape Amazon Product Reviews

In the realm of e-commerce, product reviews serve as a treasure map, guiding you through the intricate landscape of customer preferences and opinions. Scraping these reviews is akin to unlocking a door to their unfiltered thoughts and emotions regarding products. However, the significance of these reviews extends far beyond mere insights; they are indispensable for conducting market research, driving product enhancements, and conducting competitive analyses.
Unlocking Market Insights
Amazon product reviews are like a treasure map of what customers love and what they don't. Scraping these reviews gives you a sneak peek into their thoughts and feelings about products. Like eavesdropping on a conversation where customers spill the beans on what makes them happy or frustrated.
Supercharge Your Product
Imagine having a magic crystal ball that shows you where your product could be even better. Amazon reviews are like that crystal ball. They help you spot common issues and discover what needs improvement. It's similar to having customers as your product development advisors, telling you how to make things even more awesome.
Spy on the Competition
Want to be the king or queen of the marketplace? Amazon reviews let you play detective. You can see how your product stacks up against competitors. It's like studying your rivals' playbooks and finding ways to score more touchdowns.
When you scrape Amazon reviews, you're not just collecting data; you're gaining a competitive edge and tapping into valuable customer insights. It's a secret weapon for success in the world of e-commerce.
II. How to Avoid Getting Blocked by Amazon
While the ability to scrape Amazon reviews offers a wealth of valuable data, it has its challenges. The digital landscape of e-commerce comes with its own set of rules, and Amazon, one of the field's giants, is no exception. Scraping its pages is more complex than it might seem.
Preventing your Amazon review scraper from encountering blocks while scraping product reviews is essential to maintain the reliability and continuity of your data collection process. Here are some effective strategies:
- User-Agent Headers: Amazon can detect automated scraping by checking the User-Agent header in HTTP requests. To avoid detection, use a web crawling tool or library that allows you to set user-agent headers to mimic a web browser. This makes your requests appear more like those of a typical user.
- Request Rate Limiting: Implement a delay between your scraping requests. Overwhelming Amazon's servers with rapid and frequent requests can trigger their security mechanisms. By adding delays, you simulate a more human-like browsing pattern, reducing the risk of detection.
- IP Rotation and Proxy Servers: Rotating IP addresses or using proxy server services can help prevent IP-based blocking. When scraping at scale, using a pool of rotating IPs or proxies is advisable. This way, Amazon won't identify a consistent pattern from a single IP address, making it harder for them to block your access.
- Respect robots.txt: Always respect the rules defined in Amazon's "robots.txt" file. This file specifies which parts of the website can and cannot be scraped. Scraping disallowed areas may result in your scraper being blocked, so it's important to review and adhere to these rules.
- Monitoring and Adaptation: Amazon frequently updates its website structure and security measures. To stay ahead, monitor Amazon's website for structural changes and adapt your scraper accordingly. Web scraping libraries like BeautifulSoup and Scrapy can help you adjust your scraper when the HTML structure evolves.
It's important to note that while these strategies can help prevent your scraper from getting blocked, they may require a significant amount of effort and expertise to implement effectively.
Crawlbase Can Handle It All
Managing all these aspects of web scraping can be a challenging and time-consuming task. That's where Crawlbase Crawling API shines. Crawlbase is designed to handle the complexities of web scraping, including setting user-agent headers, managing request rates, rotating IP addresses, respecting robots.txt rules, and monitoring website changes, making it the perfect tool to scrape Amazon reviews.
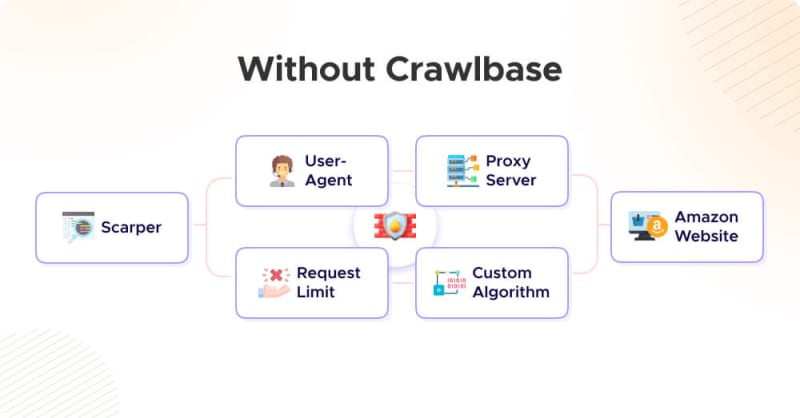

By using the Crawlbase API, you can focus on extracting valuable data from Amazon reviews without the worry of being blocked, as Crawlbase takes care of these challenges for you. This makes Amazon scraping with Crawlbase an excellent choice for your project, ensuring smooth and reliable data extraction.
III. Understanding Amazon Product Reviews Page HTML

Before we explore into writing code for our Amazon review scraper, it's essential to grasp the structure of Amazon's product review pages in HTML. This understanding is the foundation for a successful scraping operation, as it enables you to precisely locate and extract the data you need.
Amazon's product review pages are structured with various HTML elements, each holding valuable information. Here are the key elements to be aware of:
Review Containers
Every customer review on Amazon resides within a review container. These containers encapsulate the reviewer's comments, ratings, and other relevant details. Think of them as neatly packaged bundles of feedback.
Reviewer Information
Amazon provides details about reviewers, including their usernames, the date of the review, and occasionally additional information such as their location. This information helps you understand the context of the review.
Ratings and Stars
Ratings and star ratings are prominently displayed on Amazon's product review pages. These visual cues convey the customer's level of satisfaction with the product, making them crucial data points.
Review Text
At the heart of each review lies the review text itself. Here, customers share their experiences, opinions, and feedback on the product. This is where you'll find valuable insights and sentiments.
Pagination
For products with a large number of reviews, Amazon employs pagination to divide them across multiple pages. Understanding how pagination is structured in HTML is vital for scraping all reviews effectively. It's like figuring out how to turn the pages of a book to read the entire story.
As we proceed in this journey of building an Amazon product review scraper, keep these elements in mind. They are the building blocks of our scraping strategy.
IV. How to Scrape Amazon Reviews
Step 1. Preparing Your Workspace: Prerequisites and Environment Setup
Now, let's get down to business and make sure your workspace is ready for building an Amazon review scraper. Before we proceed into coding, here's a checklist to ensure you have everything you need:
Node.js Installed
Make sure you have Node.js installed on your computer. If you don't have it yet, you can download it from their Node.js Official Website. Node.js serves as the runtime environment that enables us to run JavaScript code on your machine.
Crawlbase API's JavaScript Token
To connect with the Crawlbase API, you'll require an API token. You can obtain the token by signing up on Crawlbase. Once you have an account, go to the account dashboard and save your JavaScript token. Consider this token as your access key to the web data treasure.
Basic Knowledge of JavaScript and npm
Having some familiarity with JavaScript and npm (Node Package Manager) will be extremely beneficial as we proceed. If you're new to JavaScript, don't worry; we'll provide detailed guidance through the code step by step. Npm will assist us in managing packages and dependencies throughout the project.
By ensuring you have these elements in place, you're setting yourself up for a smooth and successful experience in learning how to scrape Amazon reviews.
Setting Up the Environment
Now that we're ready to start our Amazon product review scraping project, let's begin by preparing our coding environment. This step is essential as it forms the basis for the work ahead.
Open your command-line interface, which could be the Command Prompt (Windows), Terminal (macOS and Linux), or a similar terminal application and navigate to the directory where you want to create your project.
Once you're inside your project directory in the terminal, it's time to create your code file. Execute the following command:
touch index.js & npm init -y
Next, we’ll use the Crawlbase Node library for easier integration. Install the library by executing the line below:
npm install crawlbase
This command uses npm (Node Package Manager) to fetch and install the Crawlbase library, which we'll use to interact with the Crawlbase API. The library provides convenient functions for your JavaScript code to make web scraping a breeze.
If you're all set, let's move on to the next step: writing the code to extract Amazon product reviews.
Step 2. Retrieving Amazon Product Reviews
In this section, we’re ready to dive into the code that fetches Amazon product reviews using the Crawlbase's Crawling API. Here's the code followed by its explanation:
const { CrawlingAPI } = require('crawlbase'),
api = new CrawlingAPI({ token: 'CRAWLBASE_JS_TOKEN' }),
amazonReviewsURL =
'https://www.amazon.com/Meta-Quest-Pro-Oculus/product-reviews/B09Z7KGTVW/?reviewerType=all_reviews';
async function fetchReviews(url, reviews = []) {
try {
const response = await api.get(url, {
scraper: 'amazon-product-reviews',
});
if (response.statusCode === 200) {
const data = response.json.body;
console.log(data);
} else {
throw new Error(`API request failed with status: ${response.statusCode}`);
}
} catch (error) {
console.error(`API call failed: ${error.message}`);
}
}
// Call the fetchReviews function to start the scraping process
fetchReviews(amazonReviewsURL);
- Import Required Modules: The code begins by importing the necessary modules from the "Crawlbase" library. It imports the CrawlingAPI class, which will be used to interact with the Crawlbase API.
- Initialize the API: It initializes the Crawlbase API by creating an instance of the
CrawlingAPIclass and passing your Crawlbase JavaScript token as a configuration parameter. Replace"CRAWLBASE_JS_TOKEN"with your actual token. - Define the Amazon Reviews URL: The URL of the Amazon product reviews page is stored in the
amazonReviewsURLvariable. This URL points to the specific product reviews page you want to scrape. - Create the
fetchReviewsFunction: This function is responsible for fetching Amazon product reviews using the Crawlbase API. It takes the URL as an argument and an optionalreviewsarray to store the scraped data. - Sending the GET Request: Inside the
tryblock, an asynchronous GET request is sent to the Crawlbase API usingapi.get(url, options). Thescraperoption is set to"amazon-product-reviews"to indicate that you want to use the Amazon product reviews scraper provided by Crawlbase. - Handling the Response: If the API responds with a status code of 200 (OK), the code extracts the scraped data from the response JSON and logs it to the console. You can modify this part of the code to save the data to a file or perform other actions.
- Error Handling: If the response status code is not 200 or if any error occurs during the API call, the code catches the error and logs an error message to the console.
- Calling the Function: Finally, the fetchReviews function is called with the
amazonReviewsURLas an argument to start the scraping process.
This code sets up the foundation to scrape Amazon reviews using the Crawlbase library and API. It simplifies the scraping process by leveraging Crawlbase's pre-built scraper for Amazon product reviews, eliminating the effort needed to build a custom parser.
Code Execution
Now, you can run the code by using the node command followed by the name of the JavaScript file, which is index.js in this case. Type the following command and press Enter:
node index.js
The code will log the scraped data or any error messages to the terminal. Carefully review the output to ensure that the scraping process is working as expected.
Step 3. Scraping All reviews using Pagination
Understanding Pagination in Web Scraping
Pagination is a common technique used on websites to split large amounts of content, such as product reviews, into smaller, more manageable sections or pages. Each page typically contains a subset of the total content, and users can navigate between pages to access different portions of the data.
In the context of web scraping, pagination becomes relevant when you're dealing with websites that display data across multiple pages. For example, Amazon product reviews are often spread across several pages. To retrieve all the reviews, you need to navigate through these pages systematically, fetching the data from each page one after another.
Using Amazon Pagination for Scraping
Amazon, like many other websites, uses a pagination system to organize its product reviews. This means that if you want to scrape Amazon reviews with multiple pages, you'll need to follow a series of page links to access and retrieve data from each page of reviews.
To get a better grasp, you can observe the URL examples below to see how Amazon handles pagination:
Main review page:
https://www.amazon.com/Meta-Quest-Pro-Oculus/product-reviews/B09Z7KGTVW/?reviewerType=all_reviews
Second page:
https://www.amazon.com/Meta-Quest-Pro-Oculus/product-reviews/B09Z7KGTVW/?reviewerType=all_reviews&pageNumber=2
Now, let's examine the provided code and explain how it achieves this pagination:
const { CrawlingAPI } = require('crawlbase'),
api = new CrawlingAPI({ token: 'CRAWLBASE_JS_TOKEN' }), // Replace it with your JS Request token
amazonReviewsURL =
'https://www.amazon.com/Meta-Quest-Pro-Oculus/product-reviews/B09Z7KGTVW/?reviewerType=all_reviews';
async function fetchReviews(url, reviews = []) {
try {
const response = await api.get(url, {
scraper: 'amazon-product-reviews',
ajax_wait: true,
page_wait: 3000,
});
// Checking if the response status is 200
if (response.statusCode === 200) {
const data = response.json.body;
// Checking if the pagination number exists in the response
const nextPageNumber = data.pagination.nextPage;
console.log(reviews.length, 'Response Reviews');
if (nextPageNumber) {
// Call the function recursively with the next page URL
const nextPageUrl = `${amazonReviewsURL}&pageNumber=${nextPageNumber}`;
return fetchReviews(nextPageUrl, reviews.concat(data.reviews));
} else {
console.log('Reached the last page.', reviews.length);
return reviews.concat(data.reviews);
}
} else {
// Handle empty data response
throw new Error(`API request failed with status: ${response.statusCode}`);
}
} catch (error) {
console.log(`API call failed fetching again URL: ${url}`);
// Retry the API call with the same URL
return fetchReviews(url, reviews);
}
}
async function fetchAllReviews() {
try {
const reviews = await fetchReviews(amazonReviewsURL);
console.log('Total Reviews:', reviews.length);
} catch (error) {
console.error(`Recursive API calls failed: ${error}`);
}
}
// Start the recursive API calls to fetch Amazon Product Reviews
fetchAllReviews();
- Crawling and Scraping:
- The code defines a function called fetchReviews, which is responsible for scraping Amazon product reviews.
- It initially makes a request to the Amazon reviews URL using the Crawlbase API. The ajax_wait and page_wait options are set to ensure proper loading and waiting for the page elements.
- It checks if the API response status code is 200 (indicating success) and proceeds to extract Amazon reviews from the response.
- Pagination Logic:
- Inside the function, it checks if there's a nextPageNumber in the data response. If this value exists, it means there's another page of reviews.
- If there's a next page, it constructs the URL for that page and makes a recursive call to fetchReviews with the new URL. It also concatenates the data from the current page with the accumulated reviews array.
- Handling the Last Page:
- When there's no next page (i.e., nextPageNumber is not present), it logs that the last page has been reached and returns the concatenated reviews array.
- Error Handling:
- The code includes error handling to manage cases where the API call may fail or return empty data. If there's an error, it logs the error message and retries the API call with the same URL.
This code effectively navigates through the paginated Amazon product reviews, making recursive calls to fetch and accumulate data from each page until it reaches the last page. It's a robust way to ensure that you retrieve all available reviews for your chosen product.
Here is the example response:

Step 4. Storing the Data
After successfully scraping Amazon product reviews, the next crucial step is to store this valuable data for analysis, future reference, or any other purposes you may have in mind. Storing data is an essential part of the web scraping process because it preserves the results of your efforts for later use.
Using the fs Module in Node.js
To save the scraped reviews, we'll utilize the fs (file system) module in Node.js. The fs module is a built-in module that allows us to interact with the file system on our computer. With it, we can create, read, write, and manage files. In our case, we'll use it to write the scraped reviews to a JSON file.
In the upcoming section, we'll provide you with the code for saving the scraped reviews to an amazon_reviews.json file and explain how it works. This step will ensure that you have a structured and accessible record of the reviews you've collected, enabling you to make data-driven decisions or conduct further analysis as needed.
const { CrawlingAPI } = require('crawlbase'),
fs = require('fs'), // Import the 'fs' module
api = new CrawlingAPI({ token: 'CRAWLBASE_JS_TOKEN' }), // Replace it with your JS Request token
amazonReviewsURL =
'https://www.amazon.com/Meta-Quest-Pro-Oculus/product-reviews/B09Z7KGTVW/?reviewerType=all_reviews';
async function fetchReviews(url, reviews = []) {
try {
const response = await api.get(url, {
scraper: 'amazon-product-reviews',
ajax_wait: true,
page_wait: 3000,
});
// Checking if the response status is 200
if (response.statusCode === 200) {
const data = response.json.body;
// Checking if the pagination number exists in the response
const nextPageNumber = data.pagination.nextPage;
console.log(reviews.length, 'Response Reviews');
if (nextPageNumber) {
// Call the function recursively with the next page URL
const nextPageUrl = `${amazonReviewsURL}&pageNumber=${nextPageNumber}`;
return fetchReviews(nextPageUrl, reviews.concat(data.reviews));
} else {
console.log('Reached the last page.', reviews.length);
return reviews.concat(data.reviews);
}
} else {
// Handle empty data response
throw new Error(`API request failed with status: ${response.statusCode}`);
}
} catch (error) {
console.log(`API call failed fetching again URL: ${url}`);
// Retry the API call with the same URL
return fetchReviews(url, reviews);
}
}
async function fetchAllReviews() {
try {
const reviews = await fetchReviews(amazonReviewsURL);
console.log('Total Reviews:', reviews.length);
fs.writeFileSync('amazon_reviews.json', JSON.stringify({ reviews }, null, 2));
} catch (error) {
console.error(`Recursive API calls failed: ${error}`);
}
}
// Start the recursive API calls to fetch Amazon Product Reviews
fetchAllReviews();
- Imports: We import necessary modules, including the Crawlbase library for web scraping (CrawlingAPI) and the built-in Node.js fs module for file operations (fs).
- Fetching Amazon Reviews: The fetchReviews function is responsible for sending requests to the Crawlbase API to scrape Amazon product reviews. It handles pagination by recursively calling itself for each next page of reviews until there are no more pages.
- Handling Errors: It includes error handling to deal with situations where the API request fails or returns empty data. In such cases, it retries the same URL.
- Storing Reviews: The fetchAllReviews function orchestrates the process. After fetching all reviews, it saves them to an "amazon_reviews.json" file using fs.writeFileSync. The reviews are stored in JSON format for easy access and analysis.
- Initiating the Process: The script starts by calling fetchAllReviews, which kicks off the process of fetching and storing Amazon product reviews.
In summary, this code fetches Amazon product reviews, handles pagination, and saves the collected data in a JSON file for future use. It's an efficient way to retain and analyze the scraped information.
Execute the code. Once the code finishes running, it will display the total number of reviews fetched. You can then check the "amazon_reviews.json" file in the same directory to access the scraped data.
Here is an example JSON response:
{
"reviews": [
{
"reviewID": "RKQEU6WKR8K25",
"reviewerName": "Grrgoyl",
"reviewerLink": "https://www.amazon.com/gp/profile/amzn1.account.AHRET2Q2B5UOD2H4BENDQRLWUOCA/ref=cm_cr_arp_d_gw_btm?ie=UTF8",
"reviewLink": "https://www.amazon.com/gp/customer-reviews/RKQEU6WKR8K25/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=B09Z7KGTVW",
"reviewRating": "4.0 out of 5 stars",
"reviewDate": "Reviewed in the United States on August 2, 2023",
"reviewDetailsTop": [
{
"name": "Style",
"value": "Quest Pro System"
}
],
"reviewTitle": "No regret",
"reviewText": "Am I crazy/dumb for buying the Pro just months before the Quest 3 launches? I don't think I am. My 256 gb Quest 2 is in danger of running out of space.",
"reviewVotes": "11 people found this helpful",
"reviewVerifiedPurchase": true,
"reviewCommentCount": 0,
"media": {
"images": [],
"video": ""
}
},
{
"reviewID": "R5MWA1QYQQ08I",
"reviewerName": "tottytheanimator",
"reviewerLink": "https://www.amazon.com/gp/profile/amzn1.account.AGHDQ5LDPFJWGULE6KCFUCIMVOVA/ref=cm_cr_arp_d_gw_btm?ie=UTF8",
"reviewLink": "https://www.amazon.com/gp/customer-reviews/R5MWA1QYQQ08I/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=B09Z7KGTVW",
"reviewRating": "4.0 out of 5 stars",
"reviewDate": "Reviewed in the United States on April 8, 2023",
"reviewDetailsTop": [
{
"name": "Style",
"value": "Quest Pro System"
}
],
"reviewTitle": "Wait, but if you can't, Nice.",
"reviewText": "I got myself a M.Quest 2 to use Quill, I am an animator, and while Steam has some art tools; some of them okay.",
"reviewVotes": "27 people found this helpful",
"reviewVerifiedPurchase": true,
"reviewCommentCount": 0,
"media": {
"images": [],
"video": ""
}
},
{
"reviewID": "R1SQONPI32TSA3",
"reviewerName": "Damian",
"reviewerLink": "https://www.amazon.com/gp/profile/amzn1.account.AG7XUXY3DP5HLZMUXI5FRHGIUM2A/ref=cm_cr_arp_d_gw_btm?ie=UTF8",
"reviewLink": "https://www.amazon.com/gp/customer-reviews/R1SQONPI32TSA3/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=B09Z7KGTVW",
"reviewRating": "3.0 out of 5 stars",
"reviewDate": "Reviewed in the United States on November 1, 2022",
"reviewDetailsTop": [
{
"name": "Style",
"value": "Quest Pro System"
}
],
"reviewTitle": "Extremely Overpriced. Excellent Comfort. Very Poor Display.",
"reviewText": "I recently purchased this to upgrade from my first gen Oculus Rift and first gen HTC Vive",
"reviewVotes": "386 people found this helpful",
"reviewVerifiedPurchase": true,
"reviewCommentCount": 0,
"media": {
"images": [],
"video": ""
}
},
{
"reviewID": "R1P51LFI4UT2BH",
"reviewerName": "Turtle",
"reviewerLink": "https://www.amazon.com/gp/profile/amzn1.account.AGAM4YMLO2I3H573MRATCQBVH64A/ref=cm_cr_arp_d_gw_btm?ie=UTF8",
"reviewLink": "https://www.amazon.com/gp/customer-reviews/R1P51LFI4UT2BH/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=B09Z7KGTVW",
"reviewRating": "3.0 out of 5 stars",
"reviewDate": "Reviewed in the United States on March 11, 2023",
"reviewDetailsTop": [
{
"name": "Style",
"value": "Quest Pro System"
}
],
"reviewTitle": "Save your money",
"reviewText": "Updated review - save your $ buy the regular Quest 2. Maybe wait on the 3. The Pro has some fantastic features",
"reviewVotes": "39 people found this helpful",
"reviewVerifiedPurchase": true,
"reviewCommentCount": 0,
"media": {
"images": [],
"video": ""
}
},
{
"reviewID": "RR3IJVMY99Y92",
"reviewerName": "BC",
"reviewerLink": "https://www.amazon.com/gp/profile/amzn1.account.AHVFQVUULJHUYMXXEK2RVE4EZPLQ/ref=cm_cr_arp_d_gw_btm?ie=UTF8",
"reviewLink": "https://www.amazon.com/gp/customer-reviews/RR3IJVMY99Y92/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=B09Z7KGTVW",
"reviewRating": "4.0 out of 5 stars",
"reviewDate": "Reviewed in the United States on August 19, 2023",
"reviewDetailsTop": [
{
"name": "Style",
"value": "Light Blocker"
}
],
"reviewTitle": "Enhance Your VR Experience with the Meta Quest Pro Full Light Blocker!",
"reviewText": "I recently purchased the Meta Quest Pro Full Light Blocker to take my VR gaming sessions to the next level, and I'm quite satisfied.",
"reviewVotes": "One person found this helpful",
"reviewVerifiedPurchase": true,
"reviewCommentCount": 0,
"media": {
"images": [],
"video": ""
}
},
{
"reviewID": "R2BGDJLIQH5KFX",
"reviewerName": "A Person With An Opinion",
"reviewerLink": "https://www.amazon.com/gp/profile/amzn1.account.AFSMEKU6NSM3JBKWG5VQO44AW2VA/ref=cm_cr_arp_d_gw_btm?ie=UTF8",
"reviewLink": "https://www.amazon.com/gp/customer-reviews/R2BGDJLIQH5KFX/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=B09Z7KGTVW",
"reviewRating": "4.0 out of 5 stars",
"reviewDate": "Reviewed in the United States on February 20, 2023",
"reviewDetailsTop": [
{
"name": "Style",
"value": "Quest Pro System"
}
],
"reviewTitle": "Major upgrade that doesn't feel major",
"reviewText": "The first thing that I will say is that, even though it's a major upgrade from the quest 2 the pro doesn't shine as much as you would expect.",
"reviewVotes": "18 people found this helpful",
"reviewVerifiedPurchase": true,
"reviewCommentCount": 0,
"media": {
"images": [],
"video": ""
}
},
{
"reviewID": "RVRX0CNDU7TYK",
"reviewerName": "Artem",
"reviewerLink": "https://www.amazon.com/gp/profile/amzn1.account.AG4F7G5EVO6D3NRSRVIRRNUR4P5A/ref=cm_cr_arp_d_gw_btm?ie=UTF8",
"reviewLink": "https://www.amazon.com/gp/customer-reviews/RVRX0CNDU7TYK/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=B09Z7KGTVW",
"reviewRating": "4.0 out of 5 stars",
"reviewDate": "Reviewed in the United States on July 19, 2023",
"reviewDetailsTop": [
{
"name": "Style",
"value": "Quest Pro System"
}
],
"reviewTitle": "Overpriced but pretty good",
"reviewText": "UPDATE: It's alive. I don't know why and how but in a few days it has revived. 4 stars because I think it's overpriced anyway.",
"reviewVotes": "3 people found this helpful",
"reviewVerifiedPurchase": true,
"reviewCommentCount": 0,
"media": {
"images": [],
"video": ""
}
}
...
]
}
That's it! You've successfully executed the code to scrape Amazon reviews and save them to a file. You can now use this data for analysis or any other purposes as needed.
In our exploration of how to scrape Amazon reviews, we've uncovered a valuable tool for extracting insights from Amazon product reviews. Using the Crawlbase library and JavaScript, we've learned to gather and analyze customer feedback from Amazon effortlessly. These reviews offer a window into market trends, areas for product improvement, and insights into your competition. By understanding how to scrape Amazon reviews, we've also set up our coding environment, integrated Crawlbase, and developed code that efficiently navigates Amazon's review pages, saving us time, effort, and money. Storing this data systematically ensures we have a reliable record for future decision-making.
As we conclude, we encourage you to explore web scraping for data-driven decisions. Whether you're in business, research, or simply curious, web scraping can provide valuable insights. Always remember to scrape Amazon reviews responsibly, respecting websites' terms of service, and you'll unlock a world of data-driven possibilities. Embrace the potential of web scraping, and let data guide your way!
Frequently Asked Questions
Does Amazon allow web scraping?
Scraping reviews on Amazon is a gray area legally. While scraping publicly available data on a website is generally considered legal, there are important caveats. Amazon's terms of service explicitly prohibit web scraping. To stay within legal bounds, it's crucial to review and comply with Amazon's policies. Additionally, avoid excessive scraping that might disrupt Amazon's services or violate any applicable laws regarding data privacy.
Amazon also uses CAPTCHA challenges to verify that the user accessing the website is human. These challenges are designed to prevent automated bots and web scrapers from overwhelming the site. If you encounter CAPTCHA challenges while accessing Amazon, it's part of their security measures to ensure a fair and secure online shopping experience.
What's the benefit of using Crawlbase over other scraping methods?
Crawlbase Crawling API is a specialized tool designed for web scraping, making it more reliable and efficient for scraping Amazon reviews. It handles many of the challenges associated with web scraping, such as handling CAPTCHAs, IP rotation, and managing sessions. Plus, it offers dedicated support and ensures you can scrape Amazon reviews at scale while minimizing the risk of being blocked. While other methods are possible, Crawlbase can save time, effort, and resources.
What is the best way to scrape Amazon for product data?
The best way to scrape data from Amazon product pages is by using Crawlbase. It's like having a smart assistant that helps you get the information you need quickly and accurately from Amazon's website. Crawlbase makes web scraping easy, so you don't have to spend a lot of time and energy doing it manually. It's a great way to make sure you scrape Amazon reviews with ease or get the data you want without any hassles.
Can I scrape Amazon reviews for any product category?
Yes, you can scrape Amazon reviews for most product categories. However, Amazon's layout may vary slightly between categories. Your scraper should be adaptable to different product pages by recognizing and handling category-specific elements.
Can I use Crawlbase with different programming languages?
Yes, Crawlbase can work with various programming languages. It's made to be flexible. But here's the tip: to make things easier, we recommend using the Crawlbase library that matches your programming language. It's like having a special toolkit that fits your language perfectly. This toolkit has all the tools you need to connect your code to Crawlbase. So, if you can, use the Crawlbase library for a smoother experience. It'll save you time and make your web scraping project run more smoothly, no matter which programming language you prefer.


















