
This article was originally posted on Crawlbase Blog.
In the expansive world of e-commerce data retrieval, Scraping AliExpress with Python stands out as a vital guide for seasoned and novice data enthusiasts. This guide gently walks you through the step-by-step tutorial of scraping AliExpress using Crawlbase Crawling API.
Click here to jump right in the first step in case you want to skip the introduction.
Getting Started
Now that you're here, let's roll up our sleeves and get into the nitty-gritty of web scraping AliExpress using the Crawlbase Crawling API with Python. But first, let's break down the core elements you need to grasp before we dive into the technical details.
Brief overview of Web Scraping
In a world where information reigns supreme, web scraping is the art and science of extracting data from websites. It's a digital detective skill that allows you to access, collect, and organize data from the vast and ever-evolving landscape of the internet.
Think of web scraping as a bridge between you and a treasure trove of information online. Whether you're a business strategist, a data analyst, a market researcher, or just someone with a thirst for data-driven insights, web scraping is your key to unlocking the wealth of data that resides on the web. From product prices and reviews to market trends and competitor strategies, web scraping empowers you to access the invaluable data hidden within the labyrinth of web pages.
Importance of Scraping AliExpress

Scraping AliExpress with Python has become a pivotal strategy for data enthusiasts and e-commerce analysts worldwide. AliExpress, an online retail platform under the Alibaba Group, is not just a shopping hub but a treasure trove of data waiting to be explored. With millions of products, numerous sellers, and a global customer base, AliExpress provides a vast dataset for those seeking a competitive edge in e-commerce.
By scraping AliExpress with Python, you can effectively scour the platform for product information, pricing trends, seller behaviors, and customer reviews, thereby unlocking invaluable insights into the ever-changing landscape of online retail. Imagine the strategic benefits of having access to real-time data on product prices, trends, and customer reviews. Envision staying ahead of your competition by continuously monitoring market dynamics, tracking the latest product releases, and optimizing your pricing strategy based on solid, data-backed decisions.
When you utilize web scraping techniques, especially with powerful tools like the Crawlbase Crawling API, you enhance your data-gathering capabilities, making it a formidable weapon in your e-commerce data arsenal.
Introduction to the Crawlbase Crawling API
Our key ally in this web scraping endeavor is the Crawlbase Crawling API. This robust tool is your ticket to navigating the complex world of web scraping, especially when dealing with colossal platforms like AliExpress. One of its standout features is IP rotation, which is akin to changing your identity in the digital realm. Picture it as donning various disguises while navigating a crowded street; it ensures AliExpress sees you as a regular user, significantly lowering the risk of being flagged as a scraper. This guarantees a smooth and uninterrupted data extraction process.
This API's built-in scrapers tailored for AliExpress make it even more remarkable. Along with AliExpress scraper, Crawling API also provide built-in scrapers for other important websites. You can read about them here. These pre-designed tools simplify the process by efficiently extracting data from AliExpress's search and product pages. For an easy start, Crawlbase gives 1000 free crawling requests. Whether you're a novice in web scraping or a seasoned pro, the Crawlbase Crawling API, with its IP rotation and specialized scrapers, is your secret weapon for extracting data from AliExpress effectively and ethically.
In the upcoming sections, we'll equip you with all the knowledge and tools you need to scrape AliExpress effectively and ethically. You'll set up your environment, understand AliExpress's website structure, and become acquainted with Python, the programming language that will be your ally in this endeavor.
Setting Up Your Environment
Before we embark on our AliExpress web scraping journey, it's crucial to prepare the right environment. This section will guide you through the essential steps to set up your environment, ensuring you have all the tools needed to successfully scrape AliExpress using the Crawlbase Crawling API.
Installing Python and Essential Libraries
Python is the programming language of choice for our web scraping adventure. If you don't already have Python installed on your system, follow these steps:
- Download Python: Visit the Official Python Website and download the latest version of Python for your operating system.
- Installation: Run the downloaded Python installer and follow the installation instructions.
-
Verification: Open your command prompt or terminal and type python
--versionto verify that Python has been successfully installed. You should see the installed Python version displayed.
Now that you have Python up and running, it's time to install some essential libraries that will help us in our scraping journey. We recommend using pip, Python's package manager, for this purpose. Open your command prompt or terminal and enter the following commands:
pip install pandas
pip install crawlbase
Pandas: This is a powerful library for data manipulation and analysis, which will be essential for organizing and processing the data we scrape from AliExpress.
Crawlbase: This library will enable us to make requests to the Crawlbase APIs, simplifying the process of scraping data from AliExpress.
Creating a Virtual Environment (Optional)
Although not mandatory, it's considered good practice to create a virtual environment for your project. This step ensures that your project's dependencies are isolated, reducing the risk of conflicts with other Python projects.
To create a virtual environment, follow these steps:
- Install Virtualenv: If you don't have Virtualenv installed, you can install it using pip:
pip install virtualenv
- Create a Virtual Environment: Navigate to your project directory in the command prompt or terminal and run the following command to create a virtual environment named 'env' (you can replace 'env' with your preferred name):
virtualenv env
- Activate the Virtual Environment: Depending on your operating system, use one of the following commands to activate the virtual environment:
- For Windows:
.\env\Scripts\activate
- For macOS and Linux:
source env/bin/activate
You'll know the virtual environment is active when you see the environment name in your command prompt or terminal.
Obtaining a Crawlbase API Token
We will utilize the Crawlbase Crawling API to efficiently gather data from various websites. This API streamlines the entire process of sending HTTP requests to websites, seamlessly handles IP rotation, and effectively tackles common web challenges such as CAPTCHAs. Here's the step-by-step guide to obtaining your Crawlbase API token:
Head to the Crawlbase Website: Begin by opening your web browser and navigating to the official Crawlbase website.
Sign Up or Log In: Depending on your status, you'll either need to create a new Crawlbase account or log in to your existing one.
Retrieve Your API Token: Once you're logged in, locate the documentation section on the website to access your API token. Crawlbase provides two types of tokens: the Normal (TCP) token and the JavaScript (JS) token. The Normal token is suitable for websites with minimal changes, like static sites. However, if the website relies on JavaScript for functionality or if crucial data is generated via JavaScript on the user's side, the JavaScript token is essential. For example, when scraping data from dynamic websites like AliExpress, the Normal token is your go-to choice. You can get your API token here.
Safeguard Your API Token: Your API token is a valuable asset, so it's crucial to keep it secure. Avoid sharing it publicly, and refrain from committing it to version control systems like Git. This API token will be an integral part of your Python code, enabling you to access the Crawlbase Crawling API effectively.
With Pandas and the Crawlbase library installed, a Crawlbase API token in hand, and optionally within a virtual environment, you're now equipped with the essential tools to start scraping data from AliExpress using Python. In the following sections, we'll delve deeper into the process and guide you through each step.
Understanding AliExpress Website Structure
To become proficient in utilizing the Crawlbase Crawling API for AliExpress, it's essential to have a foundational understanding of the website's structure. AliExpress employs a specific layout for its search and product pages. In this section, we will delve into the layout of AliExpress search pages and product pages, setting the stage for utilizing the Crawlbase API's built-in scraping capabilities.
Layout of AliExpress Search Pages
AliExpress search pages serve as the gateway for discovering products based on your search criteria. These pages consist of several critical components:

- Search Bar: The search bar is where users input keywords, product names, or categories to initiate their search.
- Filter Options: AliExpress offers various filters to refine search results precisely. These filters include price ranges, shipping options, product ratings, and more.
- Product Listings: Displayed in a grid format, product listings present images, titles, prices, and seller details. Each listing is encapsulated within an HTML container, often denoted by specific classes or identifiers.
- Pagination: Due to the extensive product catalog, search results are distributed across multiple pages. Pagination controls, including "Next" and "Previous" buttons, enable users to navigate through result pages.
Understanding the structural composition of AliExpress search pages is crucial for effectively using the Crawlbase API to extract the desired data. In the forthcoming sections, we will explore how to interact programmatically with these page elements, utilizing Crawlbase's scraping capabilities.
Layout of AliExpress Product Pages
Upon clicking a product listing, users are directed to a dedicated product page. Here, detailed information about a specific product is presented. Key elements found on AliExpress product pages include:
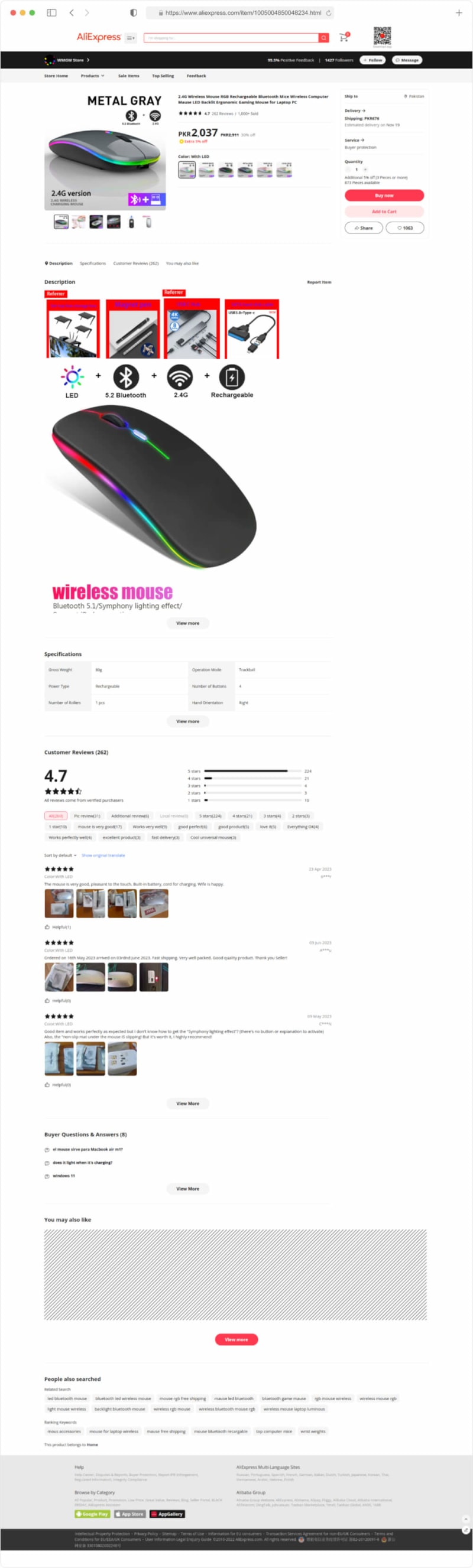
- Product Title and Description: These sections contain comprehensive textual data about the product, including its features, specifications, and recommended use. Extracting this information is integral for cataloging and analyzing products.
- Media Gallery: AliExpress often includes a multimedia gallery featuring images and, occasionally, videos. These visual aids provide potential buyers with a holistic view of the product.
- Price and Seller Information: This segment furnishes essential data regarding the product's price, shipping particulars, seller ratings, and contact details. This information aids users in making informed purchase decisions.
- Customer Reviews: Reviews and ratings provided by previous buyers offer valuable insights into the product's quality, functionality, and the reliability of the seller. Gathering and analyzing these reviews can be instrumental for assessing products.
- Purchase Options: AliExpress offers users the choice to add the product to their cart for later purchase or initiate an immediate transaction. Extracting this information allows for monitoring product availability and pricing changes.
With a solid grasp of AliExpress's website layout, we are well-prepared to leverage the Crawlbase Crawling API to streamline the data extraction process. The following sections will dive into the practical aspects of utilizing the API for AliExpress data scraping.
Utilizing the Crawlbase Python Library
Now that we've established a foundation for understanding AliExpress's website structure, let's delve into the practical application of the Crawlbase Python library to streamline the web scraping process. This section will guide you through the steps required to harness the power of the Crawlbase Crawling API effectively.
Importing and Initializing the CrawlingAPI Class
To begin, you'll need to import the Crawlbase Python library and initialize the CrawlingAPI class. This class acts as your gateway to making HTTP requests to AliExpress and retrieving structured data. Here's a basic example of how to get started:
from crawlbase import CrawlingAPI
# Initialize the Crawlbase API with your API token
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' })
Make sure to replace 'YOUR_CRAWLBASE_TOKEN' with your actual Crawlbase API token, which you obtained during the setup process.
Making HTTP Requests to AliExpress
With the CrawlingAPI class instantiated, you can now make HTTP requests to AliExpress. Crawlbase simplifies this process significantly. To scrape data from a specific AliExpress search page, you need to specify the URL of that page. For example:
# Define the URL of the AliExpress search page you want to scrape
aliexpress_search_url = 'https://www.aliexpress.com/wholesale?SearchText=your-search-query-here'
# Make an HTTP GET request to the specified URL
response = api.get(aliexpress_search_url)
Crawlbase will handle the HTTP request for you, and the response object will contain the HTML content of the page.
Managing Parameters and Customizing Responses
When using the Crawlbase Python library, you have the flexibility to customize your requests by including various parameters to tailor the API's behavior to your needs. You can read about them here. Some of them which we need are as below.
Scraper Parameter
The scraper parameter allows you to specify the type of data you want to extract from AliExpress. Crawlbase offers predefined scrapers for common AliExpress page types. You can choose from the following options:
-
aliexpress-product: Use this scraper for AliExpress product pages. It extracts detailed information about a specific product. Here's an example of how to use it:
response = api.get(aliexpress_search_url, {'scraper': 'aliexpress-product'})
-
aliexpress-serp: This scraper is designed for AliExpress search results pages. It returns an array of products from the search results. Here's how to use it:
response = api.get(aliexpress_search_url, {'scraper': 'aliexpress-serp'})
Please note that the scraper parameter is optional. If you don't use it, you will receive the full HTML of the page, giving you the freedom to perform custom scraping. With scraper parameter, The response will come back as JSON.
Format Parameter
The format parameter enables you to define the format of the response you receive from the Crawlbase API. You can choose between two formats: json or html. The default format is html. Here's how to specify the format:
response = api.get(aliexpress_search_url, {'format': 'json'})
- HTML Response: If you select the html response format (which is the default), you will receive the HTML content of the page as the response. The response parameters will be added to the response headers.
Headers:
url: https://www.aliexpress.com/wholesale?SearchText=laptop+accessories
original_status: 200
pc_status: 200
Body:
HTML of the page
- JSON Response: If you choose the json response format, you will receive a JSON object that you can easily parse. This JSON object contains all the information you need, including response parameters.
{
"original_status": "200",
"pc_status": 200,
"url": "https%3A%2F%2Faliexpress.com%2F/wholesale%3FSearchText%3Dlaptop+accessories",
"body": "HTML of the page"
}
These parameters provide you with the flexibility to retrieve data in the format that best suits your web scraping and data processing requirements. Depending on your use case, you can opt for either the JSON response for structured data or the HTML response for more customized scraping.
Scraping AliExpress Search and Product Pages
In this section, we will delve into the practical aspect of scraping AliExpress using the Crawlbase Crawling API. We'll cover three key aspects: scraping AliExpress search result pages, handling pagination on these result pages, and scraping AliExpress product pages. We will use search query water bottle and scrape the results related to this search query. Below are Python code examples for each of these tasks, along with explanations.
Scraping AliExpress Search Result Pages
To scrape AliExpress search result pages, we utilize the 'aliexpress-serp' scraper, a built-in scraper specifically designed for extracting product information from search results. The code initializes the Crawlbase Crawling API, sends an HTTP GET request to an AliExpress search URL, specifying the 'aliexpress-serp' scraper, and extracts product data from the JSON response.
from crawlbase import CrawlingAPI
import json
# Initialize the Crawlbase API with your API token
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' })
# Define the URL of the AliExpress search page you want to scrape
aliexpress_search_url = 'https://www.aliexpress.com/wholesale?SearchText=water+bottle'
# Make an HTTP GET request to the specified URL using the 'aliexpress-serp' scraper
response = api.get(aliexpress_search_url, {'scraper': 'aliexpress-serp'})
if response['status_code'] == 200:
# Loading JSON from response body after decoding byte data
response_json = json.loads(response['body'].decode('latin1'))
# Getting Scraper Results
scraper_result = response_json['body']
# Print scraped data
print(json.dumps(scraper_result, indent=2))
Example Output:
{
"products": [
{
"title": "Water-Bottle Plastic Travel Leak-Proof Girl Portable Anti-Fall Fruit Bpa-Free Creative",
"price": {
"current": "US $4.99"
},
"url": "https://www.aliexpress.com/item/4000576944298.html?algo_pvid=8d89f35c-7b12-4d10-a1c5-7fddeece5237&algo_expid=8d89f35c-7b12-4d10-a1c5-7fddeece5237-0&btsid=0ab6d70515838441863703561e47cf&ws_ab_test=searchweb0_0,searchweb201602_,searchweb201603_",
"image": "https://ae01.alicdn.com/kf/Hd0fdfd6d7e5f4a63b9383223500f704be/480ml-Creative-Fruit-Plastic-Water-Bottle-BPA-Free-Portable-Leak-Proof-Travel-Drinking-Bottle-for-Kids.jpg_220x220xz.jpg_.webp",
"shippingMessage": "Free Shipping",
"soldCount": 177,
"ratingValue": 5,
"ratingLink": "https://www.aliexpress.com/item/4000576944298.html?algo_pvid=8d89f35c-7b12-4d10-a1c5-7fddeece5237&algo_expid=8d89f35c-7b12-4d10-a1c5-7fddeece5237-0&btsid=0ab6d70515838441863703561e47cf&ws_ab_test=searchweb0_0,searchweb201602_,searchweb201603_#feedback",
"sellerInformation": {
"storeName": "Boxihome Store",
"storeLink": "https://www.aliexpress.com/store/5001468"
}
},
{
"title": "Lemon-Juice Drinking-Bottle Infuser Clear Fruit Plastic Large-Capacity Sports 800ml/600ml",
"price": {
"current": "US $3.17 - 4.49"
},
"url": "https://www.aliexpress.com/item/4000162032645.html?algo_pvid=8d89f35c-7b12-4d10-a1c5-7fddeece5237&algo_expid=8d89f35c-7b12-4d10-a1c5-7fddeece5237-1&btsid=0ab6d70515838441863703561e47cf&ws_ab_test=searchweb0_0,searchweb201602_,searchweb201603_",
"image": "https://ae01.alicdn.com/kf/H688cb15d9cd94fa58692294fa6780b59f/800ml-600ml-Large-Capacity-Sports-Fruit-Lemon-Juice-Drinking-Bottle-Infuser-Clear-Portable-Plastic-Water-Bottle.jpg_220x220xz.jpg_.webp",
"shippingMessage": "Free Shipping",
"soldCount": 1058,
"ratingValue": 4.6,
"ratingLink": "https://www.aliexpress.com/item/4000162032645.html?algo_pvid=8d89f35c-7b12-4d10-a1c5-7fddeece5237&algo_expid=8d89f35c-7b12-4d10-a1c5-7fddeece5237-1&btsid=0ab6d70515838441863703561e47cf&ws_ab_test=searchweb0_0,searchweb201602_,searchweb201603_#feedback",
"sellerInformation": {
"storeName": "Shop5112149 Store",
"storeLink": "https://www.aliexpress.com/store/5112149"
}
},
...
],
"relatedSearches": [
{
"title": "Water+Bottles",
"link": "https://www.aliexpress.com/w/wholesale-Water%252BBottles.html"
},
{
"title": "Water Bottles",
"link": "https://www.aliexpress.com/w/wholesale-Water-Bottles.html"
},
...
],
"relatedCategories": [
{
"title": "Home & Garden",
"link": "https://www.aliexpress.com/w/wholesale-water-bottle.html?CatId=15"
},
{
"title": "Water Bottles",
"link": "https://www.aliexpress.com/w/wholesale-water-bottle.html?CatId=100004985"
},
...
]
}
Handling Pagination on Search Result Pages
To navigate through multiple pages of search results, you can increment the page number in the search URL. This example demonstrates the basic concept of pagination, allowing you to scrape data from subsequent pages.
from crawlbase import CrawlingAPI
import json
# Initialize the Crawlbase API with your API token
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' })
# Define the base URL of the AliExpress search page you want to scrape
base_url = 'https://www.aliexpress.com/wholesale?SearchText=water+bottle&page={}'
# Initialize a list to store all scraped search results
all_scraped_products = []
# Define the number of pages you want to scrape
num_pages_to_scrape = 5
for page_num in range(1, num_pages_to_scrape + 1):
# Construct the URL for the current page
aliexpress_search_url = base_url.format(page_num)
# Make an HTTP GET request to the specified URL using the 'aliexpress-serp' scraper
response = api.get(aliexpress_search_url, {'scraper': 'aliexpress-serp'})
if response['status_code'] == 200:
# Loading JSON from response body after decoding byte data
response_json = json.loads(response['body'].decode('latin1'))
# Getting Scraper Results
scraper_result = response_json['body']
# Add the scraped products from the current page to the list
all_scraped_products.extend(scraper_result['products'])
In this code, we construct the search result page URLs for each page by incrementing the page number in the URL. We then loop through the specified number of pages, make requests to each page, extract the products from each search results using the 'aliexpress-serp' scraper, and add them to a list (all_scraped_products). This allows you to scrape and consolidate search results from multiple pages efficiently.
Scraping AliExpress Product Pages
When scraping AliExpress product pages, we use the 'aliexpress-product' scraper, designed for detailed product information extraction. The code initializes the Crawlbase API, sends an HTTP GET request to an AliExpress product page URL, specifying the 'aliexpress-product' scraper, and extracts product data from the JSON response.
from crawlbase import CrawlingAPI
import json
# Initialize the Crawlbase API with your API token
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' })
# Define the URL of an AliExpress product page you want to scrape
aliexpress_product_url = 'https://www.aliexpress.com/item/4000275547643.html'
# Make an HTTP GET request to the specified URL using the 'aliexpress-product' scraper
response = api.get(aliexpress_product_url, {'scraper': 'aliexpress-product'})
if response['status_code'] == 200:
# Loading JSON from response body after decoding byte data
response_json = json.loads(response['body'].decode('latin1'))
# Getting Scraper Results
scraper_result = response_json['body']
# Print scraped data
print(json.dumps(scraper_result, indent=2))
Example Output:
{
"title": "Luxury Transparent Matte Case For iphone 11 Pro XS MAX XR X Hybrid Shockproof Silicone Phone Case For iPhone 6 6s 7 8 Plus Cover",
"price": {
"current": "US $3.45",
"original": "US $4.31",
"discount": "-20%"
},
"options": [
{
"name": "Material",
"values": [
"for iphone 6 6S",
"for 6Plus 6SPlus",
...
]
},
{
"name": "Color",
"values": [
"Black",
"Blue",
...
}
],
"url": "https://www.aliexpress.com/item/4000275547643.html",
"mainImage": "https://ae01.alicdn.com/kf/H0913e18b6ff9415e86db047607c6fb9dB/Luxury-Transparent-Matte-Case-For-iphone-11-Pro-XS-MAX-XR-X-Hybrid-Shockproof-Silicone-Phone.jpg",
"images": [
"https://ae01.alicdn.com/kf/H0913e18b6ff9415e86db047607c6fb9dB/Luxury-Transparent-Matte-Case-For-iphone-11-Pro-XS-MAX-XR-X-Hybrid-Shockproof-Silicone-Phone.jpg",
"https://ae01.alicdn.com/kf/H1507016f0a504f35bbf2ec0d5763d14c4/Luxury-Transparent-Matte-Case-For-iphone-11-Pro-XS-MAX-XR-X-Hybrid-Shockproof-Silicone-Phone.jpg",
...
],
"customerReview": {
"average": 4.8,
"reviewsCount": 146
},
"soldCount": 1184,
"availableOffer": "Additional 3% off (2 pieces or more)",
"availableQuantity": 37693,
"wishlistCount": 983,
"sellerInformation": {
"storeName": "YiPai Digital Store",
"storeLink": "https://www.aliexpress.com/store/2056153",
"feedback": "92.9% Positive Feedback",
"followersCount": 462
},
"shippingSummary": {
"shippingPrice": "Shipping: US $0.41",
"destination": "to Austria via China Post Ordinary Small Packet Plus",
"estimatedDelivery": "Estimated Delivery: 25-46 days"
},
"buyerProtection": [
"60-Day Buyer Protection",
"Money back guarantee"
],
"recommendations": [
{
"link": "https://www.aliexpress.com/item/33053895974.html?gps-id=pcDetailBottomMoreThisSeller&scm=1007.13339.146401.0&scm_id=1007.13339.146401.0&scm-url=1007.13339.146401.0&pvid=ae985f4e-3eca-4c9e-a788-1f37bd5ff3e0",
"price": "US $1.55",
"image": "https://ae01.alicdn.com/kf/H604ad80f527c4b119e3bdb1be20b74cal.jpg_220x220q90.jpg_.webp"
},
...
],
"description": {
"detailedImages": [
"https://ae01.alicdn.com/kf/Hccaa2c9bf726484f94792998d93cc802Y.jpg",
"https://ae01.alicdn.com/kf/Hffe2339701634534a2fc4d5e183ff0aee.jpg",
...
],
"relatedProducts": [
{
"title": "Ultra Slim Silicone Case for iphone 7 6 6s 8 X Cover Coque Candy Colors Soft TPU Matte Phone Case for iphone7 8 plus XS MAX XR",
"price": "USD 1.29-1.50",
"link": "https://www.aliexpress.com/item/Ultra-Slim-Silicone-Case-for-iphone-7-6-6s-8-X-Cover-Coque-Candy-Colors-Soft/32772422277.html",
"image": "https://ae01.alicdn.com/kf/H5d0d6ac957ee4f57942ec172a7ed3529v.jpg_120x120.jpg"
},
...
]
},
"storeCategores": [
{
"parentNode": "For iPhone case",
"parentNodeLink": "https://www.aliexpress.com/store/group/For-iPhone-case/2056153_507217422.html",
"childrenNodes": [
{
"childNode": "For iPhone 5 5S SE",
"childNodeLink": "https://www.aliexpress.com/store/group/For-iPhone-5-5S-SE/2056153_507296208.html"
},
...
]
},
...
]
}
These code examples provide a step-by-step guide on how to utilize the Crawlbase Crawling API to scrape AliExpress search result pages and product pages. The built-in scrapers simplify the process, ensuring you receive structured data in JSON format, making it easier to handle and process the extracted information. This approach is valuable for various applications, such as price tracking, market analysis, and competitive research on the AliExpress platform.
Storing Data
After successfully scraping data from AliExpress pages, the next crucial step is storing this valuable information for future analysis and reference. In this section, we will explore two common methods for data storage: saving scraped data in a CSV file and storing it in an SQLite database. These methods allow you to organize and manage your scraped data efficiently.
Storing Scraped Data in a CSV File
CSV (Comma-Separated Values) is a widely used format for storing tabular data and is particularly useful when Scraping AliExpress with Python. It's a simple and human-readable way to store structured data, making it an excellent choice for saving your scraped AliExpress products data.
We'll extend our previous search page scraping script to include a step for saving some important information from scraped data into a CSV file using the popular Python library, pandas. Here's an updated version of the script:
import pandas as pd
from crawlbase import CrawlingAPI
import json
# Initialize the Crawlbase API with your API token
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' })
# Define the base URL of the AliExpress search page you want to scrape
base_url = 'https://www.aliexpress.com/wholesale?SearchText=water+bottle&page={}'
# Initialize a list to store all scraped products data
scraped_products_data = []
# Define the number of pages you want to scrape
num_pages_to_scrape = 5
for page_num in range(1, num_pages_to_scrape + 1):
# Construct the URL for the current page
aliexpress_search_url = base_url.format(page_num)
# Make an HTTP GET request to the specified URL using the 'aliexpress-serp' scraper
response = api.get(aliexpress_search_url, {'scraper': 'aliexpress-serp'})
if response['status_code'] == 200:
# Loading JSON from response body after decoding byte data
response_json = json.loads(response['body'].decode('latin1'))
# Getting Scraper Results
scraper_result = response_json['body']
# Add the scraped products data from the current page to the list
for product in scraper_result['products']:
data = {
"title": product['title'],
"price": product['price']['current'],
"rating": product['ratingValue']
}
scraped_products_data.push(data)
# Save scraped data as a CSV file
df = pd.DataFrame(scraped_products_data)
df.to_csv('aliexpress_products_data.csv', index=False)
In this updated script, we've introduced pandas, a powerful data manipulation and analysis library. After scraping and accumulating the product details in the scraped_products_data list, we create a pandas DataFrame from this data. Then, we use the to_csv method to save the DataFrame to a CSV file named "aliexpress_products_data.csv" in the current directory. Setting index=False ensures that we don't save the DataFrame's index as a separate column in the CSV file.
You can easily work with and analyze your scraped data by employing pandas. This CSV file can be opened in various spreadsheet software or imported into other data analysis tools for further exploration and visualization.
Storing Scraped Data in an SQLite Database
If you prefer a more structured and query-friendly approach to data storage, SQLite is a lightweight, serverless database engine that can be a great choice. You can create a database table to store your scraped data, allowing for efficient data retrieval and manipulation. Here's how you can modify the search page script to store data in an SQLite database:
import json
import sqlite3
from bs4 import BeautifulSoup
from crawlbase import CrawlingAPI
# Initialize the CrawlingAPI class with your Crawlbase API token
api = CrawlingAPI({'token': 'YOUR_CRAWLBASE_TOKEN'})
# Initialize a list to store all scraped products data
scraped_products_data = []
# Define the number of pages you want to scrape
num_pages_to_scrape = 5
def create_database():
conn = sqlite3.connect('aliexpress_products.db')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
price TEXT,
rating TEXT
)''')
conn.commit()
conn.close()
def save_to_database(data):
conn = sqlite3.connect('aliexpress_products.db')
cursor = conn.cursor()
# Create a list of tuples from the data
data_tuples = [(product['title'], product['price'], product['rating']) for product in data]
# Insert data into the products table
cursor.executemany('''
INSERT INTO products (title, price, rating)
VALUES (?, ?, ?)
''', data_tuples)
conn.commit()
conn.close()
for page_num in range(1, num_pages_to_scrape + 1):
# Construct the URL for the current page
aliexpress_search_url = base_url.format(page_num)
# Make an HTTP GET request to the specified URL using the 'aliexpress-serp' scraper
response = api.get(aliexpress_search_url, {'scraper': 'aliexpress-serp'})
if response['status_code'] == 200:
# Loading JSON from response body after decoding byte data
response_json = json.loads(response['body'].decode('latin1'))
# Getting Scraper Results
scraper_result = response_json['body']
# Add the scraped products data from the current page to the list
for product in scraper_result['products']:
data = {
"title": product['title'],
"price": product['price']['current'],
"rating": product['ratingValue']
}
scraped_products_data.push(data)
# Create the database and products table
create_database()
# Insert scraped data into the SQLite database
save_to_database(scraped_products_data)
In this updated code, we've added functions for creating the SQLite database and table ( create_database ) and saving the scraped data to the database ( save_to_database ). The create_database function checks if the database and table exist and creates them if they don't. The save_to_database function inserts the scraped data into the 'products' table.
By running this code, you'll store your scraped AliExpress product data in an SQLite database named 'aliexpress_products.db'. You can later retrieve and manipulate this data using SQL queries or access it programmatically in your Python projects.
Final Words
While we're on the topic of web scraping, if you're curious to dig even deeper and broaden your understanding by exploring data extraction from other e-commerce giants like Walmart, Amazon, I'd recommend checking out the Crawlbase blog page.
Our comprehensive guides don’t just end here; we offer a wealth of knowledge on scraping a variety of popular e-commerce platforms, ensuring you're well-equipped to tackle the challenges presented by each unique website architecture. Check out how to scrape Amazon search pages and Guide on Walmart Scraping.
Frequently Asked Questions
Q: What are the advantages of using the Crawlbase Crawling API for web scraping, and how does it differ from other scraping methods?
The Crawlbase Crawling API offers several advantages for web scraping compared to traditional methods. First, it provides IP rotation and user-agent rotation, making it less likely for websites like AliExpress to detect and block scraping activities. Second, it offers built-in scrapers tailored for specific websites, simplifying the data extraction process. Lastly, it provides the flexibility to receive data in both HTML and JSON formats, allowing users to choose the format that best suits their data processing needs. This API streamlines and enhances the web scraping experience, making it a preferred choice for scraping data from AliExpress and other websites.
Q: Can I use this guide to scrape data from any website, or is it specific to AliExpress?
While the guide primarily focuses on scraping AliExpress using the Crawlbase Crawling API, the fundamental concepts and techniques discussed here are applicable to web scraping in general. You can apply these principles to scrape data from other websites, but keep in mind that each website may have different structures, terms of service, and scraping challenges. Always ensure you have the necessary rights and permissions to scrape data from a specific website.
Q: How do I avoid getting blocked or flagged as a scraper while web scraping on AliExpress?
To minimize the risk of being blocked, use techniques like IP rotation and user-agent rotation, which are supported by the Crawlbase Crawling API. These techniques help you mimic human browsing behavior, making it less likely for AliExpress to identify you as a scraper. Additionally, avoid making too many requests in a short period and be respectful of the website's terms of service. Responsible scraping is less likely to result in blocks or disruptions.
Q: Can I scrape AliExpress product prices and use that data for pricing my own products?
While scraping product prices for market analysis is a common and legitimate use case, it's essential to ensure that you comply with AliExpress's terms of service and any legal regulations regarding data usage. Pricing your own products based on scraped data can be a competitive strategy, but you should verify the accuracy of the data and be prepared for it to change over time. Additionally, consider ethical and legal aspects when using scraped data for business decisions.


















