

This article was originally posted on Crawlbase Blog.
Welcome to Amazon Buy Box Data Scraping, your gateway to effective Amazon Buy Box Monitoring and data extraction! If you've ever shopped on Amazon, you've probably encountered the Buy Box without knowing it. This prominent section on a product page features the 'Add to Cart' or 'Buy Now' button and is crucial for buyers and sellers. Clicking that button means purchasing from the seller in the Buy Box.

Now, you might be wondering, "What's the big deal about a button?" Well, the Buy Box is more than just a button. Amazon uses a complex algorithm to determine which seller gets this privileged spot. This algorithm evaluates multiple factors, including price, shipping options, seller performance, and more.
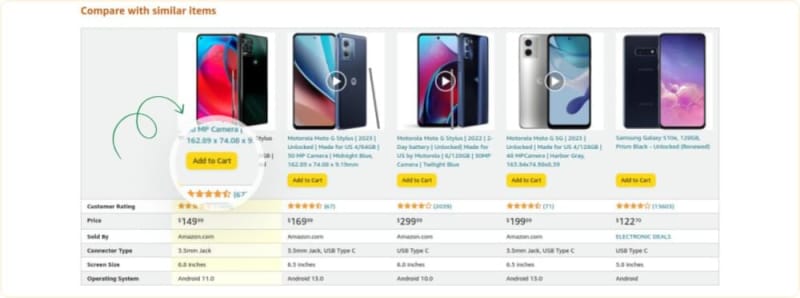
When a shopper taps on a product they're interested in, navigating beyond the Buy Box choice is scrolling significantly farther down to the "Compare with similar items" or "Other sellers on Amazon" section. This further enhances the desirability of securing the Buy Box. The seller who wins the Buy Box enjoys the lion's share of sales for that product. Studies have shown that the Buy Box receives about 90% of all sales on Amazon. That's a significant chunk of the pie.
For those experienced with Amazon, you may recall the existence of a utility known as "Featured Merchant". By 2018, Amazon had modernized Featured Merchant Status into the Buy Box. Fast forward to 2023, and Amazon now formally designates the Buy Box as a "Featured Offer."
As an Amazon seller, your dream is likely to see your products featured in that coveted Buy Box. Obviously, because its a direct route for shoppers to add the suggested product to the cart. You must have great pricing, best reviews, and seller performance to get on this list. Therefore, it's crucial for sellers to not only monitor the Buy Box but also track the factors that influence who wins it. With millions of products listed on Amazon, the competition is fierce. Hence, getting on Buy Box can make a huge difference to your sales.
To get on Buy Box, you need insights and strategies. Scroll down to learn how to track Buy Box price and other data elements through data scraping.
Table Of Contents
- The Need for Data Scraping
- Anti-Scraping Measures
- Handling IP Bans and Captchas
- Installing Python
- Installing Required Libraries
- Choosing the Right Development IDE
- Crawlbase Python Library
- Getting the Correct Crawlbase Token
- Making HTTP Requests to Amazon
- Handling Dynamic Content
- Inspecting HTML to Get CSS Selectors
- Structuring Your Data Scraper
- Storing Scraped Data in a CSV File
Why every Amazon Seller needs a spot on Buy Box?
Now that we've established the importance of the Buy Box let's delve into why it matters so much to sellers. Whether you're a small business owner or a large enterprise, securing the Buy Box is the ultimate goal when selling on Amazon.

- Visibility: Products featured in the Buy Box enjoy maximum visibility. They appear at the top of the product listing, making them the first choice for customers. This prime real estate increases the likelihood of your product being seen and sold.
- Increased Sales: Winning the Buy Box translates to a significant boost in sales. As mentioned, most Amazon shoppers click "Add to Cart" on the product in the Buy Box without comparing multiple options. This leads to more conversions and revenue for sellers.
- Customer Trust: Amazon's algorithm selects products for the Buy Box based on price, seller performance, and customer satisfaction. This means that products in the Buy Box are perceived as reliable and trustworthy. Sellers who consistently win the Buy Box tend to build trust with customers.
- Competitive Advantage: The Buy Box gives sellers a notable edge in the fiercely competitive Amazon marketplace. It's particularly advantageous for sellers introducing new products or targeting specific niches.
The Need for Data Scraping
Why do sellers need to consider data scraping an essential tool for Buy Box monitoring? The answer lies in the dynamic nature of the e-commerce landscape and the ever-evolving algorithms that determine the Buy Box winner. Let's explore the need for data scraping in this context.

- Real-Time Monitoring: The Buy Box is always changing. Amazon's algorithms decide in real-time who gets it based on many factors. Sellers must constantly watch who's in the Buy Box and why to stay competitive. Without data scraping, this would be a tough, time-consuming job. Data scraping makes it easier by giving real-time updates.
- Product Pricing: Pricing is one of Amazon's main factors for Buy Box allocation, so sellers need to know the pricing data of similar products to compare and adjust their pricing accordingly. With web scraping, sellers can automatically track pricing changes on their own products and competitors' listings.
- Competitor Analysis: Sellers can collect extensive data on their competitors, including their product listings, pricing, and seller performance metrics. This information is useful for tailoring strategies to outperform competitors and secure the Buy Box.
- Adaptation and Strategy Optimization: The Buy Box game isn't one-size-fits-all. What works for one product might not work for another. To succeed, sellers need the ability to adapt and optimize their strategies. Data scraping equips sellers with the insights they need to make informed decisions. It provides the data foundation for evaluating the effectiveness of different tactics, whether it's pricing adjustments, product bundling, or improving seller performance metrics.
- Efficiency and Scalability: Amazon's vast marketplace has countless product listings, sellers, and categories. Data crawling tools make it possible to efficiently monitor numerous products and sellers simultaneously. This scalability is essential for sellers looking to expand their presence on Amazon and compete in multiple product categories.
In short, web scraping allows Amazon sellers to gather real-time information about product pricing, competitor performance, and other variables that affect their Buy Box eligibility.
Challenges and Solutions in Buy Box Monitoring
When scraping data from websites, particularly e-commerce sites like Amazon, you will encounter a series of challenges. Amazon has stringent anti-scraping measures in place to protect its data. Additionally, you might run into issues like IP bans and captchas. However, these challenges can be effectively overcome with the right tools and strategies. One such tool that proves invaluable in this context is the Crawlbase Crawling API, a powerful solution for web scraping.
Anti-Scraping Measures
Like many other online platforms, Amazon employs various anti-scraping measures to deter automated data collection. Understanding how these measures work is crucial to successfully navigating the web scraping landscape. Here are some common anti-scraping measures employed by Amazon:
- CAPTCHAs: You've likely encountered these puzzles when browsing the web. CAPTCHAs are designed to test whether the user is a human or a bot. They come in various forms, such as image recognition challenges, distorted text, or selecting specific objects in images. Automated scrapers find it challenging to solve CAPTCHAs, as they require human-like visual recognition and interaction.
- Rate Limiting: Amazon can restrict the number of requests a single IP address can make within a specific time frame. Excessive and rapid requests trigger rate-limiting mechanisms, slowing down or completely blocking access to the site.
- IP Blocking: Amazon may temporarily or permanently block website access from IP addresses exhibiting scraping behavior. If your IP address gets blocked, you will be able to access the site once the block is lifted.
Handling IP Bans and Captchas
IP bans and captchas are common roadblocks faced by web scrapers. Amazon, like many other websites, can temporarily or permanently block your IP address if it detects scraping activities. Additionally, captchas may be deployed to differentiate between human and bot behavior. Captchas are designed to verify the user's identity and can often be quite challenging to bypass.
In these scenarios, the Crawlbase Crawling API proves to be a reliable ally. This API uses rotating IP addresses to circumvent IP bans. It enables you to make requests from a pool of rotating residential proxies, preventing your scraping activities from being easily identified and blocked. Moreover, the Crawlbase API can efficiently handle captchas, allowing you to automate captcha solving, saving you precious time and ensuring uninterrupted scraping. This API offers powerful solutions to two of the most significant challenges in web scraping, making it an essential tool to scrape product data from Amazon.
Setting Up Your Development Environment
This section will explore the prerequisites for successful data scraping, including configuring your development environment and selecting the right Development IDE.
Installing Python
Python is the primary programming language we'll use for web scraping. If you don't already have Python installed on your system, follow these steps:
Download Python: Visit the official Python website at python.org and download the latest version of Python. Choose the appropriate installer for your operating system (Windows, macOS, or Linux).
Installation: Run the downloaded installer and follow the installation instructions. Check the option that adds Python to your system's PATH during installation. This step is crucial for running Python from the command line.
Verify Installation: Open a command prompt or terminal and enter the following command to check if Python is installed correctly:
python --version
You should see the installed Python version displayed.
Installing Required Libraries
Python offers a rich ecosystem of libraries that simplify web scraping. For this project, you'll need the crawlbase library for making web requests with the Crawlbase API and the Beautiful Soup library for parsing HTML content. To install these libraries, use the following commands:
-
Crawlbase: The
crawlbaselibrary is a Python wrapper for the Crawlbase API, which will enable us to make web requests efficiently.
pip install crawlbase
- Beautiful Soup: Beautiful Soup is a library for parsing HTML and XML documents. It's especially useful for extracting data from web pages.
pip install beautifulsoup4
- Pandas: Pandas is a powerful data manipulation library that will help you organize and analyze the scraped data efficiently.
pip install pandas
With these libraries installed, you'll have the tools you need to fetch web pages using the Crawlbase API and parse their content during the scraping process.
Choosing the Right Development IDE
An Integrated Development Environment (IDE) provides a coding environment with features like code highlighting, auto-completion, and debugging tools. While you can write Python code in a simple text editor, an IDE can significantly improve your development experience.
Here are a few popular Python IDEs to consider:
PyCharm: PyCharm is a robust IDE with a free Community Edition. It offers features like code analysis, a visual debugger, and support for web development.
Visual Studio Code (VS Code): VS Code is a free, open-source code editor developed by Microsoft. Its vast extension library makes it versatile for various programming tasks, including web scraping.
Jupyter Notebook: Jupyter Notebook is excellent for interactive coding and data exploration. It's commonly used in data science projects.
Spyder: Spyder is an IDE designed for scientific and data-related tasks. It provides features like a variable explorer and an interactive console.
Choose the IDE that best suits your preferences and workflow. Once you have Python installed, the required libraries set up, and your chosen IDE ready, you're all set to scrape Buy Box data from Amazon product pages.
Accessing Amazon's Product Pages
Now that you have your development environment set up, it's time to delve into the technical aspects of accessing Amazon's product pages for Buy Box data scraping. In this section, we'll cover the usage of the Crawlbase Python Library, making HTTP requests to Amazon, and handling dynamic content.
Crawlbase Python Library
The Crawlbase Python library is a lightweight and dependency-free wrapper for Crawlbase APIs, streamlining the intricacies of web scraping. This versatile tool simplifies tasks like making HTTP requests to websites, adeptly handling IP rotation, and gracefully maneuvering through web obstacles, including CAPTCHAs. To embark on your web scraping journey with this library, you can seamlessly follow these steps:
- Import: To wield the formidable Crawling API from the Crawlbase library, you must commence by importing the indispensable CrawlingAPI class. This foundational step paves the way for accessing a range of Crawlbase APIs. Here's a glimpse of how you can import these APIs:
from crawlbase import CrawlingAPI
- Initialization: With your Crawlbase API token securely in hand, the next crucial step involves initializing the CrawlingAPI class. This pivotal moment connects your code to the vast capabilities of Crawlbase:
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' })
- Sending a Request: Once your CrawlingAPI class stands ready with your Crawlbase API token, you're poised to send requests to your target websites. Here's a practical example of crafting a GET request tailored for scraping iPhone listings from Walmart's search page:
response = api.get('https://www.facebook.com/britneyspears')
if response['status_code'] == 200:
print(response['body'])
With the Crawlbase Python library as your trusty companion, you can confidently embark on your web scraping odyssey. For a deeper dive into its capabilities, you can explore further details here.
Getting the Correct Crawlbase Token
We must obtain an API token before we can unleash the power of the Crawlbase Crawling API. Crawlbase provides two types of tokens: the Normal Token (TCP) for static websites and the JavaScript Token (JS) for dynamic or JavaScript-driven websites. Since Amazon relies heavily on JavaScript for dynamic content loading, we will opt for the JavaScript Token. To kick things off smoothly, Crawlbase generously offers an initial allowance of 1,000 free requests for the Crawling API.
from crawlbase import CrawlingAPI
# Initialize the Crawling API with your Crawlbase JavaScript token
api = CrawlingAPI({ 'token': 'YOU_CRAWLBASE_JS_TOKEN' })
You can get your Crawlbase token here after creating account on it.
Making HTTP Requests to Amazon
Armed with our JavaScript token, we're all set to set up the Crawlbase Crawling API. But before we proceed, let's delve into the structure of the output response. The response you receive can come in two formats: HTML or JSON. The default choice for the Crawling API is HTML format.
HTML response:
Headers:
url: "The URL which was crawled"
original_status: 200
pc_status: 200
Body:
The HTML of the page
We can read more about Crawling API response here. For the example, we will go with the default option. We'll utilize the initialized API object to make requests. Specify the URL you intend to scrape using the api.get(url, options={}) function.
from crawlbase import CrawlingAPI
# Initialize the Crawling API with your Crawlbase token
api = CrawlingAPI({ 'token': 'YOU_CRAWLBASE_JS_TOKEN' })
# URL of the Amazon search page you want to scrape
amazon_product_url = 'https://www.amazon.com/Motorola-Stylus-Battery-Unlocked-Emerald/dp/B0BFYRV4CD'
# Make a request to scrape the Amazon search page
response = api.get(amazon_product_url)
# Check if the request was successful
if response['status_code'] == 200:
# Extracted HTML content after decoding byte data
# latin1 will also handle chinese characters
html_content = response['body'].decode('latin1')
# Save the HTML content to a file
with open('output.html', 'w', encoding='utf-8') as file:
file.write(html_content)
else:
print("Failed to retrieve the page. Status code:", response['status_code'])
In the provided code snippet, we safeguard the acquired HTML content by storing it in an HTML file. This action is crucial to confirm the successful acquisition of the targeted HTML data. We can then review the file to inspect the specific content within the crawled HTML.
output.html Preview:

As you can see above, no useful information is present in the crawled HTML. This is because Amazon loads its important content dynamically using JavaScript and Ajax.
Handling Dynamic Content
Amazon's product pages often feature dynamic content loaded through JavaScript and Ajax calls. This dynamism can pose a challenge when scraping data. However, with the Crawlbase Crawling API, these challenges can be effectively managed.
from crawlbase import CrawlingAPI
# Initialize the Crawling API with your Crawlbase token
api = CrawlingAPI({ 'token': 'YOU_CRAWLBASE_JS_TOKEN' })
# URL of the Amazon search page you want to scrape
amazon_product_url = 'https://www.amazon.com/Motorola-Stylus-Battery-Unlocked-Emerald/dp/B0BFYRV4CD'
# options for Crawling API
options = {
'page_wait': 2000,
'ajax_wait': 'true'
}
# Make a request to scrape the Amazon search page with options
response = api.get(amazon_product_url, options)
# Check if the request was successful
if response['status_code'] == 200:
# Extracted HTML content after decoding byte data
html_content = response['body'].decode('latin1')
# Save the HTML content to a file
with open('output.html', 'w', encoding='utf-8') as file:
file.write(html_content)
else:
print("Failed to retrieve the page. Status code:", response['status_code'])
Crawlbase allows you to define specific parameters that ensure the accurate capture of dynamically rendered content. Two key parameters to consider include:
- page_wait: This optional parameter lets you specify the millisecond duration to await before capturing the resultant HTML code. Use this parameter when a page requires additional time for rendering or when AJAX requests must be fully loaded before capturing HTML.
- ajax_wait: Another optional parameter tailored for the JavaScript token enables you to indicate whether the script should await the completion of AJAX requests before receiving the HTML response. This is invaluable when content relies on the execution of AJAX requests.
By leveraging these parameters, you can effectively navigate and extract data from Amazon's product pages, even when confronted with dynamic content.
output.html Preview:

With the knowledge of Crawlbase and how to make HTTP requests to Amazon, you're now prepared to build your buy box tracker. In the next section, we'll explore the intricacies of scraping Buy Box data and extracting the necessary information.
Scraping Buy Box Data
Scraping data from the Buy Box on Amazon's product pages is a pivotal step in monitoring and tracking this coveted position. However, to do this effectively, you need to understand the structure of Amazon's web pages and know what specific data within the Buy Box is crucial for your tracking purposes.
Inspecting HTML to Get CSS Selectors
To scrape data from the Buy Box, you first need to identify the HTML elements that contain the information you're interested in. This process involves inspecting the HTML structure of Amazon's product pages to locate the CSS selectors corresponding to the data you want to extract.
So, what data is important within the Buy Box?
- Product Title: The name of the product featured in the Buy Box is essential for tracking changes in the listings.
- Price: Monitoring the product's current price in the Buy Box is critical as it often fluctuates due to various factors.
- Seller Information: Information about the seller, including their name and whether they are Amazon or a third-party seller, is vital to understand who currently occupies the Buy Box.
- Availability: Checking the product's availability helps sellers assess the competition for the Buy Box.
- Add to Cart Button: Monitoring changes in the "Add to Cart" button is essential, indicating whether customers can purchase the product directly from the Buy Box.
Let's outline how you can inspect the HTML structure and unearth CSS selectors for this information:

- Open the Web Page: Navigate to the Amazon website and land on either a product page that beckons your interest.
- Right-Click and Inspect: Employ your right-clicking prowess on an element you wish to extract (e.g., a Buy Box) and select "Inspect" or "Inspect Element" from the context menu. This mystical incantation will conjure the browser's developer tools.
- Locate the HTML Source: Within the confines of the developer tools, the HTML source code of the web page will lay bare its secrets. Hover your cursor over various elements in the HTML panel and witness the corresponding portions of the web page magically illuminate.
- Identify CSS Selectors: To liberate data from a particular element, right-click on it within the developer tools and gracefully choose "Copy" > "Copy selector." This elegant maneuver will transport the CSS selector for that element to your clipboard, ready to be wielded in your web scraping incantations.
Once you have these selectors, you can proceed to structure your data scraper to extract the required information effectively.
Structuring Your Data Scraper
Now that we have successfully acquired the HTML content of Amazon's dynamic product page and know how to get CSS selector, it's time to extract the valuable data for Amazon Buy Box from the retrieved content. In this developer-focused section, we'll construct a Python script that adeptly captures product data from Walmart's search results page.
This script encapsulates the essence of web scraping: making HTTP requests, parsing HTML content, and extracting the critical information we seek.
from crawlbase import CrawlingAPI
from bs4 import BeautifulSoup
import json
def initialize_crawlbase_api(token):
return CrawlingAPI({'token': token})
def scrape_amazon_product_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
product_info = {}
def get_text_or_default(selector, default="Not found"):
element = soup.select_one(selector)
return element.text.strip() if element else default
def is_element_present(selector):
element = soup.select_one(selector)
return "Present" if element else "Not Present"
product_info['Buy Now Button'] = is_element_present('span#submit\\.buy-now')
product_info['Add to Cart Button'] = is_element_present('span#submit\\.add-to-cart')
product_info['Availability'] = get_text_or_default('#availability span')
product_info['Product Title'] = get_text_or_default('#productTitle')
product_info['Price'] = get_text_or_default('.a-price .a-offscreen')
product_info['Shipper Name'] = get_text_or_default('#fulfillerInfoFeature_feature_div span.offer-display-feature-text-message')
product_info['Seller Name'] = get_text_or_default('#merchantInfoFeature_feature_div span.offer-display-feature-text-message')
return product_info
def scrape_amazon_product_info(api, url):
options = {
'page_wait': 2000,
'ajax_wait': 'true'
}
response = api.get(url, options)
if response['status_code'] == 200:
html_content = response['body'].decode('latin1')
return scrape_amazon_product_html(html_content)
else:
print("Failed to retrieve the page. Status code:", response['status_code'])
return None
def main():
api = initialize_crawlbase_api('YOU_CRAWLBASE_JS_TOKEN')
product_info = scrape_amazon_product_info(api, 'https://www.amazon.com/Motorola-Stylus-Battery-Unlocked-Emerald/dp/B0BFYRV4CD')
if product_info:
print(json.dumps(product_info, indent=2))
if __name__ == "__main__":
main()
This Python script scrape Amazon product data using the Crawlbase Crawling API and the BeautifulSoup library. It starts by initializing the Crawling API with a user-specific token. The core functionality is encapsulated within the scrape_amazon_product_info function, which scrapes data from a specified Amazon product URL. This function makes an HTTP request to the given URL and checks if the response status code is 200, indicating a successful request. If successful, it parses the HTML content using BeautifulSoup.
Inside the scrape_amazon_product_html function, it utilizes various CSS selectors to extract specific information from the HTML, such as the Buy Now Button's presence, Add to Cart Button's presence, product availability, product title, price, shipper name, and seller name. It handles cases where the element is not found and assigns a default value of "Not found."
Finally, the script invokes the main function, which initializes the Crawling API, scrapes product data from a sample Amazon product URL, and prints the scraped data as a nicely formatted JSON object. This code provides a clear and structured way to retrieve essential information from Amazon product pages, making it a valuable tool for tracking and monitoring product data.
Example output:
{
"Buy Now Button": "Present",
"Add to Cart Button": "Present",
"Availability": "In Stock",
"Product Title": "Motorola Moto G Stylus 5G | 2021 | 2-Day Battery | Unlocked | Made for US 4/128GB | 48MP Camera | Cosmic Emerald",
"Price": "$149.99",
"Shipper Name": "Amazon.com",
"Seller Name": "Amazon.com"
}
Storing Scraped Data in a CSV File
After successfully scraping the Buy Box data from Amazon's product pages, the next logical step is to store this valuable information efficiently. CSV (Comma-Separated Values) is a widely used format for storing tabular data and is particularly useful when Scraping AliExpress with Python. It provides a simple and human-readable way to store structured data, making it an excellent choice for saving your scraped Amazon Buy Box data.
We'll extend our previous search page scraping script to include a step for saving important information from the scraped data into a CSV file. To accomplish this, we will employ the popular Python library pandas. Below is an updated version of the script:
from crawlbase import CrawlingAPI
from bs4 import BeautifulSoup
import pandas as pd
def initialize_crawlbase_api(token):
return CrawlingAPI({'token': token})
def scrape_amazon_product_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
product_info = {}
def get_text_or_default(selector, default="Not found"):
element = soup.select_one(selector)
return element.text.strip() if element else default
def is_element_present(selector):
element = soup.select_one(selector)
return "Present" if element else "Not Present"
product_info['Buy Now Button'] = is_element_present('span#submit\\.buy-now')
product_info['Add to Cart Button'] = is_element_present('span#submit\\.add-to-cart')
product_info['Availability'] = get_text_or_default('#availability span')
product_info['Product Title'] = get_text_or_default('#productTitle')
product_info['Price'] = get_text_or_default('.a-price .a-offscreen')
product_info['Shipper Name'] = get_text_or_default('#fulfillerInfoFeature_feature_div span.offer-display-feature-text-message')
product_info['Seller Name'] = get_text_or_default('#merchantInfoFeature_feature_div span.offer-display-feature-text-message')
return product_info
def scrape_amazon_product_info(api, url):
options = {
'page_wait': 2000,
'ajax_wait': 'true'
}
response = api.get(url, options)
if response['status_code'] == 200:
html_content = response['body'].decode('latin1')
return scrape_amazon_product_html(html_content)
else:
print("Failed to retrieve the page. Status code:", response['status_code'])
return None
def main():
api = initialize_crawlbase_api('YOU_CRAWLBASE_JS_TOKEN')
product_info = scrape_amazon_product_info(api, 'https://www.amazon.com/Motorola-Stylus-Battery-Unlocked-Emerald/dp/B0BFYRV4CD')
if product_info:
# Create a DataFrame from the product_info dictionary
df = pd.DataFrame([product_info])
# Save the DataFrame to a CSV file
df.to_csv('amazon_product_info.csv', index=False)
if __name__ == "__main__":
main()
The updated code saves data into a CSV file by utilizing the Pandas library. First, it creates a Pandas DataFrame from the product_info dictionary, where each key-value pair in the dictionary corresponds to a column in the DataFrame. Then, it saves the DataFrame as a CSV file. The pd.DataFrame([product_info]) statement constructs the DataFrame with a single row of data, ensuring that the data is organized in a tabular structure. Finally, df.to_csv('amazon_product_info.csv', index=False) exports the DataFrame to a CSV file named amazon_product_info.csv while omitting the default indexing that Pandas adds to the CSV, resulting in a clean and structured storage of the scraped Amazon product information.
amazon_product_info.csv Preview:

Final Words
I hope you can now easily scrape Amazon Buy Box Data. For more tutorials on Amazon Scraping, check out the links below:
📜 How to Scrape Amazon Reviews
📜 How to Scrape Amazon Search Pages
📜 How to Scrape Amazon Product Data
For more Amazon scraping tutorials, check out our guides on scraping Amazon prices, Amazon ppc ads, Amazon ASIN, Amazon reviews, Amazon Images, and Amazon data in Ruby.
We have a vast library on tutorials like these for other ecommerce sites too like scraping Walmart, eBay, and AliExpress Product data.
If you have any questions or need assistance, don't hesitate to reach out to us here. We're here to help!
Frequently Asked Questions
Q. What is the Amazon Buy Box, and why is it important?
Amazon Buy Box is a crucial feature on product pages where customers can instantly purchase. It's vital because it significantly influences sales. When you click "Add to Cart" or "Buy Now," you buy from the seller in the Buy Box. Winning the Buy Box is like claiming the pole position in an e-commerce race. It's essential for both buyers and sellers because the majority of sales on Amazon happen through this box. The seller who occupies the Buy Box enjoys high visibility, more sales, and customer trust.
Q. Why do sellers need data scraping for Buy Box monitoring?
Sellers need data scraping to keep up with the dynamic and competitive nature of the Buy Box. The Buy Box constantly changes based on price, availability, and seller performance. To succeed, sellers must adapt their strategies in real-time. Data scraping provides real-time monitoring and data on various aspects, including prices and competitor performance. It helps sellers optimize their strategies and secure the Buy Box spot.
Q. How does data scraping handle challenges like anti-scraping measures?
Websites like Amazon have defenses to stop scraping, such as tracking unusual behavior or blocking IP addresses. Data scraping tools, like the Crawlbase Crawling API, are designed to bypass these measures. They can rotate IP addresses, making it harder for Amazon to block them. Additionally, they can solve captchas automatically, so scraping can continue without interruption.
Q. What do I need to start scraping Buy Box data on Amazon?
To begin scraping Buy Box data, you'll need a few things. First, you should have Python installed on your computer. You'll also need specific libraries for web scraping, such as Crawlbase, Beautiful Soup, and Pandas. These libraries help you make requests, parse web pages, and organize data efficiently. Additionally, you'll require a Crawlbase token, which gives you access to Amazon's website through the Crawlbase Crawling API. You can begin your Buy Box data scraping journey with these tools and your token.


















