
This blog was originally posted to Crawlbase Blog
DeviantArt stands out as the biggest social platform for digital artists and art fans. With over 60 million members sharing tens of thousands of artworks daily, it's a top spot for exploring and downloading diverse creations, from digital paintings to wallpapers, pixel art, anime, and film snapshots.
However, manually collecting thousands of data points from websites can be very time-consuming. Instead of manually copying information, we automate the process using programming languages like Python.

Scraping DeviantArt gives us a chance to look at different art styles, see what's trending, and build our collection of favorite pictures. It's not just about enjoying art; we can also learn more about it.
In this guide, we'll use Python, a friendly programming language. And to help us with scraping, we've got the Crawlbase Crawling API – a handy tool that makes getting data from the web a lot simpler. Together, Python and the Crawlbase API make exploring and collecting digital art a breeze.
Table Of Contents
- DeviantArt Search Page Structure
- Why Scrape Images from DeviantArt?
- Installing Python and Libraries
- Obtaining Crawlbase API Key
- Configuring Your Development Environment
- Technical Benefits of Crawlbase Crawling API
- Sending Request With Crawling API
- API Response Time and Format
- Crawling API Parameters
- Free Trial, Charging Strategy, and Rate Limit
- Crawlbase Python library
- Importing Necessary Libraries
- Constructing the URL for DeviantArt Search
- Making API Requests with Crawlbase Crawling API to Retrieve HTML
- Running Your Script
- Understanding Pagination in DeviantArt
- Modifying API Requests for Multiple Pages
- Ensuring Efficient Pagination Handling
- Inspecting DeviantArt Search Page for CSS Selectors
- Utilizing CSS Selectors for Extracting Image URLs
- Storing Extracted Data in CSV and SQLite Database
- Using Python to Download Images
- Organizing Downloaded Images
Understanding DeviantArt Website
DeviantArt stands as a vibrant and expansive online community that serves as a haven for artists, both seasoned and emerging. Launched in 2000, DeviantArt has grown into one of the largest online art communities, boasting millions of users and an extensive collection of diverse artworks.
At its core, DeviantArt is a digital gallery where artists can exhibit a wide range of creations, including digital paintings, illustrations, photography, literature, and more. The platform encourages interaction through comments, critiques, and the creation of collaborative projects, fostering a dynamic and supportive environment for creative minds.
DeviantArt Search Page Structure
The search page is a gateway to a multitude of artworks, providing filters and parameters to refine the search for specific themes, styles, or artists.

Key components of the DeviantArt Search Page structure include:
- Search Bar: The entry point for users to input keywords, tags, or artists' names.
- Filters: Options to narrow down searches based on categories, types, and popularity.
- Results Grid: Displaying a grid of thumbnail images representing artworks matching the search criteria.
- Pagination: Navigation to move through multiple pages of search results.
Why Scrape Images from DeviantArt?
People, including researchers, scrape images for various reasons. Firstly, it allows enthusiasts to discover diverse artistic styles and talents on DeviantArt, making it an exciting journey of artistic exploration. For researchers and analysts, scraping provides valuable data to study trends and the evolution of digital art over time. Artists and art enthusiasts also use scraped images as a source of inspiration and create curated collections, showcasing the immense creativity within the DeviantArt community. Additionally, scraping helps in understanding the dynamics of the community, including popular themes, collaboration trends, and the impact of different art styles. In essence, scraping from DeviantArt is a way to appreciate, learn from, and contribute to the rich tapestry of artistic expression on the platform.
Setting Up Your Environment
For Image scraping from Deviantart, let's ensure your environment is primed and ready. This section will guide you through the installation of essential tools, including Python, and the setup of the necessary libraries — Crawlbase, BeautifulSoup, and Pandas.
Installing Python and Libraries
Python Installation:
Begin by installing Python, the programming language that will drive our scraping adventure. Visit the official Python website and download the latest version suitable for your operating system. Follow the installation instructions to set up Python on your machine.
Library Installation:
Once Python is installed, open your terminal or command prompt and install the required libraries using the following commands:
pip install crawlbase
pip install beautifulsoup4
pip install pandas
pip install requests
Crawlbase: The crawlbase library is a Python wrapper for the Crawlbase API, which will enable us to make web requests efficiently.
Beautiful Soup: Beautiful Soup is a library for parsing HTML and XML documents. It's especially useful for extracting data from web pages.
Pandas: Pandas is a powerful data manipulation library that will help you organize and analyze the scraped data efficiently.
Requests: The requests library is a Python module for effortlessly sending HTTP requests and managing responses. It simplifies common HTTP operations, making it a widely used tool for web-related tasks like web scraping and API interactions.
Obtaining Crawlbase API Key
Sign Up for Crawlbase:
Navigate to the Crawlbase website and sign up for an account if you haven't already. Once registered, log in to your account.
Retrieve Your API Key:
After logging in, go to your account settings or dashboard on Crawlbase. Locate your API key, which is crucial for interacting with the Crawlbase Crawling API. Keep this key secure, as it will be your gateway to accessing the web data you seek.
Configuring Your Development Environment
Text Editor or IDE:
Choose a text editor or integrated development environment (IDE) for coding. Popular choices include VSCode, PyCharm, or Jupyter Notebooks. Use the one you're most comfortable with or explore new options that suit your preferences.
Create a Virtual Environment:
To maintain a clean and organized development environment, consider creating a virtual environment for your project. Use the following commands in your terminal:
# Create a virtual environment
python -m venv myenv
# Activate the virtual environment
source myenv/bin/activate # On macOS/Linux
.\myenv\Scripts\activate # On Windows
With these steps, your environment is now equipped with the necessary tools for our DeviantArt scraping endeavor. In the upcoming sections, we'll leverage these tools to craft our DeviantArt Scraper and unravel the world of digital artistry.
Exploring Crawlbase Crawling API
Embarking on your journey to use web scraping for DeviantArt, it's crucial to understand the Crawlbase Crawling API. This part will break down the technical details of Crawlbase's API, giving you the know-how to smoothly use it in your Python job-scraping project.
Technical Benefits of Crawlbase Crawling API
The Crawlbase Crawling API offers several important advantages, helping developers collect web data and manage different parts of the crawling process easily. Here are some notable benefits:
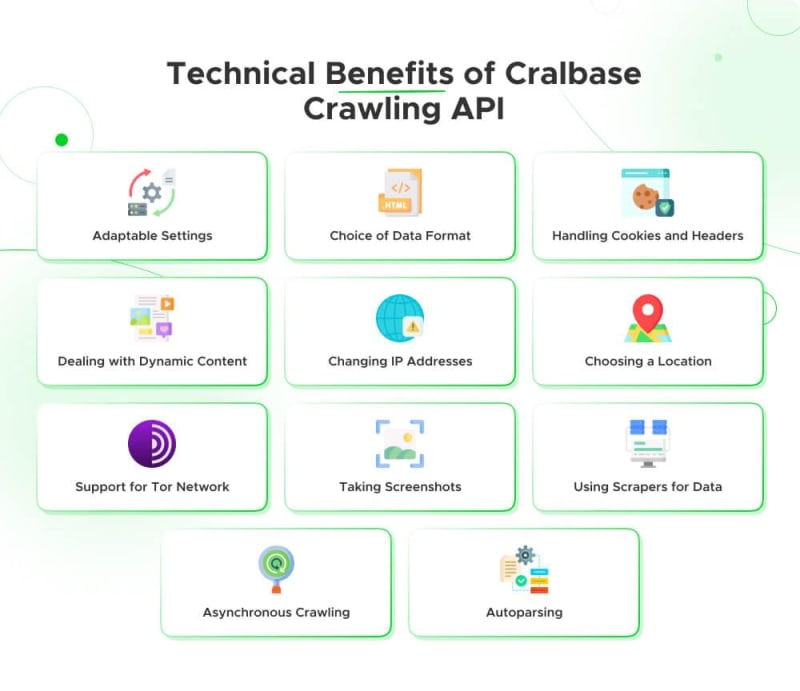
- Adaptable Settings: Crawlbase Crawling API gives a lot of settings, letting developers fine-tune their API requests. This includes parameters like "format", "user_agent", "page_wait", and more, allowing customization based on specific needs.
- Choice of Data Format: Developers can pick between JSON and HTML response formats based on what they prefer and what suits their data processing needs. This flexibility makes data extraction and handling easier.
- Handling Cookies and Headers: By using parameters like "get_cookies" and "get_headers," developers can get important information like cookies and headers from the original website, crucial for certain web scraping tasks.
- Dealing with Dynamic Content: This API is good at handling dynamic content, useful for crawling pages with JavaScript. Parameters like "page_wait" and "ajax_wait" help developers make sure the API captures all the content, even if it takes time to load.
- Changing IP Addresses: This API lets you switch IP addresses, keeping you anonymous and reducing the chance of being blocked by websites. This feature makes web crawling more successful.
- Choosing a Location: Developers can specify a country for requests using the "country" parameter, which is handy for situations where you need data from specific places.
- Support for Tor Network: Turning on the "tor_network" parameter allows crawling onion websites over the Tor network, making it more private and giving access to content on the dark web.
- Taking Screenshots: With the screenshot API or "screenshot" paramter you can capture screenshots of web pages, giving a visual context to the data collected.
- Using Scrapers for Data: This API lets you use pre-defined data scrapers using "scraper" parameter, making it easier to get specific information from web pages without much hassle.
- Asynchronous Crawling: When you need to crawl asynchronously, the API supports the "async" parameter. Developers get a request identifier (RID) to easily retrieve crawled data from cloud storage.
- Autoparsing: The "autoparse" parameter makes data extraction simpler by providing parsed information in JSON format, reducing the need for a lot of extra work after getting the HTML content.
In summary, Crawlbase's Crawling API is a strong tool for web scraping and data extraction. It offers a variety of settings and features to fit different needs, making web crawling efficient and effective, whether you're dealing with dynamic content, managing cookies and headers, changing IP addresses, or getting specific data.
Sending Request With Crawling API
Crawlbase's Crawling API is designed for simplicity and ease of integration into your web scraping projects. All API URLs begin with the base part: https://api.crawlbase.com. Making your first API call is as straightforward as executing a command in your terminal:
curl 'https://api.crawlbase.com/?token=YOUR_CRAWLBASE_TOKEN&url=https%3A%2F%2Fgithub.com%2Fcrawlbase-source%3Ftab%3Drepositories'
Here, you'll notice the token parameter, which serves as your authentication key for accessing Crawlbase's web scraping capabilities. Crawlbase offers two token types: a normal (TCP) token and JavaScript (JS) token. Choose the normal token for websites that don't change much, like static websites. But if you want to get information from a site that only works when people use web browsers with JavaScript or if JavaScript makes the important stuff you want on the user's side, then you should use the JavaScript token. Like with DeviantArt, normal token is a good choice.
API Response Time and Format
When engaging with the Crawlbase Crawling API, it's vital to grasp the dynamics of response times and how to interpret success or failure. Let's take a closer look at these components:
Response Timings: Ordinarily, the API exhibits response times within a spectrum of 4 to 10 seconds. To ensure a smooth encounter and accommodate potential delays, it's recommended to set a timeout for calls to a minimum of 90 seconds. This safeguards your application, allowing it to manage fluctuations in response times without disruptions.
Response Formats: When making requests to Crawlbase, you enjoy the flexibility to opt for either HTML or JSON response formats, depending on your preferences and parsing needs. By appending the "format" query parameter with the values "HTML" or "JSON," you can specify your desired format.
In the scenario where you choose the HTML response format (the default setting), the API will furnish the HTML content of the webpage as the response. The response parameters will be conveniently incorporated into the response headers for easy accessibility. Here's an illustrative response example:
Headers:
url: https://github.com/crawlbase-source?tab=repositories
original_status: 200
pc_status: 200
Body:
HTML of the page
If you opt for the JSON response format, you'll receive a structured JSON object that can be easily parsed in your application. This object contains all the information you need, including response parameters. Here's an example response:
{
"original_status": "200",
"pc_status": 200,
"url": "https%3A%2F%2Fgithub.com%2Fcrawlbase-source%3Ftab%3Drepositories",
"body": "HTML of the page"
}
Response Headers: Both HTML and JSON responses include essential headers that provide valuable information about the request and its outcome:
-
url: The original URL that was sent in the request or the URL of any redirects that Crawlbase followed. -
original_status: The status response received by Crawlbase when crawling the URL sent in the request. It can be any valid HTTP status code. -
pc_status: The Crawlbase (pc) status code, which can be any status code and is the code that ends up being valid. For instance, if a website returns an original_status of 200 with a CAPTCHA challenge, the pc_status may be 503. -
body: This parameter is available in JSON format and contains the content of the web page that Crawlbase found as a result of proxy crawling the URL sent in the request.
These response parameters empower you to assess the outcome of your requests and determine whether your web scraping operation was successful.
Crawling API Parameters
Crawlbase offers a comprehensive set of parameters that allow developers to customize their web crawling requests. These parameters enable fine-tuning of the crawling process to meet specific requirements. For instance, you can specify response formats like JSON or HTML using the "format" parameter or control page waiting times with "page_wait" when working with JavaScript-generated content.
Additionally, you can extract cookies and headers, set custom user agents, capture screenshots, and even choose geolocation preferences using parameters such as "get_cookies," "user_agent," "screenshot," and "country." These options provide flexibility and control over the web crawling process. For example, to retrieve cookies set by the original website, you can simply include get_cookies=true query param in your API request, and Crawlbase will return the cookies in the response headers.
You can read more about Crawlbase Crawling API parameters here.
Free Trial, Charging Strategy, and Rate Limit
Crawlbase extends a trial period encompassing the first 1,000 requests, offering a chance to delve into its capabilities before making a commitment. Yet, optimizing this trial window is crucial to extracting the utmost value from it.
Operating on a "pay-as-you-go" model, Crawlbase charges exclusively for successful requests, ensuring a cost-effective and efficient solution for your web scraping endeavors. The determination of successful requests is contingent upon scrutinizing the original_status and pc_status within the response parameters.
The API imposes a rate limit, capping requests at a maximum of 20 per second, per token. Should you necessitate a more elevated rate limit, reaching out to support allows for a tailored discussion to accommodate your specific requirements.
Crawlbase Python library
The Crawlbase Python library offers a simple way to interact with the Crawlbase Crawling API. You can use this lightweight and dependency-free Python class as a wrapper for the Crawlbase API. To begin, initialize the Crawling API class with your Crawlbase token. Then, you can make GET requests by providing the URL you want to scrape and any desired options, such as custom user agents or response formats. For example, you can scrape a web page and access its content like this:
from crawlbase import CrawlingAPI
# Initialize the CrawlingAPI class
api = CrawlingAPI({ 'token': 'YOUR_CRAWLBASE_TOKEN' })
# Make a GET request to scrape a webpage
response = api.get('https://www.example.com')
if response['status_code'] == 200:
print(response['body'])
This library simplifies the process of fetching web data and is particularly useful for scenarios where dynamic content, IP rotation, and other advanced features of the Crawlbase API are required.
Crawling DeviantArt Search Page
Now that we're equipped with an understanding of DeviantArt and a configured environment, let's dive into the exciting process of crawling the DeviantArt Search Page. This section will walk you through importing the necessary libraries, constructing the URL for the search, and making API requests using the Crawlbase Crawling API to retrieve HTML content.
Importing Necessary Libraries
Open your favorite Python editor or create a new Python script file. To initiate our crawling adventure, we need to equip ourselves with the right tools. Import the required libraries into your Python script:
from crawlbase import CrawlingAPI
Here, we bring in the CrawlingAPI class from Crawlbase, ensuring we have the capabilities to interact with the Crawling API.
Constructing the URL for DeviantArt Search
Now, let's construct the URL for our DeviantArt search. Suppose we want to explore digital art with the keyword "fantasy." The URL construction might look like this:
# Replace 'YOUR_CRAWLBASE_TOKEN' with your actual Crawlbase API token
api_token = 'YOUR_CRAWLBASE_TOKEN'
crawlbase_api = CrawlingAPI({ 'token': api_token })
base_url = "https://www.deviantart.com"
keyword = "fantasy"
search_url = f"{base_url}/search?q={keyword}"
Making API Requests with Crawlbase Crawling API to Retrieve HTML
With our URL ready, let's harness the power of the Crawlbase Crawling API to retrieve the HTML content of the DeviantArt Search Page:
# Making the API request
response = crawlbase_api.get(search_url)
# Check if the request was successful
if response['status_code'] == 200:
# Extracted HTML content after decoding byte data
html_content = response['body'].decode('latin1')
print(html_content)
else:
print(f"Request failed with status code {response['status_code']}: {response['body']}")
In this snippet, we've used the get method of the CrawlingAPI class to make a request to the constructed search URL. The response is then checked for success, and if successful, the HTML content is extracted for further exploration.
Running Your Script
Now that your script is ready, save it with a .py extension, for example, deviantart_scraper.py. Open your terminal or command prompt, navigate to the script's directory, and run:
python deviantart_scraper.py
Replace deviantart_scraper.py with the actual name of your script. Press Enter, and your script will execute, initiating the process of crawling the DeviantArt Search Page.
Example Output:
With these steps, we've initiated the crawling process of the DeviantArt Search Page. In the upcoming sections, we'll delve deeper into parsing and extracting image URLs, bringing us closer to the completion of our DeviantArt Scraper.
Handling Pagination
Navigating through multiple pages is a common challenge when scraping websites with extensive content, and DeviantArt is no exception. In this section, we'll delve into the intricacies of handling pagination, ensuring our DeviantArt scraper efficiently captures a broad range of search results.
Understanding Pagination in DeviantArt
DeviantArt structures search results across multiple pages to manage and present content systematically. Each page typically contains a subset of results, and users progress through these pages to explore additional content. Understanding this pagination system is essential for our scraper to collect a comprehensive dataset.
Modifying API Requests for Multiple Pages
To adapt our scraper for pagination, we'll need to modify our API requests dynamically as we move through different pages. Consider the following example:
# Assuming 'page_number' is the variable representing the page number
page_number = 10 # Change this to the desired page number
# Modify the search URL to include the page number
search_url = f"{base_url}/search?q={keyword}&page={page_number}"
In this snippet, we've appended &page={page_number} to the search URL to specify the desired page. As our scraper progresses through pages, we can update the page_number variable accordingly.
Ensuring Efficient Pagination Handling
Efficiency is paramount when dealing with pagination to prevent unnecessary strain on resources. Consider implementing a loop to systematically iterate through multiple pages. Lets update the script from previous section to incorporate the pagination:
from crawlbase import CrawlingAPI
def scrape_page(api, base_url, keyword, page_number):
# Construct the URL for the current page
current_page_url = f"{base_url}/search?q={keyword}&page={page_number}"
# Make the API request and extract HTML content
response = api.get(current_page_url)
if response['status_code'] == 200:
# Extracted HTML content after decoding byte data
html_content = response['body'].decode('latin1')
# Implement your parsing and data extraction logic here
# For example, parse html_content and extract relevant data
# For now, returning a placeholder list
return [f"Data from page {page_number}"]
else:
print(f"Request for {current_page_url} failed with status code {response['status_code']}: {response['body']}")
return None
def main():
# Replace 'YOUR_CRAWLBASE_TOKEN' with your actual Crawlbase API token
api_token = 'YOUR_CRAWLBASE_TOKEN'
crawlbase_api = CrawlingAPI({ 'token': api_token })
base_url = "https://www.deviantart.com"
keyword = "fantasy"
total_pages = 10
# Iterate through pages and scrape data
for page_number in range(1, total_pages + 1):
# Scrape the current page
data_from_page = scrape_page(crawlbase_api, base_url, keyword, page_number)
if data_from_page:
print(data_from_page) # Modify as needed based on your data structure
if __name__ == "__main__":
main()
The scrape_page function encapsulates the logic for constructing the URL, making an API request, and handling the HTML content extraction. It checks the response status code and, if successful (status code 200), processes the HTML content for data extraction. The main function initializes the Crawlbase API, sets the base URL, keyword, and total number of pages to scrape. It then iterates through the specified number of pages, calling the scrape_page function for each page. The extracted data, represented here as a placeholder list, is printed for demonstration purposes.
In the next sections, we will delve into the detailed process of parsing HTML content to extract image URLs and implementing mechanisms to download these images systematically.
Parsing and Extracting Image URLs
Now that we've successfully navigated through multiple pages, it's time to focus on parsing and extracting valuable information from the HTML content. In this section, we'll explore how to inspect the DeviantArt Search Page for CSS selectors, utilize these selectors for image extraction, clean the extracted URLs, and finally, store the data in both CSV and SQLite formats.
Inspecting DeviantArt Search Page for CSS Selectors
Before we can extract image URLs, we need to identify the HTML elements that contain the relevant information. Right-click on the web page, select "Inspect" (or "Inspect Element"), and navigate through the HTML structure to find the elements containing the image URLs.
For example, DeviantArt structure its image URLs within HTML tags like:
<a
data-hook="deviation_link"
href="https://www.deviantart.com/siobhan-o-wisp/art/Owl-6-925596734"
aria-label="Owl #6 by Siobhan-o-wisp, visual art"
>
<div
class="_3_LJY"
aria-hidden="true"
data-testid="thumb"
typeof="ImageObject"
vocab="https://schema.org/"
style="width: 233px; height: 279px"
>
<img
alt="Owl #6"
src="src_url_here"
srcset="srcset_url_here"
property="contentUrl"
style="width: 233px; height: 279px; object-fit: cover; object-position: 50% 100%"
/>
</div>
</a>
In this case, the CSS selector for the image URL could be a[data-hook="deviation_link"] img[property="contentUrl"].
Utilizing CSS Selectors for Extracting Image URLs
Let's integrate the parsing logic into our existing script. By using the BeautifulSoup library, we can parse the HTML content and extract image URLs based on the identified CSS selectors. Update the scrape_page function to include the parsing logic using CSS selectors.
from crawlbase import CrawlingAPI
from bs4 import BeautifulSoup
import json
def scrape_page(api, base_url, keyword, page_number):
# Construct the URL for the current page
current_page_url = f"{base_url}/search?q={keyword}&page={page_number}"
# Make the API request and extract HTML content
response = api.get(current_page_url)
if response['status_code'] == 200:
# Extracted HTML content after decoding byte data
html_content = response['body'].decode('latin1')
# Implement your parsing and data extraction logic here
parsed_data = []
soup = BeautifulSoup(html_content, 'html.parser')
# Example CSS selector for image URLs
image_selector = 'a[data-hook="deviation_link"] img[property="contentUrl"]'
# Extracting and cleaning image URLs using the CSS selector
image_elements = soup.select(image_selector)
for image_element in image_elements:
# Extracting raw image URL
image_url = image_element['src'].strip()
parsed_data.append({'image_url': image_url})
return parsed_data
else:
print(f"Request for {current_page_url} failed with status code {response['status_code']}: {response['body']}")
return None
def main():
# Replace 'YOUR_CRAWLBASE_TOKEN' with your actual Crawlbase API token
api_token = 'YOUR_CRAWLBASE_TOKEN'
crawlbase_api = CrawlingAPI({ 'token': api_token })
base_url = "https://www.deviantart.com"
keyword = "fantasy"
total_pages = 2
# Iterate through pages and scrape data
all_data = []
for page_number in range(1, total_pages + 1):
# Scrape the current page
data_from_page = scrape_page(crawlbase_api, base_url, keyword, page_number)
if data_from_page:
all_data.extend(data_from_page)
# Print or save all product details
print(json.dumps(all_data, indent=2))
if __name__ == "__main__":
main()
scrape_page(api, base_url, keyword, page_number): This function takes parameters for the Crawlbase API instance api, the base URL base_url, a search keyword keyword, and the page number page_number. It constructs the URL for the current page, makes a request to the Crawlbase API to retrieve the HTML content, and then extracts image URLs from the HTML using BeautifulSoup. The CSS selector used for image URLs is 'a[data-hook="deviation_link"] img[property="contentUrl"]'. The extracted image URLs are stored in a list of dictionaries parsed_data.
main(): This function is the main entry point of the script. It initializes the Crawlbase API with a provided token, sets the base URL to "https://www.deviantart.com," specifies the search keyword as "fantasy," and defines the total number of pages to scrape (in this case, 2). It iterates through the specified number of pages, calling the scrape_page function for each page and appending the extracted data to the all_data list. Finally, it prints the extracted data in a formatted JSON representation using json.dumps.
Example Output:
[
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/36b9a048-0833-460c-a2f0-3a4d1c029340/de9ysag-ad79d0fb-4de7-4bd9-9223-c7c38feecc5a.png/v1/fill/w_462,h_250,q_70,strp/jungle_tombs_by_rajanandepu_de9ysag-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NjkzIiwicGF0aCI6IlwvZlwvMzZiOWEwNDgtMDgzMy00NjBjLWEyZjAtM2E0ZDFjMDI5MzQwXC9kZTl5c2FnLWFkNzlkMGZiLTRkZTctNGJkOS05MjIzLWM3YzM4ZmVlY2M1YS5wbmciLCJ3aWR0aCI6Ijw9MTI4MCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.G3TyS8DU1qgsA9V6gmXA2bhAABHAB-YlqYyusaKu2W8"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/31ca8292-e979-4e41-a025-8b13994f6690/d9iwdru-5a282fd0-bd6f-4904-9ec0-34a471c0e96f.jpg/v1/crop/w_163,h_250,x_0,y_0,scl_0.16717948717949,q_70,strp/fairy_bay_by_darekzabrocki_d9iwdru-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9MTUwMCIsInBhdGgiOiJcL2ZcLzMxY2E4MjkyLWU5NzktNGU0MS1hMDI1LThiMTM5OTRmNjY5MFwvZDlpd2RydS01YTI4MmZkMC1iZDZmLTQ5MDQtOWVjMC0zNGE0NzFjMGU5NmYuanBnIiwid2lkdGgiOiI8PTk3NSJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.T79tGh8ikSpiB0bgTgRiPj_jErhylF6FzhOh9V_26Hw"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/b0069016-7cd6-4fff-b1ae-242d4172d5b4/de8zc6a-b87e753d-3657-4cf2-af4d-d55043b88486.jpg/v1/fit/w_414,h_245,q_70,strp/fantasy_maps_art_coomiissions_for_steven_by_threeanglework_de8zc6a-414w.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NjA1IiwicGF0aCI6IlwvZlwvYjAwNjkwMTYtN2NkNi00ZmZmLWIxYWUtMjQyZDQxNzJkNWI0XC9kZTh6YzZhLWI4N2U3NTNkLTM2NTctNGNmMi1hZjRkLWQ1NTA0M2I4ODQ4Ni5qcGciLCJ3aWR0aCI6Ijw9MTAyNCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.SWEVlwSLHEY7I0Agl2IVMKxylq0LTX3Xvee57lbnoJQ"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/7665f267-607e-41b3-93d4-d44b75b58e37/dexmkcy-8daa7a57-febe-4b40-bc06-ca2edf4355a4.jpg/v1/fill/w_670,h_350,q_70,strp/city_of_elves_by_panjoool_dexmkcy-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NjcwIiwicGF0aCI6IlwvZlwvNzY2NWYyNjctNjA3ZS00MWIzLTkzZDQtZDQ0Yjc1YjU4ZTM3XC9kZXhta2N5LThkYWE3YTU3LWZlYmUtNGI0MC1iYzA2LWNhMmVkZjQzNTVhNC5qcGciLCJ3aWR0aCI6Ijw9MTI4MCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.F6h5UrGiIOe0ct6XH2EP5g6sB06TI0TQDZa7yq08shM"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/38961eb5-6954-4066-a5b4-74c4c17bba02/dessk9p-898c4573-2759-4e13-8c6e-c6af5893cb77.png/v1/fill/w_566,h_350/magic_forest_by_postapodcast_dessk9p-350t.png?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NzkyIiwicGF0aCI6IlwvZlwvMzg5NjFlYjUtNjk1NC00MDY2LWE1YjQtNzRjNGMxN2JiYTAyXC9kZXNzazlwLTg5OGM0NTczLTI3NTktNGUxMy04YzZlLWM2YWY1ODkzY2I3Ny5wbmciLCJ3aWR0aCI6Ijw9MTI4MCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.aZ3GIu_6Jnj1k6w9ci7KRrzCdWTSTD__fJUZaKUBayw"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/8fd505b7-1d62-42fa-ae28-60294fb112fa/da4h819-5434889d-db48-41c0-a548-15ffb704ffc7.jpg/v1/fill/w_700,h_329,q_70,strp/the_grand_gate_by_merl1ncz_da4h819-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NzA1IiwicGF0aCI6IlwvZlwvOGZkNTA1YjctMWQ2Mi00MmZhLWFlMjgtNjAyOTRmYjExMmZhXC9kYTRoODE5LTU0MzQ4ODlkLWRiNDgtNDFjMC1hNTQ4LTE1ZmZiNzA0ZmZjNy5qcGciLCJ3aWR0aCI6Ijw9MTUwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.wBoGmmno1N26VvCPVDR2pdkCNP_rYpxxo_dmQdYvSXc"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/6ff2ccfb-d302-4348-87bc-8b9568748e63/d8ox1uh-3baf219c-0bac-47fa-b227-c89a8134845c.jpg/v1/fill/w_657,h_350,q_70,strp/journey_home_ii_by_jjcanvas_d8ox1uh-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NjgyIiwicGF0aCI6IlwvZlwvNmZmMmNjZmItZDMwMi00MzQ4LTg3YmMtOGI5NTY4NzQ4ZTYzXC9kOG94MXVoLTNiYWYyMTljLTBiYWMtNDdmYS1iMjI3LWM4OWE4MTM0ODQ1Yy5qcGciLCJ3aWR0aCI6Ijw9MTI4MCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.r83EO9Verq40yofAO0J5aaxk39zI_3Km8xy9IhcHTJU"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/0f32ddfc-07dd-4afe-bcfd-60218bd1c565/d9woys6-489490fe-e3f3-493d-b5dd-b74b36d72044.jpg/v1/fill/w_622,h_350,q_70,strp/wizard_overlord_by_88grzes_d9woys6-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NTc2IiwicGF0aCI6IlwvZlwvMGYzMmRkZmMtMDdkZC00YWZlLWJjZmQtNjAyMThiZDFjNTY1XC9kOXdveXM2LTQ4OTQ5MGZlLWUzZjMtNDkzZC1iNWRkLWI3NGIzNmQ3MjA0NC5qcGciLCJ3aWR0aCI6Ijw9MTAyNCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.CWF2dVY5FD_pY6In-SM4iSHUtKZ4LcWz7w4jckLSotM"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/677a3275-419d-415d-a4ee-fe2097a24e46/ddfkq9w-cc46d438-9640-428e-a1e7-986fdede405d.jpg/v1/fill/w_700,h_339,q_70,strp/fantasy_landscape_by_blueavel_ddfkq9w-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NDg0IiwicGF0aCI6IlwvZlwvNjc3YTMyNzUtNDE5ZC00MTVkLWE0ZWUtZmUyMDk3YTI0ZTQ2XC9kZGZrcTl3LWNjNDZkNDM4LTk2NDAtNDI4ZS1hMWU3LTk4NmZkZWRlNDA1ZC5qcGciLCJ3aWR0aCI6Ijw9MTAwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.qRJRzrqAUyn-IxUZovvdfIkqeQ4PyYFwO4PA5fZSVuw"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/cf4e3b17-25ab-486e-9863-1d2651123f7e/d45tdhb-2cceea9d-cf27-4325-92f0-9c8f8c406872.jpg/v1/fill/w_143,h_250,q_70,strp/fantasy_castle_by_peterconcept_d45tdhb-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9MTAwMCIsInBhdGgiOiJcL2ZcL2NmNGUzYjE3LTI1YWItNDg2ZS05ODYzLTFkMjY1MTEyM2Y3ZVwvZDQ1dGRoYi0yY2NlZWE5ZC1jZjI3LTQzMjUtOTJmMC05YzhmOGM0MDY4NzIuanBnIiwid2lkdGgiOiI8PTU3MSJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.5lnZruTFCmZkMar66M81rvQQloK8sCoZtIa6aqMOpVo"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/a0102abd-a974-49be-9415-5d6329de2615/d85kpn2-969091cf-bf6c-45e3-8431-e37425010343.jpg/v1/fill/w_500,h_250,q_70,strp/fantasy_city_by_britneypringle_d85kpn2-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NTEyIiwicGF0aCI6IlwvZlwvYTAxMDJhYmQtYTk3NC00OWJlLTk0MTUtNWQ2MzI5ZGUyNjE1XC9kODVrcG4yLTk2OTA5MWNmLWJmNmMtNDVlMy04NDMxLWUzNzQyNTAxMDM0My5qcGciLCJ3aWR0aCI6Ijw9MTAyNCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.WGMQEQnTucVFLQ734ScVyRUCJVuaNvucC8hx10KnSak"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/2f9d63ea-05a6-44f9-a06d-3c3506ace1a6/dc7rp7q-8cde501b-30a5-4c5b-a7c0-e8da6577d000.jpg/v1/fit/w_414,h_240,q_70,strp/mushy_land_by_raphael_lacoste_dc7rp7q-414w.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9OTI4IiwicGF0aCI6IlwvZlwvMmY5ZDYzZWEtMDVhNi00NGY5LWEwNmQtM2MzNTA2YWNlMWE2XC9kYzdycDdxLThjZGU1MDFiLTMwYTUtNGM1Yi1hN2MwLWU4ZGE2NTc3ZDAwMC5qcGciLCJ3aWR0aCI6Ijw9MTYwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.eFslHR3hiGwNnIsEWI82ZRXAfbrdGHZOHn2nBfRa_Qg"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/5676e946-eac5-462d-8385-566c5e7b4794/dek1geb-693d25d3-c206-409f-abb0-0fce7bf52b45.jpg/v1/fill/w_700,h_336,q_70,strp/homecoming_by_flaviobolla_dek1geb-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NzY5IiwicGF0aCI6IlwvZlwvNTY3NmU5NDYtZWFjNS00NjJkLTgzODUtNTY2YzVlN2I0Nzk0XC9kZWsxZ2ViLTY5M2QyNWQzLWMyMDYtNDA5Zi1hYmIwLTBmY2U3YmY1MmI0NS5qcGciLCJ3aWR0aCI6Ijw9MTYwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.VRn481jxhnjKhv47e9WMKclr0piK7T7ljM7IbMn42GU"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/35267649-f012-4cf7-9907-94a5d524e332/dcya6ht-644bdc7e-efbc-40a4-8fd3-727832ddd5ca.jpg/v1/fill/w_635,h_350,q_70,strp/fantasy_castle_012219_by_rich35211_dcya6ht-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9MTMwMSIsInBhdGgiOiJcL2ZcLzM1MjY3NjQ5LWYwMTItNGNmNy05OTA3LTk0YTVkNTI0ZTMzMlwvZGN5YTZodC02NDRiZGM3ZS1lZmJjLTQwYTQtOGZkMy03Mjc4MzJkZGQ1Y2EuanBnIiwid2lkdGgiOiI8PTIzNjAifV1dLCJhdWQiOlsidXJuOnNlcnZpY2U6aW1hZ2Uub3BlcmF0aW9ucyJdfQ.LYDYnkQTWyJWgjerl0PG8N8Qp64J98PAcMDt2_ngjGs"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/0c6e0590-011b-4912-bfe4-9353b6e5dc98/ddxqz6d-71e5fc4a-1d91-4cd4-b074-0cb826b70f84.jpg/v1/fill/w_199,h_250,q_70,strp/ramparts_by_eddie_mendoza_ddxqz6d-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9MTQ1MCIsInBhdGgiOiJcL2ZcLzBjNmUwNTkwLTAxMWItNDkxMi1iZmU0LTkzNTNiNmU1ZGM5OFwvZGR4cXo2ZC03MWU1ZmM0YS0xZDkxLTRjZDQtYjA3NC0wY2I4MjZiNzBmODQuanBnIiwid2lkdGgiOiI8PTExNTYifV1dLCJhdWQiOlsidXJuOnNlcnZpY2U6aW1hZ2Uub3BlcmF0aW9ucyJdfQ.0NFGpaE22d48MHr2PTfPQlDss07ec8iwKXGKtpRgq3c"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/aea046b5-589a-463d-9119-f40d956640f2/dewfvci-253919a9-25b6-43b0-87ba-4c99ddd766bd.jpg/v1/fill/w_200,h_250,q_70,strp/samurai_guardian___photoshop_art_by_phaserunner_dewfvci-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9MTMwMCIsInBhdGgiOiJcL2ZcL2FlYTA0NmI1LTU4OWEtNDYzZC05MTE5LWY0MGQ5NTY2NDBmMlwvZGV3ZnZjaS0yNTM5MTlhOS0yNWI2LTQzYjAtODdiYS00Yzk5ZGRkNzY2YmQuanBnIiwid2lkdGgiOiI8PTEwNDAifV1dLCJhdWQiOlsidXJuOnNlcnZpY2U6aW1hZ2Uub3BlcmF0aW9ucyJdfQ.pSPdQ7FqWJu_iqi1vJjmUuUBKOIOC_qtwathhKubLAc"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/6ff2ccfb-d302-4348-87bc-8b9568748e63/dagt780-aca17f21-148a-40f3-b27e-fb3795bdb274.jpg/v1/fill/w_444,h_250,q_70,strp/the_secret_entrance_by_jjcanvas_dagt780-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NzIwIiwicGF0aCI6IlwvZlwvNmZmMmNjZmItZDMwMi00MzQ4LTg3YmMtOGI5NTY4NzQ4ZTYzXC9kYWd0NzgwLWFjYTE3ZjIxLTE0OGEtNDBmMy1iMjdlLWZiMzc5NWJkYjI3NC5qcGciLCJ3aWR0aCI6Ijw9MTI4MCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.i44QkrqohRXgceqNI3b0x2ARW0UIJK2NDDDjPoSVZ9I"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/f240a8b1-06c4-4ffa-9ba0-853a80e54e12/des3vvj-a1c9c5bf-5311-45c4-96e9-b3078b0012da.png/v1/fill/w_163,h_250,q_70,strp/forest_journey_by_aszith_des3vvj-250t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9MTIyNyIsInBhdGgiOiJcL2ZcL2YyNDBhOGIxLTA2YzQtNGZmYS05YmEwLTg1M2E4MGU1NGUxMlwvZGVzM3Z2ai1hMWM5YzViZi01MzExLTQ1YzQtOTZlOS1iMzA3OGIwMDEyZGEucG5nIiwid2lkdGgiOiI8PTgwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.CHWmKX7b7Kswbv4XHh-YQlNzmHzc2DQsP5thVGP_iD0"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/d9752802-856c-4511-837b-6eadbdb551b8/devdavw-d59b805d-64a1-4a2c-be45-154ecc6c5617.jpg/v1/fill/w_622,h_350,q_70,strp/kingdom_by_oliverbeck_devdavw-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9MTA4MCIsInBhdGgiOiJcL2ZcL2Q5NzUyODAyLTg1NmMtNDUxMS04MzdiLTZlYWRiZGI1NTFiOFwvZGV2ZGF2dy1kNTliODA1ZC02NGExLTRhMmMtYmU0NS0xNTRlY2M2YzU2MTcuanBnIiwid2lkdGgiOiI8PTE5MjAifV1dLCJhdWQiOlsidXJuOnNlcnZpY2U6aW1hZ2Uub3BlcmF0aW9ucyJdfQ.D8s098xZS2g6ggPrl0Iw7rQzYf5OcWS8QKySdjg0GL4"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/0c6e0590-011b-4912-bfe4-9353b6e5dc98/ddn4c9i-8560bfd6-2236-47a5-8bf5-a73b5dc67328.jpg/v1/fill/w_643,h_350,q_70,strp/canal_town_by_eddie_mendoza_ddn4c9i-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9OTI1IiwicGF0aCI6IlwvZlwvMGM2ZTA1OTAtMDExYi00OTEyLWJmZTQtOTM1M2I2ZTVkYzk4XC9kZG40YzlpLTg1NjBiZmQ2LTIyMzYtNDdhNS04YmY1LWE3M2I1ZGM2NzMyOC5qcGciLCJ3aWR0aCI6Ijw9MTcwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.xgGzUkprTYO2Tg4vvz7Ctq56tFR58q4mNxhpoMl_14Y"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/882eb67f-8d3f-470f-a043-0225b551ee06/da6chgs-f1f4e973-92eb-4b59-b60d-b31fea9a7611.jpg/v1/fill/w_700,h_324,q_70,strp/fantasy_landscape_5_by_daisanvisart_da6chgs-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9NDE3IiwicGF0aCI6IlwvZlwvODgyZWI2N2YtOGQzZi00NzBmLWEwNDMtMDIyNWI1NTFlZTA2XC9kYTZjaGdzLWYxZjRlOTczLTkyZWItNGI1OS1iNjBkLWIzMWZlYTlhNzYxMS5qcGciLCJ3aWR0aCI6Ijw9OTAwIn1dXSwiYXVkIjpbInVybjpzZXJ2aWNlOmltYWdlLm9wZXJhdGlvbnMiXX0.5d8EegjXzeJ8ePHg5ZhzmHfJl6kSLf--vFK2ghEuj08"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/7665f267-607e-41b3-93d4-d44b75b58e37/dem904a-235a588a-34b6-42e6-94ec-2496d7e61773.jpg/v1/fill/w_684,h_350,q_70,strp/the_kingdom_by_panjoool_dem904a-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9OTg0IiwicGF0aCI6IlwvZlwvNzY2NWYyNjctNjA3ZS00MWIzLTkzZDQtZDQ0Yjc1YjU4ZTM3XC9kZW05MDRhLTIzNWE1ODhhLTM0YjYtNDJlNi05NGVjLTI0OTZkN2U2MTc3My5qcGciLCJ3aWR0aCI6Ijw9MTkyMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.g6vuGPKnGtajUm_h9iQRaufGZ2K4BkDtURK9AXXjmls"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/6ff2ccfb-d302-4348-87bc-8b9568748e63/dcozqaf-5514dcfe-1363-4eac-9929-a9605ef2b140.jpg/v1/fill/w_595,h_350,q_70,strp/forgotten_kingdoms_iv_by_jjcanvas_dcozqaf-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9ODIzIiwicGF0aCI6IlwvZlwvNmZmMmNjZmItZDMwMi00MzQ4LTg3YmMtOGI5NTY4NzQ4ZTYzXC9kY296cWFmLTU1MTRkY2ZlLTEzNjMtNGVhYy05OTI5LWE5NjA1ZWYyYjE0MC5qcGciLCJ3aWR0aCI6Ijw9MTQwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.fh4lMrrTAj8LKRVn0dzvmV_oRSpvJsppbK6ipuJBciY"
},
{
"image_url": "https://images-wixmp-ed30a86b8c4ca887773594c2.wixmp.com/f/4b0bb084-0057-48cf-92b4-7319629b576c/damprvc-31559c47-6da4-461c-b218-0a15bd7ee31e.jpg/v1/fill/w_700,h_298,q_70,strp/a_new_friend_by_grivetart_damprvc-350t.jpg?token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ1cm46YXBwOjdlMGQxODg5ODIyNjQzNzNhNWYwZDQxNWVhMGQyNmUwIiwiaXNzIjoidXJuOmFwcDo3ZTBkMTg4OTgyMjY0MzczYTVmMGQ0MTVlYTBkMjZlMCIsIm9iaiI6W1t7ImhlaWdodCI6Ijw9ODUxIiwicGF0aCI6IlwvZlwvNGIwYmIwODQtMDA1Ny00OGNmLTkyYjQtNzMxOTYyOWI1NzZjXC9kYW1wcnZjLTMxNTU5YzQ3LTZkYTQtNDYxYy1iMjE4LTBhMTViZDdlZTMxZS5qcGciLCJ3aWR0aCI6Ijw9MjAwMCJ9XV0sImF1ZCI6WyJ1cm46c2VydmljZTppbWFnZS5vcGVyYXRpb25zIl19.BYESPqEjOAWFf4FVrBDlGfn4sXJbcUSJG_otWz7Qppg"
}
]
Storing Extracted Data in CSV and SQLite Database
Now, let's update the main function to handle the extracted data and store it in both CSV and SQLite formats.
import sqlite3
from crawlbase import CrawlingAPI
from bs4 import BeautifulSoup
import pandas as pd
def initialize_database(db_filename='deviantart_data.db'):
conn = sqlite3.connect(db_filename)
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS deviantart_data (
id INTEGER PRIMARY KEY,
image_url TEXT
)
''')
# Commit changes and close the connection
conn.commit()
conn.close()
def insert_data_into_database(data, db_filename='deviantart_data.db'):
conn = sqlite3.connect(db_filename)
cursor = conn.cursor()
# Insert data into the table
for row in data:
cursor.execute('INSERT INTO deviantart_data (image_url) VALUES (?)', (row['image_url'],))
# Commit changes and close the connection
conn.commit()
conn.close()
def scrape_page(api, base_url, keyword, page_number):
# Construct the URL for the current page
current_page_url = f"{base_url}/search?q={keyword}&page={page_number}"
# Make the API request and extract HTML content
response = api.get(current_page_url)
if response['status_code'] == 200:
# Extracted HTML content after decoding byte data
html_content = response['body'].decode('latin1')
# Implement your parsing and data extraction logic here
parsed_data = []
soup = BeautifulSoup(html_content, 'html.parser')
# Example CSS selector for image URLs
image_selector = 'a[data-hook="deviation_link"] img[property="contentUrl"]'
# Extracting and cleaning image URLs using the CSS selector
image_elements = soup.select(image_selector)
for image_element in image_elements:
# Extracting raw image URL
image_url = image_element['src'].strip()
parsed_data.append({'image_url': image_url})
return parsed_data
else:
print(f"Request for {current_page_url} failed with status code {response['status_code']}: {response['body']}")
return None
def main():
# Replace 'YOUR_CRAWLBASE_TOKEN' with your actual Crawlbase API token
api_token = 'YOUR_CRAWLBASE_TOKEN'
crawlbase_api = CrawlingAPI({ 'token': api_token })
base_url = "https://www.deviantart.com"
keyword = "fantasy"
total_pages = 2
# Iterate through pages and scrape data
all_data = []
for page_number in range(1, total_pages + 1):
# Scrape the current page
data_from_page = scrape_page(crawlbase_api, base_url, keyword, page_number)
if data_from_page:
all_data.extend(data_from_page)
# Store all data into CSV using Pandas
df = pd.DataFrame(all_data)
csv_filename = 'deviantart_data.csv'
df.to_csv(csv_filename, index=False, encoding='utf-8')
# Call the initialize_database function
initialize_database()
# Insert all data into the database
insert_data_into_database(all_data)
if __name__ == "__main__":
main()
- For CSV storage, the script uses the Pandas library to create a DataFrame df from the extracted data and then writes the DataFrame to a CSV file
deviantart_data.csvusing the to_csv method. - For SQLite database storage, the script initializes the database using the
initialize_databasefunction and inserts the extracted data into thedeviantart_datatable using theinsert_data_into_databasefunction. The database filedeviantart_data.dbis created and updated with each run of the script, and it includes the ID and image URL columns for each record.
deviantart_data.csv preview:

deviantart_data.db preview:

Downloading Images from Scraped Image URLs
This section will guide you through the process of utilizing Python to download images from URLs scraped from DeviantArt, handling potential download errors, and organizing the downloaded images efficiently.
Using Python to Download Images
Python offers a variety of libraries for handling HTTP requests and downloading files. One common and user-friendly choice is the requests library. Below is a basic example of how you can use it to download an image:
import requests
def download_image(url, save_path):
try:
response = requests.get(url, stream=True)
response.raise_for_status()
with open(save_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"Image downloaded successfully: {save_path}")
except requests.exceptions.RequestException as e:
print(f"Error downloading image from {url}: {e}")
# Example usage
image_url = "https://example.com/image.jpg"
download_path = "downloaded_images/image.jpg"
download_image(image_url, download_path)
This function, download_image, takes an image URL and a local path where the image should be saved. It then uses the requests library to download the image.
Organizing Downloaded Images
Organizing downloaded images into a structured directory can greatly simplify further processing. Consider creating a folder structure based on categories, keywords, or any other relevant criteria. Here's a simple example of how you might organize downloaded images:
downloaded_images/
|-- fantasy/
| |-- image1.jpg
| |-- image2.jpg
|-- sci-fi/
| |-- image3.jpg
| |-- image4.jpg
This organization can be achieved by adjusting the download_path in the download_image function based on the category or any relevant information associated with each image.
With these steps, you'll be equipped to not only download images from DeviantArt but also handle errors effectively and organize the downloaded images for easy access and further analysis.
Final Words
I hope now you are able to easily download and scrape Images from DeviantArt using Python and the Crawlbase Crawling API. And also, by using Python and checking out the DeviantArt Search Pages, you've learned how to take out and organize picture links effectively.
Whether you're making a collection of digital art or trying to understand what's on DeviantArt, it's important to scrape the web responsibly. Always follow the rules of the platform and be ethical.
Now that you have these useful skills, you can start scraping the web on your own. If you run into any problems, you can ask the Crawlbase support team for help.
Frequently Asked Questions
Q. Is web scraping on DeviantArt legal?
While web scraping itself is generally legal, it's essential to navigate within the boundaries set by DeviantArt's terms of service. DeviantArt Scraper operates with respect for ethical scraping practices. Always review and comply with DeviantArt's guidelines to ensure responsible and lawful use.
Q. How can I handle pagination when scraping DeviantArt?
Managing pagination in DeviantArt involves constructing URLs for various pages in the search results. The guide illustrates how to adjust API requests for multiple pages, enabling a smooth traversal through the DeviantArt Search Pages. This ensures comprehensive data retrieval for a thorough exploration.
Q. Can I customize the data I scrape from DeviantArt?
Absolutely. The guide provides insights into inspecting the HTML structure of DeviantArt Search Pages and leveraging CSS selectors. This customization empowers you to tailor your data extraction, allowing you to focus on specific information like image URLs. Adapt the scraping logic to suit your individual needs and preferences.
Q. What are the benefits of storing data in both CSV and SQLite formats?
Storing data in CSV and SQLite formats offers a versatile approach. CSV facilitates easy data sharing and analysis, making it accessible for diverse applications. On the other hand, SQLite provides a lightweight database solution, ensuring efficient data retrieval and management within your Python projects. This dual-format approach caters to different use cases and preferences.


















