In today's economy, more and more companies exist primarily online. While there's much discussion around the consequences of leaving behind the traditional brick and mortar business, one aspect that gets less attention is the significant change in how these companies are now managing their data. Increasingly, businesses seek to understand their customers and how best to meet their needs in a way that monthly reports and KPI charts just can’t address. Many of the modern ideas around delivering a compelling online shopping experience, such as "frequently bought together" recommendations and "people who bought this were also interested in that" simply didn’t exist when many of the database systems in use today were first designed. Which means that trying to use them in these situations can sometimes feel a bit like trying to fit a square peg in a round hole.
Take a simple example like an online pet supply store. They could go down the path of building a conventional site backed by a relational database, receiving orders and doing their best to ship them quickly. Occasionally they might even engage with their customers via email, sending out monthly specials in the hope of increasing their turnover. But this approach isn't likely to perform especially well in a crowded marketplace because it offers nothing personal. The business doesn't really understand how their customers interact with their site on an individual level because their choice of database, and by extension the site it supports, isn't built to handle and interpret that kind of data. To properly understand data of this type requires an approach that emphasizes how entities truly interact with each other, and captures the full context of each interaction. In short, it requires a graph database.
Graph Databases
Graph databases represent an innovative, powerful approach to solving the problem of connected data in a way that is closer to how we as humans think about data. This technology is relatively new but shouldn’t be considered fringe. A recent survey by DATAVERSITY indicated almost twenty-five percent of companies intend to use graph databases in the next two years. They’ve been referred to as the “go-to” databases of the 2020s, but why? In this article we'll look into how graph databases work, what sets them apart and the benefits they can bring to to your application.
What Is a Graph Database?
A graph database represents a more flexible and intuitive approach to storing data. While most database engines only support data that can be represented as a series of tables tied together with logical connections (via foreign-key constraints, for example), graph databases take an approach based on two simple but very powerful concepts––nodes and relationships. Nodes represent things or objects in the domain (often nouns), while relationships indicate how they interact and relate to each other (often verbs). Say our online pet store wanted to get to know their customers better and start recording what kind of pets each has. Here's how they'd get started with a graph:
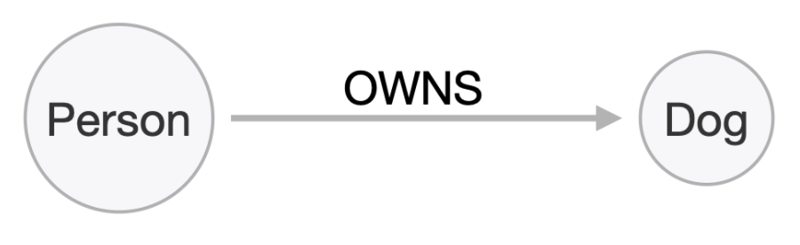
Only two nodes are required to begin with, Person and Dog, and a relationship between them, OWNS. Relationships in a graph database are directed, indicated by the arrow––the person owns the dog, not the other way around. With this basic fact established, we can start to add more context:
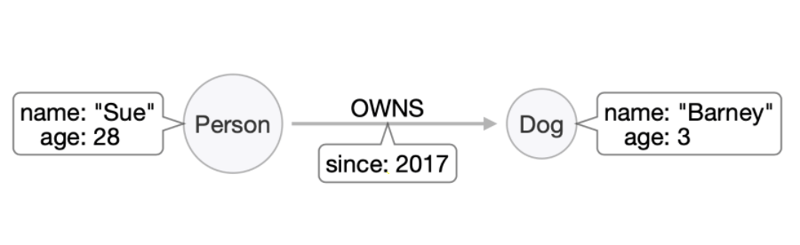
Now our Person and Dog nodes each have name and age properties, and the relationship records how long Sue has owned Barney. Notice how we’ve attached properties to both nodes and relationships in the same way. This is possible because graphs, unlike relational databases, treat relationships as first class citizens––their role in the database is just as important, sometimes even more so, than the nodes they’re connecting.
The great part about graphs, even simple examples like this one, is that not only is this the way the data is stored, it’s probably how you’d sketch it out when designing your data model to begin with. Graphs are inherently whiteboard friendly, making them a great choice when working with non-technical teams, or when you need to start simple and add context as you go.
What if Sue decided to get a cat, too? That would just require adding another node and connecting it to Sue with a new OWNS relationship. Now Sue has a cat and a dog that can each be accessed in the same way:
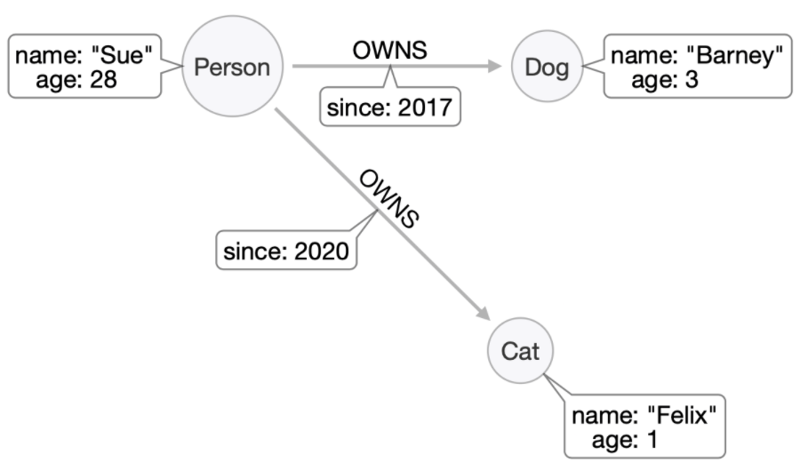
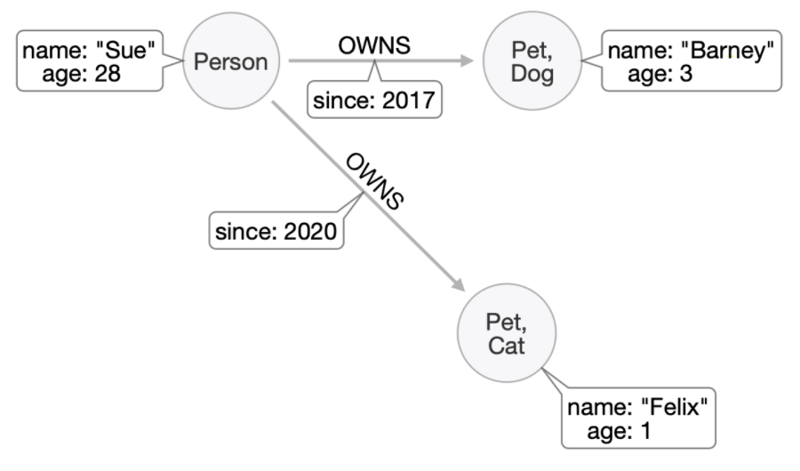
We might also want to retrieve Sue’s pets together, perhaps to get a sense of how many pets on average each customer has. Nodes can be given as many labels as required, so while we can label them Dog and Cat to separate them, we can also label them both Pet to group them together:
Comparing Graph Databases to Relational Databases
This process of continuously adding more data while still maintaining clear logic shows how easy it is to evolve a graph database to meet your requirements as they change. Contrast this with how you might model the above scenario in a relational database that could handle multiple owners, pets, and their relationships in the same way:
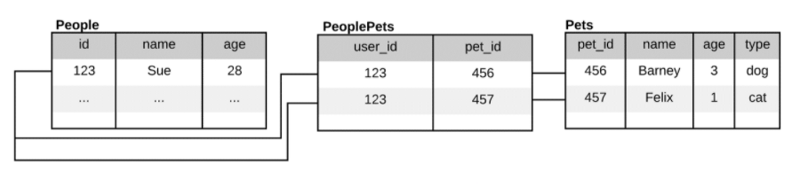
Realistically, you’d need at least three tables, each with a foreign key to join them together. To retrieve any meaningful facts, you’d have to load data from all of them at once, specifying your joining logic each time. All just to achieve the same context that our graph was able to do with only three nodes and two relationships. The difference is stark and only becomes more apparent as the size and complexity of your data model increases.
Other ways the experience of using a graph database compares to a relational database include:
- More descriptive queries––implementations vary across platforms, but most graph databases come equipped with highly descriptive, imperative query languages that let you explain what you want, not how you want it. Cypher, the query language used in Neo4j, could retrieve the data for Sue and her pets sketched above using simply:
MATCH (s:Person {name:"Sue"})-[r:OWNS]->(p:Pet)
This simple, easy to understand query makes available all properties of the Person (s), each Pet (p), and the relationships that bind them (r). If we add more properties to any of these at a later date, they'll automatically be returned, too. Anyone who's tried their hand at ASCII art will appreciate the clarity the syntax inherently communicates (nodes are wrapped in regular brackets, relationships in square ones). Contrast this against a relational query, which would require something like:
SELECT People.*, Pets.* FROM People JOIN PeoplePets ON People.id = PeoplePets.id JOIN Pets ON PeoplePets.pet_id = Pets.pet_id WHERE People.id = 123;
The nature of the relationship has to be spelled out, each and every time you want to traverse it. If the names or data types of those columns change for any reason, you'll also need to update your joining syntax. This kind of problem is avoided in graph databases because relationships simply connect two nodes, without requiring join semantics.
Greater flexibility in adapting your model––no real world data model remains static for long. Businesses may change their objectives or want to test out new ideas without requiring lengthy database rebuilds. With graph databases, it's easy to add labels to nodes, properties to relationships, or refactor large sections of your graph. There are no foreign key constraints to consider like in relational databases or tables to clean up when the data is gone. You'll spend more time focusing on the data itself and less focusing on the data infrastructure.
Greater performance when traversing data relationships––native graph databases are optimized to store data in a way that matches the notion of what it represents. This means that Sue and her two Pets, while completely separate nodes that could have been created years apart, will be written to file as close to each other as possible. This allows for faster retrieval of related data than a relational database, which will often fragment table data to different areas of a disk depending on when it was created.
What Kind of Data Works Best in a Graph Database?
Graph databases are most useful when handling data containing relationships that have important associated context. An online store getting to know and interact with their customer base is a great example, but graphs can do more than this. Other applications include:
- Knowledge graphs––organizations such as NASA use graph databases to record the logical connections between their experiments and projects, meaning that future endeavors can take advantage of work already completed to improve efficiency and avoid repeating mistakes.
- Recommendation engines––an integral part of online commerce, recommendation engines provide users with suggested products and services that are more likely to be of interest based on comparing user behaviors with others who have made similar purchases.
- Supply chain management––modern production processes often depend on materials and components from a variety of different locations, so understanding the dependencies in a distributed process is critical. A graph database can provide the means to identify single points of failure, providing a path to properly implement the right kind of protections and safeguards that ensure a more resilient design.
An Easy Way to Try Graph Databases
The best way, of course, to learn a new technology is to try it out. For graph databases, Neo4j is a great graph database for experimentation. It's the market leader, with a diverse based of users from data-science enthusiasts to multinational corporations. There is an established community around the platform and a wealth of documentation available.
To quickly try out Neo4j, consider using a vendor-hosted solution that can get you started in minutes and remove the need to set up and configure your own server. Amazon, for example, offers an easy deployment of Neo4j. And Heroku, a PaaS solution, has a GrapheneDB (Heroku’s Neo4j offering) service that can be deployed, for free, in multiple versions, along with a template app and a demo app that can speed up the learning curve. Most vendor-hosted solutions should offer something similar.
Conclusion
Choosing the right database for your application is an important step in ensuring its ability to succeed, both at release and in the future. If you're looking at a project where the interaction of your data is a key aspect of the domain, consider using a graph database to give you an edge in both implementation and performance.


















