Over the past four years, the Heroku Runtime team has transitioned from occasional, manual deployments to continuous, automated deployments. Changes are now rolled out globally within a few hours of merging any change—without any human intervention. It's been an overwhelmingly positive experience for us. This doc describes why we decided to make the change, how we did it, and what we learned along the way.
Where We Started
Heroku’s Runtime team builds and operates Heroku’s Private Space (single-tenant) and Common Runtime (multi-tenant) platforms, from container orchestration to routing and logging. When I joined the team in 2016, the process for deploying changes to a component looked something like this:
- If it's Friday, wait until the next week
- If you have less than 3 hours to monitor or respond to issues, wait to deploy
- Join the operations channel in Slack
- Share your plans in the channel and get sign-off from the team-member who is primary on-call that week
- Open the platform integration test dashboard
- Open any relevant monitoring dashboards for the service
- Actually deploy the change
- Monitor dashboards for anomalies
- Monitor the operations channel for notifications and alerts
- Wait a while...
- ... and then repeat for the next region or service as needed
The process was manual, repetitive, and required coordination and extra approvals. It was toilsome. However, it also served the team well for a long time! In particular, at that time the team was small, owned few services, and had just two production environments (US and EU).
Notice that this process already relies on some important properties of the system and the engineering environment within Heroku:
- Changes were released as often as the team was comfortable and had time to respond to emerging issues.
- Changes were rolled out as a pipeline into environments in order of blast-radius.
- Heroku has a platform integration testing service (called Direwolf) which continuously runs a suite of tests against the platform in all regions and reports status.
- There were metrics dashboards and alerts to understand the service health and debug issues.
- These properties would help us transition from this toilsome process to one that was automated and continuous.
Why Automated Continuous Delivery?
We understood that there were opportunities to improve the deployment process, but it worked well enough most of the time that it wasn't a big priority. It was toil, but it was manageable. However, what passes for manageable changes as systems evolve, and two particular things changed that forced us to re-evaluate how we managed deployments:
- The team rapidly grew from a handful of engineers to over 30.
- We undertook a long-range project to refactor Heroku’s Common Runtime which would both shard our production environments and begin to decompose our monolithic app into multiple services.
Between these two changes, we knew it wouldn’t be sustainable to simply make incremental changes to the existing workflow; we had to bite the bullet and move to a fully automated and continuous deployment model.
Increasing Deployment Complexity
The primary control system for the Common Runtime was a monolithic Ruby application, which changed infrequently (< 1 change per week) and was running in two production environments.
The sharding project had us actively working (multiple changes per day) on multiple services running in 12 environments (2 staging, 10 production). The cost of every manual step was amplified. Pulling up the right dashboards for an environment used to cost a few minutes a week, but could now be hours. Waiting 3 hours between deploys and looking at graphs to notice anomalies? Totally untenable.
Higher Coordination Costs
The original process was to merge changes, and then release them ... at some point later. It was common to merge something and then come back the next day to release it. These changes might require some manual operations before they were safe to release, but we were able to manage that by dropping a message to the team, "Hey, please don't deploy until I've had a chance to run the database migrations." As we brought more people on to the team and increased activity, however, this became a major pain point. Changes would pile up behind others, and no one knew if it was safe to release all of them together.
We also introduced a set of shared packages to support the development of our new microservices. This introduced a new problem: one set of changes could impact many services. If you're working on one service, and introduce some changes to a shared library to support what you want to do—you'll deploy the one service and move on. We would regularly accumulate weeks worth of undeployed changes on services, which were probably unrelated but represented a major risk.
We needed to shift to a model where changes were always being released to all of our services.
How We Did It
To build our new release system, we made use of existing Heroku primitives. Every service is part of a Pipeline. The simplest services might only be deployed to staging and production environments, but our sharded services have up to 10 environments, modeled as Heroku apps running the same code but in different regions.
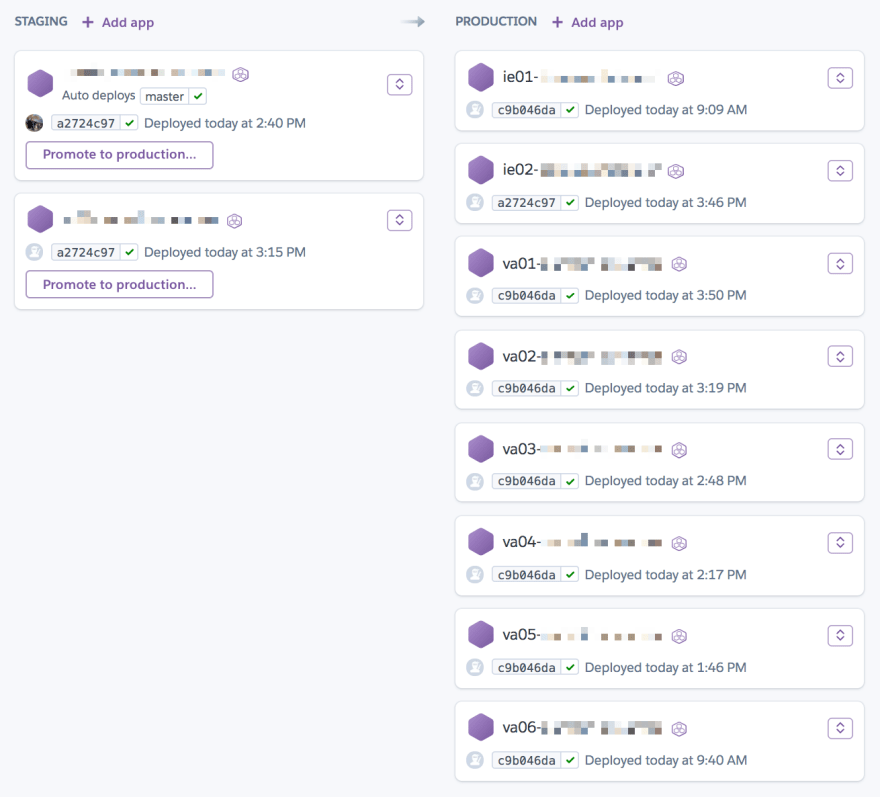
The pipelines are configured to automatically deploy to the first app in staging when a change is merged into master and CI has passed. That means that for any service, changes are running in staging within a few minutes of merging. Note that this is not something custom we built—this is a feature available to any Heroku Pipelines user.
This is where we would previously begin checking dashboards and watching ops channels before manually executing a pipeline promotion from the staging app to the next app in the pipeline.
Automation To The Rescue
We built a tool called cedar-service-deployer to manage the rest of the automated pipeline promotions. It’s written in Go and uses the Heroku client package to integrate with the API.
The deployer periodically scans the pipelines it manages for differences between stages. If it detects a difference, it runs a series of checks to see if it should promote the changes.
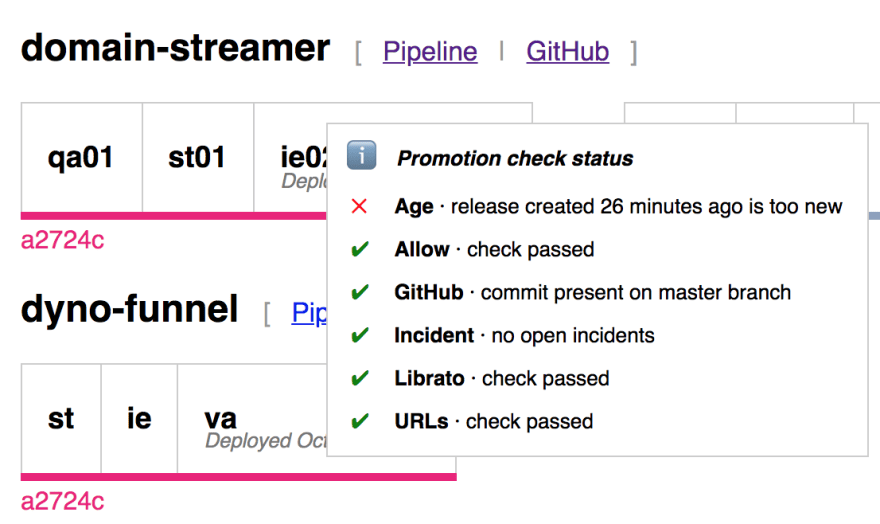
The suite of checks for every service are:
- Age. The age gate will only open after 30 minutes, to allow time for integration tests to run and any potential alerts to go off.
- Allow. Fails if promotions are paused globally (e.g., during Dreamforce or other large customer-facing events) or for a particular service.
- GitHub. The deployer will only promote changes which are present on the master branch.
- Incident. This check fails if there’s a relevant incident open on the Heroku status site.
- Librato. Each service is configured with a list of Librato alerts to monitor, and promotion is paused as long as any are actively firing.
- URLs. This is a generic check, which passes as long as the configured URLs return an HTTP 200 OK status code. We use this in particular to check the status of our platform integration tests.
If any checks fail, it does nothing and waits for the next tick to check again. Once all the checks pass, it executes a pipeline promotion to push the changes to the next stage and then repeats.
The deployer itself is stateless; every time it runs it checks the state with the Heroku API. It also doesn’t have a strict concept of a “release.” Instead it’s always trying to reconcile differences between stages in the pipeline. That means there can be concurrent releases rolling out over time, for example here, where the 813a04 commit has been rolled out from qa01 through to va05 while at the same time 4cc067 is one stage away from completing its rollout.

Key Learnings
There are a few things in particular that made the project successful:
- Start small. We tested out the first version of the deployer on a service that was still in development and not yet in production. We were able to learn how it changed our process and build confidence before it was critical.
- Make onboarding easy. Adding a new service to the deployer only requires configuring a pipeline and a list of alerts to monitor. Once the smaller-scale experiments showed success, people started moving services over on their own because it took less time to configure automated deploys than to perform a single manual one.
- Build on existing ideas and tools. Our automated deployments are not fundamentally different from the manual deployments we previously performed. Engineers didn’t need to learn anything new to understand it—or to take over and manage some changes themselves.
We also learned a few unexpected things along the way!
- Isolate early pipeline stages. You might have noticed that staging had two apps, “qa01” and “st01”. We originally only had a single staging environment. But staging is a shared resource at Heroku! Every stage in the pipeline builds more confidence in the release, and we found we needed an environment that only impacted our own team, and not any other teams at Heroku.
- Engineers apply a lot context that computers need to be taught. Over time, we’ve added additional promotion checks that were obvious to engineers but not so obvious to our deployer! Would you deploy a service while there was an open incident? Probably not, but our deployer did! Now it checks the Heroku status site for open incidents to limit changes to the system while we’re responding. We also allow engineers to test changes in staging before they are merged. Would you immediately promote those changes to production? Probably not, but our deployer did (oops). It now checks that changes exist in master, so we don’t roll out changes that aren’t ready.
- Master should be deployable != must be deployable. We used to have the policy that “master should always be deployable”, but there’s a big difference between should and must. With an automated, continuous deployment system there’s no room for the occasional manual operation synchronized with release. We reach much more frequently today for internal feature flags to separate the deployment of changes from enabling the feature. We also had to change how we handle database migrations, separating out changes that add a migration from code that depends on it.
- Confidence from coverage. It used to be common to “babysit” a deploy and execute a manual test plan as it rolled out. Today we depend entirely on our alarms and platform integration tests to signal that changes are safe to roll out or if a deploy needs to be halted. That makes it more important than ever to ask about each changeset, "How will we know if this breaks?"
Conclusion
It’s been about 2 years since we turned on automated deployments for our first service. It now manages 23 services. Instead of hours of checking dashboards and coordination to roll out changes, Runtime engineers now just hit “merge” and assume their changes will be released globally as long as everything is healthy.


















