
As a freelance cloud architect, I spend my time reviewing and playing with the latest and greatest industry trends. Technologies like Kubernetes, ElasticSearch, and Prometheus fill my home and business infrastructure. After many hours of painful configuration and tweaking, they are now tuned to work exactly the way I want.
I often want to re-sell this configuration to my clients in an effort to implement the cost savings of using technologies I’m comfortable with and on infrastructure I hold near and dear, in whatever cloud I have spun up for the day. This is usually a mix of my home-lab of on-premise servers as well as AWS EC2 instances. To this end, I often recommend similar configurations and setups for my projects. This then vendor-locks my clients into my own services, or they have to learn how to operate the infrastructure themselves if they want to break away at some point in the future.
This last premise is one that I find myself looking at more and more as I visit communities of people who want to host web servers with some business logic, data APIs for game analytics, or even hosting their favorite Discord bots for fun. How would I market such an extravagant custom architecture to folks that shouldn’t be invested into such an intense solution? Is the upfront hosting cost going to pay dividends in the future? What about when the tides of change come through and a new technology stack paves the way?
The simple answer is I don’t, and I shouldn’t. It’s not always the best solution to build a full infrastructure from the ground up. Sometimes a middle-tier Platform-as-a-Service (PaaS) is the right direction for these budding technologist products and growing applications.
So I spent the day building a simple application using my own tools, and then ported it over to Heroku to test their levers, functionality, and learning curve. In this article, we will explore that simple application and compare it to my own technology stack to determine if it is a suitable alternative for my customers.
The Application (Kubernetes)
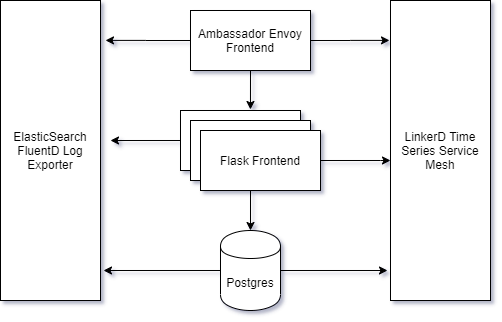
As initially noted, I will be using my infrastructure that I already have in place. This design is a scenario many architects would be familiar with and is the general go-to for applications I build with my clients. It comes complete with my chosen log collectors (fluentD and ElasticSearch), metrics observability (LinkerD), and ingress controllers (Ambassador) as a fabric for the application stack.
For the application configuration see: https://github.com/Tokugero/kubernetes-hello-world
Building the configs was as easy as taking my already-built yaml templates and updating them to fit this new app.
Ambassador TLS.yaml - Generate a LetsEncrypt certificate
Ambassador Mapping.yaml - Generate the ingress reverse proxy
LinkerD namespace.yaml - Annotations to inject the service mesh
On to the application!
In order to give the most direct comparison, I wanted to require a database that I knew Heroku supported, so I chose Postgres. Setting up my own Postgres DB on Kubernetes was as simple as a helm chart with a few tweaks to its default values to fit my infrastructure. Once this was up, I loaded a test data set to have something to interact with.
The app was built using Flask and psycopg2 with its only purpose being to show data about what server it lived on and random rows in the Postgres database with some basic logging. It was built in a container and pushed to a locally provisioned docker registry housed in my cluster.
The effort of deploying this application to my cluster was relatively simple:
kubectl apply -f namespace.yaml
kubectl apply -f Mapping.yaml
kubectl apply -f TLS.yaml
helm install myapp -n myapp stable/postgresql --values=postgres/values.yaml
kubectl exec <follow instructions to access new psql instance to input the test data>
kubectl create secret generic psqlpass -n myapp --from-literal=PSQL_PASSWORD=”mydbpassword”
kubectl apply -f Deployment.yaml
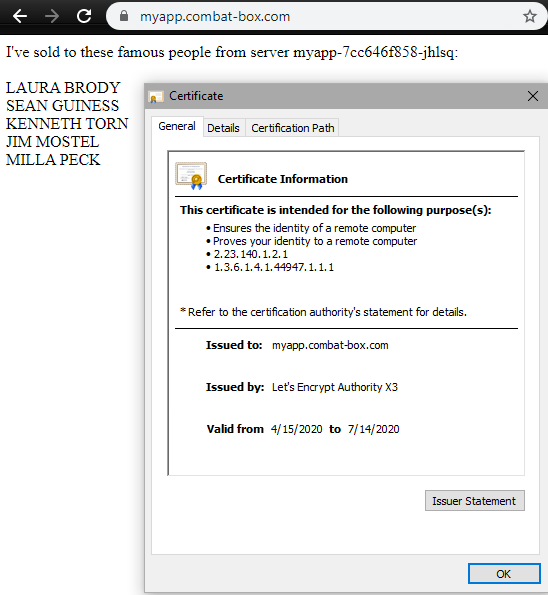
In this image we see the grand result: an HTTPS encrypted web application showing some data from a backend.
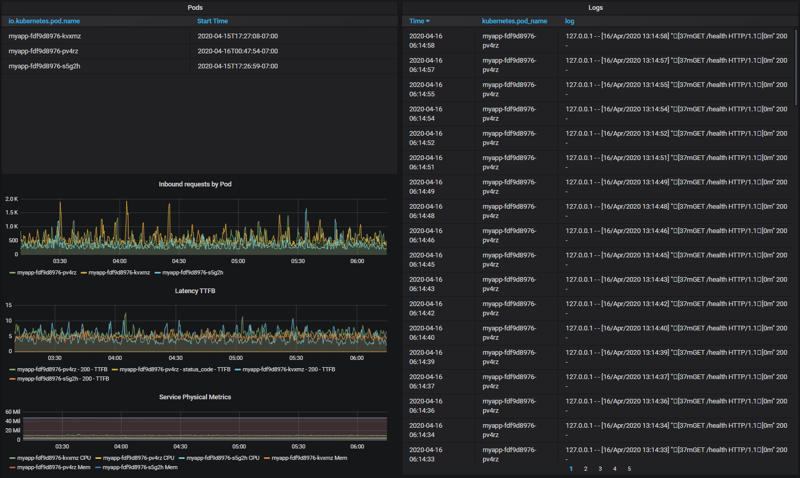
Here we can see the observability stack with Grafana exposing the ElasticSearch logs and the Prometheus metrics from LinkerD. In the configurations, the only prerequisite from the application owner is to annotate the namespace appropriately.
Now, I have access to the following general operations commands:
Scale: kubectl scale deployment -n myapp myapp --replicas=<n>
Deploy: kubectl set image -n myapp deployment/myapp myapp=<new container image>
The price tag to build and deploy this is $0. I have this running on my own hardware, and all the software used is open source. So the only real cost is my time and energy to manage and maintain the infrastructure. I also run a similar configuration in AWS that costs about $250/month for my cluster with three EC2 instances, a managed ElasticSearch cluster, and standard GP2 block-storage (SSDs).
The Application (Heroku)
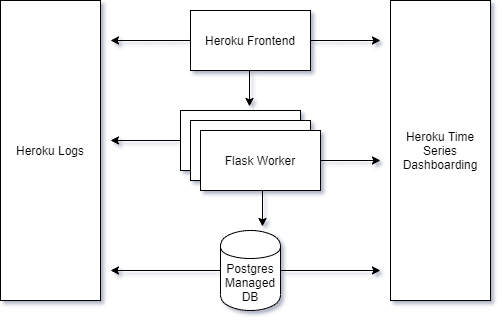
I took this same application and followed Heroku’s intuitive UI to build the infrastructure for my application.
Provisioning the PostgresDB was very easy. Simply navigating to the data app in the Heroku UI and selecting “Postgres” took me to a view that eventually showed my fully provisioned, free, DB with a few "free-tier" limitations to data and storage capacity. This came with a preconfigured DB name, user account, and auto-generated password with a host in AWS just for my DB. I can substitute my custom details for these provisioned ones via environment variables just like I could with Kubernetes.
Deploying the app involved a bit more work. I needed to install the Heroku CLI to follow their Docker deployment methodology as well as a Postgres client to add data to the newly provisioned DB. This came down to using information that was output in the Postgres plugin details in my dashboard:
heroku pg:psql postgresql-defined-xxxxx --app philip-myapp
<add test data>
heroku container:login
<provide login details to heroku>
heroku container:push web -a philip-myapp
heroku container:release web -a philip-myapp
After updating my environment variables, I was off to the races! Kind of. I still didn’t have metrics, and my app still wasn’t loading in the philip-myapp.herokuapp.com domain that was provisioned on my behalf.
Navigating through the log viewer I found that the container was repeatedly crashing. It became clear to me that there wasn't a port mapping to define that 443 should go to my container’s 5000, and the app tried to repair itself by restarting when the Heroku health checks failed to reach my application. Some research led me to Heroku’s randomly provisioned port that is passed to the environment variable “$PORT”. I made a quick tweak to my Dockerfile and myapp.py to load this dynamically-assigned port, and my application finally started working. It even came with a provisioned DigiCert wildcard certificate.
My running Heroku application:
After making another small tweak to my configurations, I received a custom domain with my very own LetsEncrypt certificate:
But this still isn’t quite feature parity. Where’s the observability and scaling?
After poking around the configs, I found the problem: Metrics are only available to the “Hobby” tier dynos and above, which is $7/month. Scaling is only available to the “Pro” tier dynos and above at $25/month/dyno. Billing is prorated to the time used, however, so switching these settings was easy enough to get a feel for these features. The metrics were collected from the inception of the container which meant that I didn't lose any data before I switched to the “Hobby” dyno.
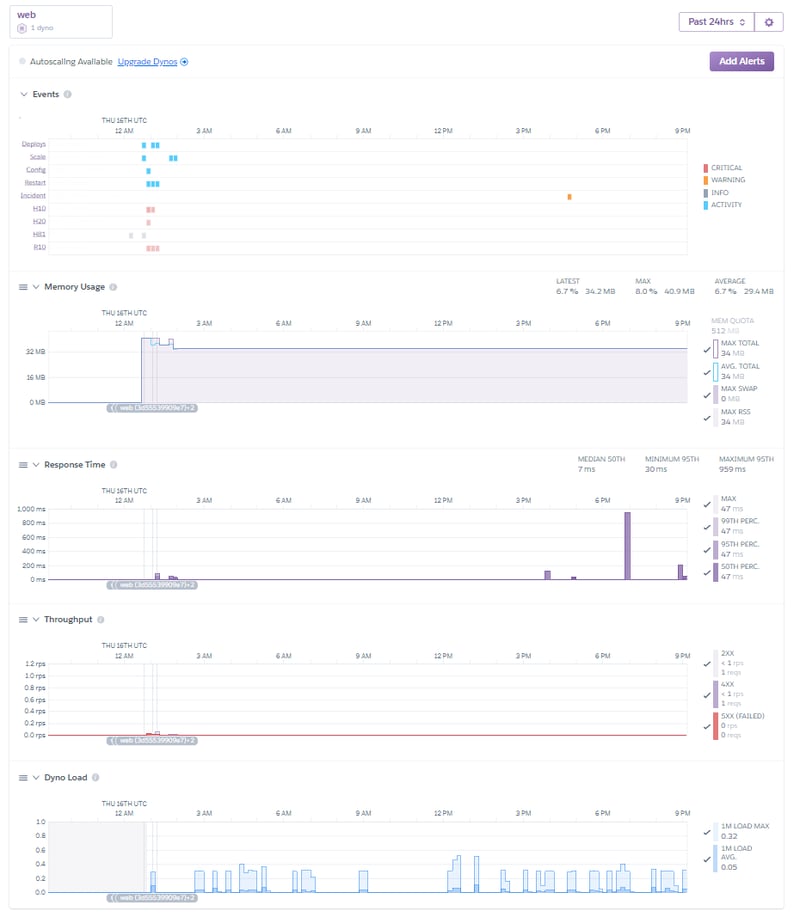
With this done, these are my new functions to manage my application:
To deploy, re-run the previous commands near the Dockerfile:
heroku container:push web -a philip-myapp
heroku container:release web -a philip-myapp
To scale, simply upgrade to the “Pro” tier dyno and adjust the slider or use the CLI:

heroku scale web=2 -a philip-myapp
Scaling dynos... done, now running web at 2:Standard-1X
And with only some mandatory scaffolding with the database naming conventions and port mapping functionality, I had an application with the same features that I enjoyed on my own Kubernetes clusters. The cost comparison between these two is vastly cheaper in Heroku’s favor when compared to my AWS cluster. However, it was clear that it would eventually become uneconomical if this application needed to grow to an enterprise-grade application. I believe that by the time it is necessary to maintain a scale of that size, however, it would also be time to optimize in other ways that may require a custom platform solution anyway.
Conclusion
Heroku surprised me in its capabilities and initial cost models. While it is an opinionated PaaS, its assertions on infrastructure are simple to understand and easy to collaborate with, while providing the same underlying functionality that makes me love the software-defined infrastructure of Kubernetes. My favorite part was Heroku’s use of industry standards like Docker and Git to manage their pipelines and deployments which made moving my application to their platform nearly an effortless exercise. It is features like these that help me trust them with my customer’s experience until a self-managed platform becomes necessary.


















