In the data pipeline, we often talk about ETL, aka Extract-Transform-Load, which is actually a very simple process as follows.
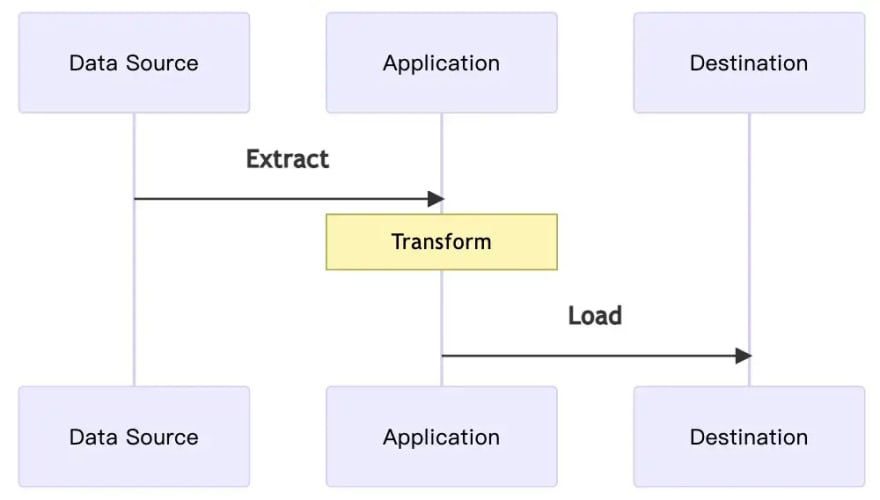
Given an application extracts data from a source and saves it to another data storage after some processing and conversion, this is what ETL does. This is a complete ETL process, and to be honest, most non-ETL applications are doing something like that.
Let me use a simple Python example to demonstrate the implementation of ETL.
# Open the CSV file containing the data
with open("orders.csv", "r") as file:
# Use the CSV module to read the data
reader = csv.DictReader(file)
# Iterate over the rows in the CSV file
for row in reader:
# Extract the data from the row
order_id = row["order_id"]
customer_name = row["customer_name"]
order_date = row["order_date"]
order_total = row["order_total"]
# Insert the data into the database
cursor = db.cursor()
cursor.execute(
"INSERT INTO orders (order_id, customer_name, order_date, order_total) VALUES (%s, %s, %s, %s)",
(order_id, customer_name, order_date, order_total)
)
db.commit()
This is a simple ETL example, we extract each line from a CSV file (data source), and convert the order details from CSV format to the corresponding columns in the database, and finally write to the database.
As the database evolves, this process also evolves, and the ETL also has a variation, ELT, which seems to be a sequential exchange of T and L. But behind the scenes, the database has actually become more powerful.
Let's continue with the above example, and see how would ELT be handled?
with open("orders.csv", "r") as file:
# Use the LOAD DATA INFILE statement to load the data into the database
cursor = db.cursor()
cursor.execute(
"LOAD DATA INFILE 'orders.csv' INTO TABLE orders FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 ROWS"
)
db.commit()
In this example, we use MySQL's LOAD DATA command to write a CSV file directly into the database, converting it during the writing process, rather than converting the format first and then writing it to the database.
In the data pipeline, it is actually various combinations of ETL and ELT, and eventually we will produce a data structure to fit the analysis and utilization.
This process is the same concept in the big data domain, except that the data pipeline of big data multiplies a much larger volume of data and needs to face a more diverse data storage.
From ETL to EL plus T
In my previous articles, we have already discussed the implementation of many big data pipeline architectures.
- https://medium.com/better-programming/evolutionary-data-infrastructure-4ddce2ec8a7e
- https://medium.com/better-programming/real-time-data-infra-stack-73c597ed05ee
For the data source part, we rely heavily on Debezium to capture data changes (CDC).
The process underlying Debezium is that a group of workers extracts the binlogs of various databases, restores the binlogs to the original data, and identifies the contents of the schema to be passed on to the next data storage.
In other words, each data source must have a group of Debezium workers to be responsible for it.

When the number of data sources is large, it is a huge effort just to build and maintain the corresponding Debezium. After all, the software does not work properly when left alone, but also requires a complete monitoring and alerting mechanism, which will eventually create a huge operation overhead.
In fact, E and L in ETL are the most worthless things in a pipeline. For a pipeline to be effective, the most important thing is to produce effective data based on business logic, and T should be the part we should be focusing on.
However, we have to take a lot of time on E and L in the operation of the pipeline, which is not what we expect.
So, is there a solution to this dilemma?
Yes, absolutely, Airbyte, and there are many similar solutions, but Airbyte is open source and relatively easy to use.
Let's take MongoDB to Kafka as an example, as soon as the setup is done it will be like the example below.
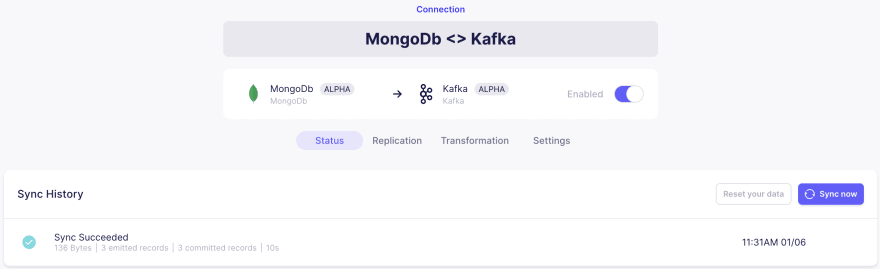
Airbyte can sync automatically or manually according to the settings, and it can choose incremental sync or full sync. Each sync record is listed, and the sync process can be seen after expanding logs.
As a result, the creation of data pipelines is effectively simplified, and data storage can be integrated smoothly through Airbyte's Web UI.
Conclusion
This article is not to promote Airbyte, nor is it to introduce the Airbyte architecture in depth, but from the standpoint of an architect, we will find that in the domain of big data, we will face various challenges, and each challenge has a corresponding solution, but also requires high learning costs.
In fact, Airbyte also has its limitations, for example, the synchronization period must specify a regular time interval, such as every hour, even though it can use cron representation, but still limited by the fixed time, can not do the real streaming, i.e., once the data is triggered.
In addition, when relying on additional tools, it can be frustrating to encounter this problem.
Once the problem occurs, where to start to troubleshoot, and how to clarify the scope of the disaster, all need to experience and in-depth learning before there is a way to deal with.
Learning these tools is also the biggest challenge for data engineers and data architects, there are many tools to solve many problems. However, big data is really big, and learning all tools is almost impossible.
Finally, let me conclude with a picture.

What's the next?


















