Temporal coupling is the most overlooked pitfall.
Last time, we explained that temporal coupling can be effectively solved through event-driven architecture. Among them, we discussed the three approaches separately. Starting with the lowest reliability, simply using the event emitter can solve most of the cases with the least effort; secondly, in order to further improve the reliability, a message queue can be introduced to ensure that the event will be executed at least once. Finally, implement event sourcing to ensure that events are not lost at all.
Nevertheless, in organizations with some resource constraints, message queues are seem to be out of reach. The resources here include human resources and organizational budget, whether there is no extra manpower to maintain a new messaging service or no extra funds to start a messaging service. Message queuing is one of the high price systems in restricted organizations.
Therefore, in this article I will introduce how to achieve decoupling through event-driven architecture with minimal resources.
System Overview
Why this topic is born? Because one of our products belongs to this restricted organization. Therefore, in the process of system evolution, we gradually improve the reliability by making lots of technical selections.
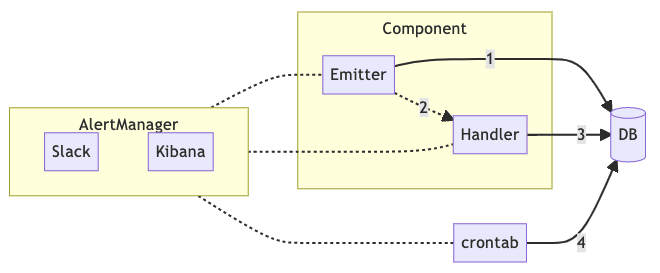
The overall architecture above is the final look of our system. We can see from the picture, there is no message queue. Even so, we still achieve high reliability. At least, if something goes wrong, there is a way to recover.
The components, alert manager, crontab and DB are all existing in the system, and no additional components are added. We just split the unit originally executed by a function into an emitter and a handler.
In the next section, I'll explain how we did it step by step.
System Evolution
The entire system evolution process has gone through four stages, and we have gradually improved the reliability of the entire system.
- Best effort: In the beginning, we simply split the function into emitter and handler, that's all. This is the most basic practice, all events are fire-and-forget. Of course, there is no accident occurred, such an implementation is actually not bad. Decoupling can be done with minimal resources. But as mentioned in the previous article, there are two main problems, event loss and emit loss.
- Integrate with Alert Manager: Then we add an alert when the handler fails to execute. By writing the necessary information into
Elastic Searchand presenting it onKibana, the person in charge can take corresponding actions after receiving an alert from slack. That is to say, we resolve event loss through manual recovery.

- Event sourcing: In order to track events more completely to avoid event loss and emit loss, we use the existing database to implement a simplified version of event sourcing. Before emitting the event, the emitter writes a metadata into the database and marks the expected handler. If the writing to the database fails, it is regarded as an event emission failure, and the alert manager will be triggered. The handler also updates itself into the database when it completes the event. For the example mentioned above, the metadata of the event looks like this:
{
eventName: "purchased",
createAt: "2022/01/01 1:11:11",
expected: ["giveCoupon", "lottery"],
status: 0, // 0: emitted, 1: timeout, 2: processed
done: [],
args: ["user A", 5000]
}

- Apply crontab plus event idempotency: At this moment, it is the same as the previous complete architecture diagram. All the above steps have a fatal flaw, and it needs to be manually recovered by humans. Although this can make sure that the problem can be solved eventually, the mean time to recovery (MTTR) will be pretty long. Therefore, the entire recovery mechanism can be further enhanced, through the workflow event pattern introduced in my previous article. Periodically check which events are not executed correctly through a crontab, and then rerun it.
There are two important points worth noting. First, the processing of each event must be idempotent, which is very important even when using message queues. Because message queues provide the guarantee of at-least-once, not exactly-once. Second, even with idempotency, there should be an upper bound on retries. If the retry fails several times, we still have to notify the person in charge to deal with follow-up matters.
Trade-off
In fact, the above architecture has a lot to discuss. For example,
- Know which handlers are expected when the emitter writes to the database. In other words, the emitter is somehow coupled to the handler. However, in my opinion, such coupling is acceptable. As long as the coupling can be reduced through appropriate coding, for instance, there is a global mapping table to have the relationship between each event and handlers, so this can be regarded as a configuration rather than a coupling.
- Retry in the handler instead of crontab. Each has its own advantages. Retrying in the handler can recover the error as soon as possible, but sometimes the main reason for the failure of the handler is database congestion, and retrying immediately will further increase the load on the database.
- The data are inconsistent. The handler executes successfully but the update fails. Using idempotency to ensure that even repeated execution will not cause problems. On the other hand, the task of the emitter is executed successfully but fails to write to the database, which has to be re-emitted manually. This can be done with a more complex mechanism to implement automatic retries, but at the cost of more complexity, I don't feel it's worth it for the corner case where the write fails.
Conclusion
In this article, we discuss some of the trade-offs some restricted organizations face with event-driven architecture. It has to be said that event-driven architecture itself is a highly complex architecture, and whether it is really suitable in small organizations has always been a matter of debate. However, this article provides a simple way to implement event-driven architecture on a small system. In addition to not creating new components, it does not generate too much coding complexity, and it is an easy-to-practice implementation.
Still, it's not easy to find the right approach for each organization in this long list of technical selections. Behind every straightforward answer, there are many considerations and possible risks. When I'm designing a system, especially a distributed system, I always remind myself to be careful with FLP Theorem.
No completely asynchronous consensus protocol can tolerate even a single unannounced process death
In plain English, it is Murphy's law.
Anything that can go wrong will go wrong.
How to be as reliable as possible with limited resources, whether in terms of time, manpower, and cost, is the most interesting part of system design.


















