A while ago, I mentioned that I'm in a budget-constrained organization, so we can't afford to use a true message queue. Instead, we have chosen to use a second-best approach to meet our immediate needs and a simple solution to implement, using Redis.
Nevertheless, there are still many different ways to implement Redis as a message broker. At that time, we chose the option which was the fastest to get up and running with the least implementation effort: lists. However, as the system evolved and new feature requests were made, the original solution no longer worked.
The advantages of the list are
- easy to implement
- support for consumer groups
- the ability to decouple producers and consumers
The disadvantages are also obvious.
- At-most-once guarantee
Now, we need at-least-once guarantee, and lists don't cover this need. The Redis Stream mentioned in the previous article was not adopted because of the large implementation effort. So we started looking for a new alternative.
Bull.js
After some comparisons, we finally chose Bull.js.
The reasons are as follows.
- support at-least-once guarantee.
- it has a lower implementation effort and provides many monitoring tools, e.g., Bull Exporter.
- full-featured, including retry, time delay, etc.
- even support rate limit.
However, in the working process, I have to say that the official document is not detailed enough and it took us some time to try it successfully. In this article I will show the two most important issues we encountered and explain the solutions.
Redis Cluster
Bull is supported for Redis clusters. Unfortunately, the description is scattered in several places in the document.
First, the description from the constructor's document needs to provide the parameter createClient, and the rule is
(type: 'client' | 'subscriber' | 'bclient', config?: Redis.RedisOptions): Redis.Redis | Redis.Cluster;
Redis.Redis and Redis.Cluster at the end of the rule actually refer to the ioredis constructors, so to set them up, we must use the ioredis constructors.
const Redis = require("ioredis");
Redis.Redis
Redis.Cluster
Even so, I don't understand what kind of format createClient needs to provide, is it an object? What are the keys to Redis.Redis and Redis.Cluster?
Finally, I found out from another section of the document, Reusing Redis Connections I realized that it was a function. Anyway, put the pieces together.
const Redis = require('ioredis');
let client;
let subscriber;
const opts = {
// redisOpts here will contain at least a property of connectionName which will identify the queue based on its name
createClient: function (type, redisOpts) {
switch (type) {
case 'client':
if (!client) {
client = new Redis.Cluster(REDIS_URL, redisOpts);
}
return client;
case 'subscriber':
if (!subscriber) {
subscriber = new Redis.Cluster(REDIS_URL, redisOpts);
}
return subscriber;
case 'bclient':
return new Redis.Cluster(REDIS_URL, redisOpts);
default:
throw new Error('Unexpected connection type: ', type);
}
},
prefix: '{myprefix}'
}
const queueFoo = new Queue('foobar', opts);
In this way, Redis clusters can be used as brokers.
Memory Leakage
Once we got over the cluster issue, we pulled Bull online and started testing. Then we ran into a serious problem where the underlying Redis started leaking memory.

As you can see from the figure, Redis memory usage has been skyrocketing since it was enabled.
So we took a closer look at the document to find out what we missed, and finally found a hint in the tutorial.
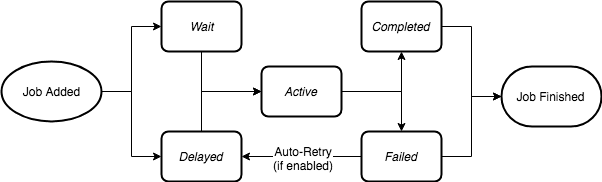
A job begins as Job Added and ends up as Job Finished, regardless of whether it succeeds or fails. In other words, as soon as the job enters Redis, it stays there, regardless of whether it succeeds or fails. How do we solve this?
Specify the parameters removeOnComplete and removeOnFail in add to ensure jobs do not stay in the last finish state. I believe that removeOnComplete can definitely be set, but removeOnFail depends on the needs of each user, e.g., whether they want a failure count, whether they want a manual recovery from failure, etc. In our case, we don't need to keep the job even if it fails, so both parameters are true.
What about the jobs left online? Bull also provides a way to clean jobs.
//cleans all jobs that completed over 5 seconds ago.
await queue.clean(5000);
//clean all jobs that failed over 10 seconds ago.
await queue.clean(10000, 'failed');
After running online, you will see an extremely significant drop in usage.

The first half remains horizontal because we have already added removeOnComplete and removeOnFail, so no more increases are made. The vertical line in the middle is the process of clean.
It is worth mentioned that the clean process locks the entire message queue, so it may affect the online functions and is not recommended to perform it under production environment. The duration of the lock depends on the number of jobs to be cleaned.
Conclusion
I always talked about the evolution of systems. As you should have noticed from my previous articles, in a limited organization, we do not always have enough manpower, budget or even knowledge to build the perfect system, or to be more precise, no system is perfect.
Every time we design a system, we choose the relatively acceptable solution among many factors, which means we have to face the potential problems. For me, I always take the most achievable implementation, but with the understanding that such choices are not static and retain the flexibility to meet future requirements.
For many people, the replacement of the message queue is a very huge exercise. But for my organization, it's a simple implementation by a few people, and then it's done. The reason why I always mention domain-driven design and decoupling is to make it easier to do system evolution when needed.
Bull currently meets all of our needs, is reliable enough, and even offers a monitoring solution. I believe we will probably be able to stop worrying about message queues for a long time.


















