
Original Sin of Microservices, Part 1
This series of articles are a summary of Worldwide Software Architecture Summit'22, thus most of contents are coming from the seminar. Of course, there are also some insights from my understanding.
Microservice architecture had been a popular topic for several years, and there were various sessions to talk about how to deploy, management and implement microservices at every seminar about software architecture. However, such a trend in the last six months to a year of time sharply frozen, more and more people noticed that although microservices is a good approach, but not a total solution.
It comes some benefits by using microservices, but it also comes at a cost, such as complexity.
What's the ideal microservice?
Before talking about the original sin of microservices, let's define what the ideal microservice would look like.
Ideally,
- Non-shared code
- Non-shared data
- With bounded context in a specific domain
- Deployment separately
- Single responsibility principle
It may look like as follows in an architecture diagram.

When clients communicate with backend services, backend usually routes the request to the corresponding microservice through a API gateway. And, this microservice is able to process this request correctly by its own data and response to the clients.
What's the real world?
But the real world is often not as rosy as we think.

Do you know what kind of animal this is?
As far as I know, there are at least three possibilities, which could be a horse, a donkey or a mule.
Why is it painted like this?
At first we designed the whole architecture according to our ideal or textbook style and started to implement it, and everything looked so perfect. But as time went on, more and more requirements were added and we were forced to make it work in a limited time frame, even if there were mistakes to be fixed. In the end, the horse-like animal became more and more sketchy.
If there was a good design and planning, we can at least tell from the back half that it might have been a horse. On the other hand, if there was no design at all, no one would probably know what you were trying to draw.
If we represent it into an architecture diagram, it would probably look something like this. Welcome to the real world.
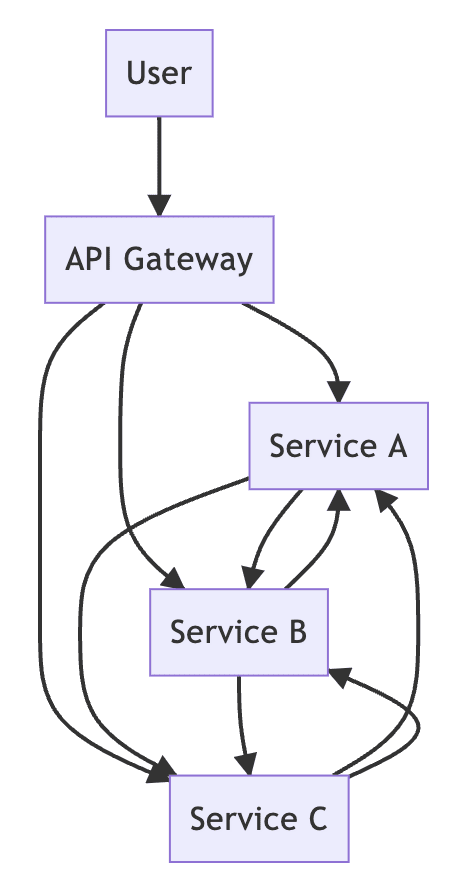
A, B and C all have their own responsibility to handle their own bounded context, but as the requirement grows, A finds that it needs B's data, and B needs C's cooperation, and even C has to call A. Finally, it becomes a big ball of mud.
There are several reasons.
- Usually, there are no architects. So there is no way to evolve the system correctly with each requirement.
- Even because there was no architect, architecture is not clearly defined.
- Focus on fast delivery of features, and ignore non-functional requirements.
- Feedback cycle is very short, and we must respond to requests or incidents within a short period of time.
- It's all online and real-time without any downtime until the requirements are eliminated.
8 fallacies of distributed computing
After understanding why systems in reality are the way they are, let's look at 8 fallacies of distributed computing. These are the most commonly overlooked pitfalls of microservice architecture.
The network is reliable
People wishfully assume that the network between two endpoints is reliable. But the truth is that packets may drop and connections may be broken. Therefore, there should be a retry mechanism between the two endpoints to improve the reliability as much as possible.
Latency is zero
There is an unconscious belief that the latency between two endpoints is zero, and this leads to many simple functions being spread out to other endpoints. Unfortunately, the latency between any endpoints is never zero, even on an intranet. So when making remote calls, it is always important to consider setting a timeout, even for connections to internal databases.
In addition, when frequent operations are required on redis, mechanisms such as redis pipeline are always used to reduce the round trip time (RTT) between endpoints.
Bandwidth is infinite
People usually feel that the network bandwidth between two endpoints is unlimited, so there is no restraint when transferring data. In fact, the bandwidth is much smaller than you think.
In particular, if you use MySQL's select * often, you may run out of bandwidth without realizing it. As a MySQL table grows with requirements, there may be many more costs you don't realize, such as BLOB or TEXT, and such data structures often store huge amounts of data to further consume bandwidth.
The network is secure
This is a very common pitfall, people always believe that the intranet is secure. But this is absolutely unrealistic, and this is why the concept of zero trust has been proposed in recent years.
Topology doesn't change
This fallacy is a bit interesting. People feel that the topology of a network does not change, meaning that the two endpoints are always written to each other's location, whether it is FQDN or IP, but in reality, network topology changes for many reasons, such as VPC segmentation, public cloud migration, and even system evolution.
There is one administrator
You would expect that there would be at least one administrator maintaining each service, right? Usually, in every organization, there is an operation role that is responsible for maintaining the system. Therefore, operation plays the role of an administrator, and if there is a problem with the system, operation is definitely the first to know.
Wrong, absolutely wrong.
Any system must implement its own observability, and system developers must have the ability to identify potential problems from these observabilities. There are four most common types of observability.
- Logging: The logs left by system execution are usually related to system behavior.
- Tracing: The execution cycle of a task. If it is a distributed system, you must be able to track the telemetries on each system, e.g., jaeger or open-tracking.
- Metrics: The measurable status left by the system run, such as the number of API executions, the number of failures, etc.
- Profiling: Resource consumption behind the system like CPU and memory, etc.
Transport cost is zero
This is absolutely the most serious fallacy. You have to understand that any remote call has a cost, especially on a public cloud, which is even more pricey. Even if it's a database access or an outbound HTTP call, these all cost money.
So, no matter what the remote call is, it must always be optimized, both in terms of frequency and data size.
The network is homogeneous
This is an easy pitfall to overlook. The network is absolutely heterogeneous, so when one endpoint calls another endpoint in series, you cannot guarantee that the order of arrival is the same as the order you sent it. In other words, any assumptions about order should not exist.
Conclusion
Alright, after this discussion, I believe we can all agree that distributed systems are really complex. There are so many factors that must be considered for just two endpoints, not to mention microservices.
Microservices are composed of countless endpoints, and each endpoint has to consider just those factors, and at the same time, microservice architectures have their own issues to face, such as data consistency, system scalability, and so on.
Since this article is already a bit overloaded, I will schedule the challenges of microservices for the next article. In that time, we will discuss how difficult it is to design a microservice correctly, and we will also recognize why the recent seminars are emphasizing the shortcomings of microservices.


















