
Originally published at Squadcast.com.
The relentless push in organizations can have unintended consequences, particularly for your On-Call engineers. One threat that can quickly erode their effectiveness is alert noise.
When your On-Call engineers are bombarded by constant alerts (– genuine emergencies, false positives or redundant notifications) it creates a state of information overload, forcing them to constantly switch context and struggle to identify the critical issues amidst the din.
The result?
Decreased performance, burnout, and ultimately, compromised system reliability.
Alert noise reduction isn't just about creating a calm work environment for your On-Call members (although that's important too!). It's a strategic imperative for maintaining optimal system uptime, ensuring rapid response to critical incidents, and fostering a culture of innovation where your engineers can focus on what truly matters – driving the business forward.
Understanding Alert Noise
 For the hundredth time now, “What is alert noise?”
For the hundredth time now, “What is alert noise?”
Alert noise – it's the bane of every On-Call engineer's existence. But what exactly is it? In technical terms, alert noise refers to the excessive volume of irrelevant or low-priority alerts. These alerts typically fall into three main categories, each contributing to information overload and hindering efficient incident management:
- False Positives: These alerts trigger due to harmless fluctuations in system behavior, environmental factors mimicking actual issues (like scheduled backups causing temporary spikes in resource utilization), or misconfigured thresholds set too low for normal system variations. Imagine your CPU utilization monitor blaring an alert every time a scheduled backup kicks in, unnecessarily diverting attention from potential problems.
- Redundant Alerts: Multiple alerts surface for the same incident, often from different monitoring tools or components. This creates unnecessary noise and makes it difficult to pinpoint the root cause quickly. For instance, an application failure might trigger alerts for both high database latency and application errors, essentially reporting the same issue twice. These could also be flapping or transient alerts.
- Overly Sensitive Triggers: Thresholds set too low trigger alerts for minor deviations that don't require immediate attention. This not only bombards engineers with noise but also desensitizes them to genuine emergencies. Imagine receiving alerts for a 1% increase in memory usage when historical data suggests such fluctuations are normal system behavior. Over time, engineers may start ignoring these alerts, potentially missing critical issues that fall within the same threshold range.
What Happens Next After Alert Noise?
The consequences of unaddressed alert noise are far-reaching and can have a detrimental impact on your team and operations:
- Decreased Productivity and Increased Stress: Constant context switching between irrelevant alerts leads to fatigue and hinders engineers' ability to focus on critical issues. When your On-Call engineer is in the middle of diagnosing a complex application issue they wouldn’t want non-critical incident notifications. It disrupts their thought process and increases stress, ultimately hindering their ability to resolve the true problem at hand.
- Delayed Response Times to Critical Incidents: The sheer volume of noise can drown out genuine emergencies, leading to delayed detection and resolution of critical incidents that can cause costly downtime. Every minute counts when it comes to system outages, and alert noise can cost you precious time in responding effectively. Read more: How to Calculate & Reduce Mean Time to Resolution (MTTR)
- Increased Error Rates: Fatigue and information overload can lead to analysis paralysis and mistakes during Incident Response. Exhausted engineers may struggle to differentiate between critical and non-critical alerts, potentially leading to misdiagnosis or overlooking important details that could magnify the incident.
Top 5 Strategies to Address Alert Noise Effectively
We have already established that minimizing alert noise is crucial for maintaining optimal system health and On-Call efficiency. By implementing effective strategies such as:
- Fine-Tuning Alert Thresholds
- Alert De-duplication and Grouping
- Alert Ownership and Accountability
- Leveraging Advanced Monitoring Tools
- Investing in Right Tools
By taking a proactive approach to alert noise management, you can empower your on-call engineers to focus on what truly matters – ensuring system stability and rapid response to critical incidents, ultimately contributing to the success of your high-growth organization. A well-rested and focused on-call team equipped with the right tools and strategies is essential for navigating the ever-changing landscape of high-growth environments.
1. Tuning Alert Thresholds
The foundation of effective alerting lies in setting appropriate thresholds. Your thresholds are like tripwires – if you set them too low, and even minor fluctuations trigger unnecessary alerts. Conversely if you set them too high, critical issues might fly under the radar.
So, how to find the sweet spot? Here’s how:
- Historical Data Analysis: Utilize historical data from your monitoring tools to understand your system's typical behavior. Analyze metrics like CPU utilization, memory usage, and response times to identify normal ranges.
- Statistical Methods: Leverage statistical techniques like standard deviation to establish thresholds that capture deviations outside the expected range. This helps differentiate between normal fluctuations and potential anomalies.
- Dynamic Thresholds: Consider implementing dynamic thresholds that adjust automatically based on historical trends and seasonal variations. This ensures your alerts remain relevant as your system scales and evolves.
2. Alert De-duplication and Grouping
Alert deduplication eliminates redundant notifications for the same issue, while grouping presents related alerts together. This simplifies analysis and helps engineers quickly identify the root cause.
- Deduplication: with this you can eliminate redundant alerts for the same incident. Modern Incident Management and monitoring tools can identify identical alerts triggered by different components and present them as a single notification, reducing noise and simplifying analysis.
- Grouping: Group related alerts that point to the same underlying issue. For example, a spike in database latency followed by application errors might indicate a database server overload. Groupingthese alerts clarifies theroot cause and allows engineers to focus on resolving the core problem.
Read more: RCAs Within Incident Management Tools
3. Alert Suppression
Sometimes, planned maintenance activities can trigger alerts. Suppressing low-priority alerts during these windows can be beneficial:
- Maintenance Windows: Configure your monitoring system to temporarily suppress specific alerts during pre-scheduled maintenance windows. This ensures engineers aren't bombarded with irrelevant notifications while performing upgrades or service deployments.
- Cautious Approach: Use alert suppression judiciously. Over-reliance on suppression can lead to missing critical issues that may arise unexpectedly during maintenance. Always ensure clear communication and documentation regarding suppressed alerts to avoid confusion.
Read more: Suppressing Alert Noise during Scheduled Maintenance
4. Invest in the Right On-Call Tools
Modern Incident Management and monitoring tools offer powerful features to combat alert noise:
- Anomaly Detection: Leverage machine learning algorithms to identify unusual patterns in system behavior. These algorithms can differentiate between normal variations and potential incidents, reducing false positives and irrelevant alerts.
- Machine Learning: Utilize machine learning to analyzehistorical data and learn from past incidents. This allows tools to predict potential issues and trigger pre-emptive alerts before they escalate into critical events, improving overall system resilience.
- Centralized Platform: Consolidate alerts from various monitoring tools into a centralized platform. This provides a holistic view of system health and eliminates the need to switch between different interfaces, improving efficiency and reducing the risk of missing critical notifications.
5. Alert Ownership and Accountability:
Empowering engineers to understand and manage alerts associated with their code or services fosters a culture of proactive noise reduction:
- Code-Level Alerting: Configure alerts to be triggered by specific events within application code. This allows engineers to pinpoint the source of issues and fine-tune alerts to highlight anomalies within their own area of responsibility.
- Alert Ownership: Assign ownership of specific alerts to engineers responsible for the relevant code or service. This accountability encourages engineers to investigate and address the root causes of alerts associated with their work, ultimately reducing noise for the entire team.
By implementing these strategies and leveraging the right Incident Response tools, you can significantly reduce alert noise and ensure a healthy, responsive IT environment that fuels the success of your high-growth organization.
Key Features for On-Call Platforms
Here are essential features in an On-Call platform to effectively reduce alert noise:
 ## How To Use Squadcast For Alert Noise Reduction?
## How To Use Squadcast For Alert Noise Reduction?
As a Unified Incident Management and Reliability Automation Platform, reducing alert noise comes out as one of the major advantages of Squadcast. Let’s check our how you can use Squadcast’s features for reducing alert noise for optimum On-Call performance:
- Alert Routing & Filtering
- Deduplication & Dedupe Keys
- Intelligent Alert Grouping
- Auto Pause Transient Alerts
- Global Event Rulesets
- Alert Suppression
- Merge Incidents
1. Alert Routing & Filtering
Alert Routing & Filtering in Squadcast is a two-sided approach that tackles alert noise by streamlining where notifications go and what gets sent in the first place. Here's how you can use it for optimal On-Call performance reducing alert noise.
Alert Suppression in Squadcast lets you define rules to silence notifications for low-priority or non-actionable alerts. These alerts are then categorized as "suppressed" and won't trigger any notifications. This helps filter out background noise and keeps the focus on critical incidents.
 Withsmart tagging and routing, Squadcast allows you to set uptagging rules based on various criteria in the incident details (priority, severity, type). These tags are then automatically applied, allowing for smarter routing of notifications.
Withsmart tagging and routing, Squadcast allows you to set uptagging rules based on various criteria in the incident details (priority, severity, type). These tags are then automatically applied, allowing for smarter routing of notifications.
You can also use routing rules based on tags. With tags in place, you can define routing rules that ensure alerts reach the most relevant team members. This ensures the right people are notified for the right issues, reducing wasted time and improving response efficiency.
In essence, Alert Routing & Filtering work together to reduce unnecessary notifications.
2. Group Alerts Intelligently
Squadcast further intelligently groups related alerts, allowing engineers to see the bigger picture and identify the root cause of an incident quickly.Intelligent Alert Grouping (IAG) leverages machine learning to automatically group similar alerts from the same service into a single, unified incident.
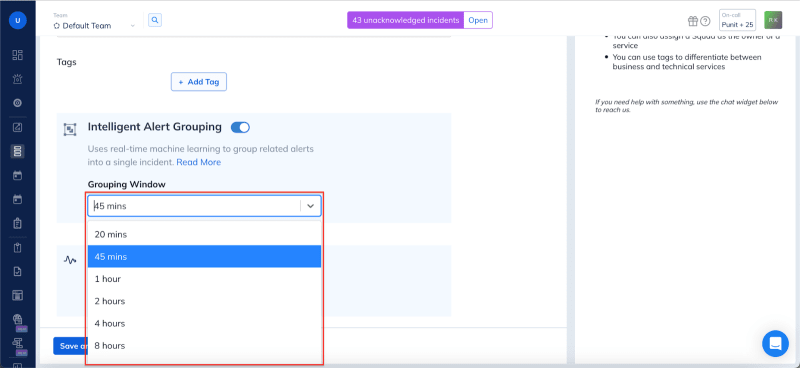
Source: Intelligent Alert Grouping (IAG)
3. Auto Pause Flapping Alerts
Squadcast's Auto Pause Transient Alerts (APTA) feature also combats alert fatigue by intelligently pausing notifications for short-lived issues that typically resolve themselves. This works by analyzing historical data to identify recurring patterns of transient alerts. When a similar alert triggers, APTA can temporarily pause notifications, allowing the issue a chance to self-resolve. If the issue persists, APTA resumes notifications, ensuring you're alerted for genuine problems requiring attention.
 ### 4. Alert Deduplication & Dedupe Keys
### 4. Alert Deduplication & Dedupe Keys
Alert deduplication helps by grouping similar alerts together, instead of sending out individual notifications for each one. This can be especially useful for situations like:
- Repeated warnings: If your system generates hourly alerts for disk usage reaching 50% until it hits 70%, deduplication can silence all but the first notification.
- Related incidents: When multiple alerts point to the same underlying issue, deduplication combines them into a single incident for easier troubleshooting.
 You can configure deduplication rules based on specific criteria within the alert data, ensuring you only combine relevant alerts. What’s amazing is that deduplication doesn't hide important information. You can still access all the details of the individual alerts within the grouped incident.
You can configure deduplication rules based on specific criteria within the alert data, ensuring you only combine relevant alerts. What’s amazing is that deduplication doesn't hide important information. You can still access all the details of the individual alerts within the grouped incident.
5. Global Event Rulesets
Global Event Rulesets in Squadcast act like a central command center for your alerts. Instead of setting up individual notifications for every service, you create rules in this global hub.
 These rules determine where alerts from any source should be routed, reducing redundancy and streamlining the entire notification process. This translates to less time managing alerts andfaster response times to critical issues.
These rules determine where alerts from any source should be routed, reducing redundancy and streamlining the entire notification process. This translates to less time managing alerts andfaster response times to critical issues.
Apart from all this, you can consider delaying non-critical notifications to business hours, allowing teams to prioritize during peak times. For this you can leverage Squadcast’s Delayed Notifications. This feature allows you to define business hours for your services.

Delayed Notifications Squadcast
During non-business hours, Squadcast will hold off on sending individual notifications for incidents. Instead, it compiles a digest of all pending incidents and delivers it in a single notification at the start of the next business day. This notification can be sent via push notification and email to designated users, squads, or escalation policies.
Conclusion
Alert overload is a common enemy of efficient On-Call operations. To begin your fight against it, understand what types of alerts (low-priority, transient) contribute most to the noise. By taking this initial step, you'll be able to get a clearer picture of how you want to leverage further smart intelligent automation to get rid of alert noise always and forever.


















