Based on Theory of Computation (CS3102), Spring 2017, videos are here.
Definitions
Let’s start with refinement of terminology from part 1.
Alphabet (Σ - sigma) is a finite, non-empty set of symbols letters. Example: Σ = {a, b}.
String (w) is a finite sequence of symbols letters chosen from Σ. Example: ababba.
Language (L) a (possibly infinite) set of strings. Example: L = {a, aa, aaa}.
String length is a number of letters in it: |aba| = 3.
String concatenation : w₁w₂. Example: ab•ba = abba.
Empty string : ε (epsilon). |ε| = 0, ∀w w•e = e•w = w (∀ - for all).
Language concatenation : L₁L₂ = {w₁w₂ | w₁∈L₁, w₂∈L₂} - Cartesian product of two sets (∈ - in). Example: {1,2}•{a,b,...} = {1a,2a,1b,2b,...}
String exponentiation : wᵏ = ww...w (k times). Example: a³=aaa
Language exponentiation : Lᵏ = LL...L (k times). LL = L², Lᵏ = LLᵏ⁻ⁱ, L⁰ = {e}. Example: {0,1}³² - all binary words of length of 32.
String reversal : wᴿ. Example: (aabc)ᴿ=cbaa.
Language reversal : Lᴿ = {wᴿ | w∈L}. Example: {ab, cd}ᴿ = {ba, dc}.
Language union : L₁⋃L₂ = {w | w∈L₁ or w∈L₂} - set union. Example: {a}⋃{b,aa} = {a,b,aa}.
Language intersection : L₁∩L₂ = {w | w∈L₁ and w∈L₂} - set intersection. Example: {a,b}∩{b,c} = {b}.
Language difference : L₁ - L₂ = {w | w∈L₁ and w∉L₂} - set difference (∉ not in). Example: {a,b} - {b,d} = {a}.
Kleene closure : L* = L⁰⋃Lⁱ⋃L²…, L+ = Lⁱ⋃L²⋃L³…. Example {a}* = {ε,a,aa,aaa…}, {a}+ = {a,aa,aaa…}
All finite strings (over Σ): Σ*, L⊆Σ* ∀L. Note : Robins doesn’t provide a rule for alphabet exponentiation, so here is how I interpret this: If ℒ is a language which contains all strings of length 1 over alpahbet Σ (ℒ=Σ) then L⊆ℒ* ∀L.
“Trivial” language : {ε}. {ε}•L = L•{ε} = L.
Empty language : Ø. Ø* = {ε}.
Theorem: Σ* contains only finite string (but posibliy infinite number of strings).
Theorem: (L*)* = L*
Theorem: L+ = LL*.
The extended Chomsky Hierarchy
Originally Chomsky proposed 4-types of grammar classes. Since then hierarchy was refined with the more granular division.

I can now understand some notations on this diagram aⁿbⁿcⁿ (a string which contains equal size sequences of a, b, c), wwᴿ (palindrome), aⁿbⁿ, a* (Kleene star), {a, b} finite set.
But what about P, NP, LBA, etc? Those notations come from 3 different branches:
-
Computability theory: What problems are solvable for computers?
- Decidable vs undecidable (Turing degrees)
-
Complexity theory: What makes some problems easy or hard for computers?
-
P,NP,PSPACE,EXPTIME,EXPSPACE
-
-
Automata theory: What formal model of computation is required for a problem?
-
LBA(linear bounded automaton),DPA(deterministic pushdown automaton) etc.
-
Automata theory
Notes based on Automata Theory course from Stanford.
Automatons are abstract models of machines that perform computations on an input by moving through a series of states or configurations. At each state of the computation, a transition function determines the next configuration on the basis of a finite portion of the present configuration. As a result, once the computation reaches an accepting configuration, it accepts that input. The most general and powerful automata is the Turing machine.
The behavior of these discrete systems is determined by the way that the system is constructed from storage and combinational elements. Characteristics of such machines include:
-
Inputs : assumed to be sequences of
symbolsletters selected from a finite set of input signals (stringw∈Σ*). -
Outputs : sequences of
symbolsletters selected from a finite set Z. - States : finite set Q, whose definition depends on the type of automaton.
There are four major families of automaton :
- Finite-state machine (FSM) or finite automata (automaton)
- deterministic finite automata (DFA) and non-deterministic FA (NFA)
- Pushdown automata (PDA)
- Deterministic PDA or non-deterministic PDA (NPDA, NPA)
- Linear-bounded automata (LBA)
- Turing machine (TM)
Finite-state machine
FSM is a “machine” that changes states while processing symbols, one at a time. FSM is a 5-tuple M=(Q, Σ, δ, q₀, F) (M for a machine)
- Finite set of states:
Q = {q₀, q₁, q₂, ..., qₓ} - Transition function:
δ: Q×Σ → Q - Initial state:
q₀∈Q - Final states:
F⊆Q(is a subset ofQ)
Acceptance : end up in a final state (F).
Rejection : anything else (including hang-up/crash)
For example: automata that accepts abababab…= (ab)*.
M=({q₀,q₁}, {a,b}, {((q₀,a),q₁), ((q₁,b),q₀)}, q₀, {q₀})
As a graph:

× is a Cartesian product, → is a mapping (function or more generally relationship). As a result of the Cartesian product of two sets, we get a set of tuples. We can think of tuples as 2-d coordinates, so we can plot the function as 3-d scatter plot or as a table:
| a | b | |
|---|---|---|
| →q₀ | q₁ | |
| q₁ | q₀ |
For example, state changes for accepting string abab:

But sometimes it is drawn like this (this is confusing IMO):

This machine will “crash” on input string “abba”. To fix this we can add more edges (make machine total):
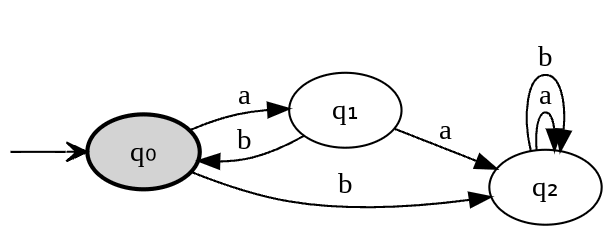
We can have unconnected nodes (q₃ is final state, but it’s unreachable from start state q₀):
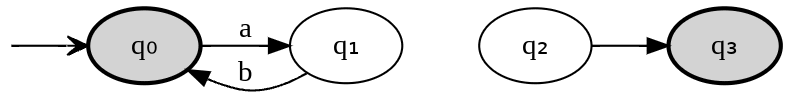
If we extend transition function to strings (from symbols) δ: Q×Σ* → Q we can represent machine compactly.
δ(q₀,ww₁) = δ(δ(q₀,w),w₁), where δ(qₓ,ε) = qₓ.
Example 1: δ(q₀,ab) = δ(δ(q₀,a),b)
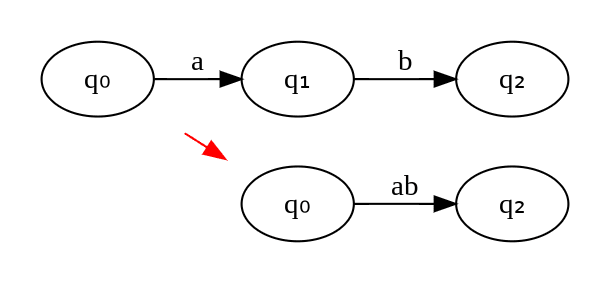
Example 2:

Note: {a,b} = PCRE /^[ab]$/
Language of M is L(M) = {w∈Σ* | δ(q₀,w)∈F}
Language is regular iff (if and only if) it is accepted by some FSM.
Note : this is one more way to formally specify language, the first one was with grammar (L(G))
Non-detemenistics FSM
Non-determinism: generalizes determinism, where many “next moves” are allowed at each step. New definition of transition function:
δ: 2Q×Σ → 2Q
Computation becomes a “tree”. Acceptance : any path from the root (start state) to some leaf (a final state).
Example
A machine that accepts regular language in which each word has b as the second symbol before the end. L = {ba, bb, aba, abb, bba, bbb ...}.
As regular expression: {a,b}*b{a,b}. AS PCRE (Perl Compatible Regular Expressions): /^[ab]*b[ab]$/. As a graph:
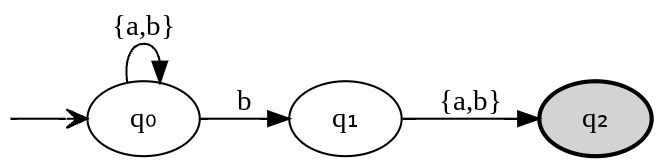
As a table:
| a | b | |
|---|---|---|
| →q₀ | q₀ | q₀, q₁ |
| q₁ | q₂ | q₂ |
| q₂ |
Note that we have two possible states in the top right cell. This is a nondeterministic choice - with the same input machine can be in two different states.
The machine reads symbols of the string from left to right.
Let’s see state transitions for string “bb”.
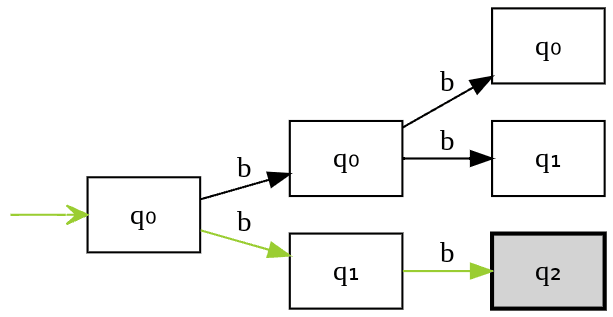
Let’s see state transitions for string “bbb”.
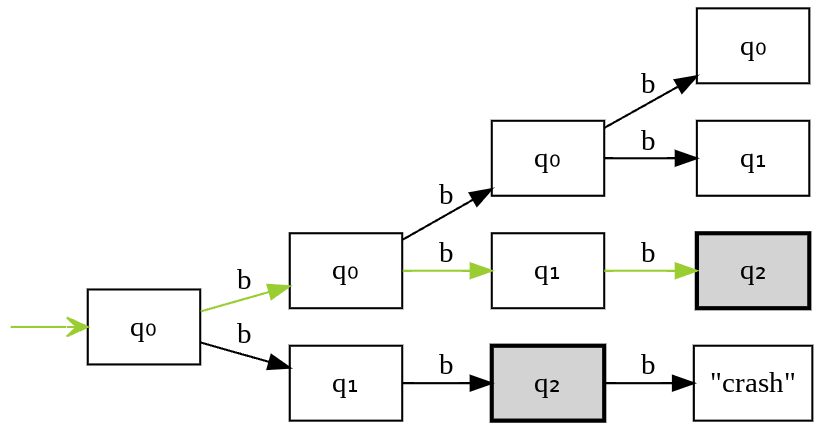
Theorem : Non-determinism in FAs doesn’t increase power.
Proof by simulation:
- Construct all super-states, one per each state subset.
- New super-transition function jumps among super-states, simulating the old transition function
- Initial super state is those containing the old initial state.
- Final super states are those containing old final states.
- Resulting DFA accepts the same language as the original NFA but can have exponentially more states.
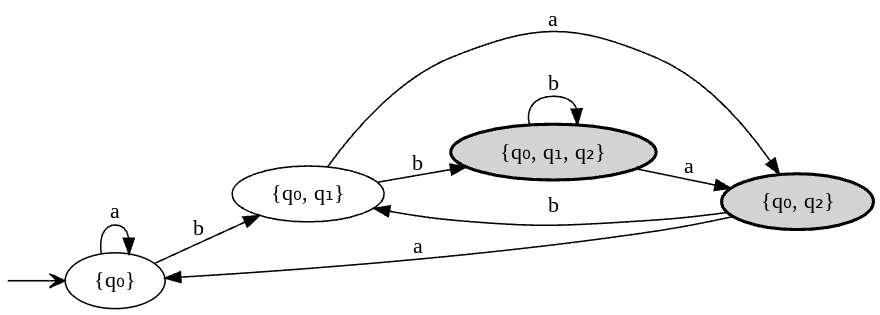
Let’s convert previously defined NFA to DFA. We take the initial transition table and convert the first row to sets:
| a | b | |
|---|---|---|
| →{q₀} | {q₀} | {q₀, q₁} |
Now we have one new state {q₀, q₁} let’s construnct transitions for it:
| a | b | |
|---|---|---|
| {q₀, q₁} | {q₀,q₂} | {q₀, q₁, q₂} |
Continue:
| a | b | |
|---|---|---|
| {q₀, q₂} | {q₀} | {q₀, q₁} |
| {q₀, q₁, q₂} | {q₀, q₂} | {q₀, q₁, q₂} |
Let’s draw a graph:
Let’s see state transitions for string “bb”:

Let’s see state transitions for string “bbb”:

Read more about conversion of NFA to DFA here.
As we can see NFAs and DFAs have the same computational power, but NFAs are more compact and “clearly communicate intention”.
Regular Expressions
Regular expressions are used to denote regular languages. They can represent regular languages and operations on them compactly. The set of regular expressions over an alphabet Σ is defined recursively as below. Any element of that set is a regular expression.
1Regexp = Ø (* empty language *)
2 | {ε} (* trivial language *)
3 | {x} (* singleton language *)
4 | Regexp + Regexp (* union *)
5 | Regexp Regexp (* concatenation *)
6 | Regexp* (* Kleene closure *)

Union R + S:

Note : Language union {a} ∪ {b} = {a,b} ~ RE union a + b ~ PCRE /^[ab]$/ or /^(a|b)$/.
Concatenation RS:

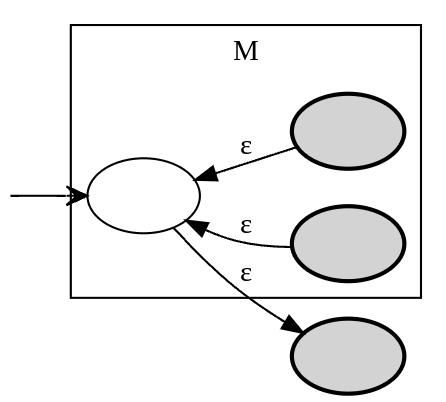
Kleene closure R*:
Theorem : Any regular expression is accepted by some FA.
A FA for a regular expression can be built by composition.
Note here suppose to be an example but I’m lazy to draw it. See original lecture slide on page 28.
FA Minimization
Merging nodes


Merging edges

Theorem [Hopcroft 1971]: the number N of states in a FA can be minimized within time O(N log N). Based on earlier work [Huffman 1954] & [Moore 1956].
Conjecture : Minimizing the number of states in a nondeterministic FA can not be done in polynomial time. (Is this because non-deterministic FA corresponds to deterministic FA with an exponential number of nodes?)
Theorem : Minimizing the number of states in a pushdown automaton (or TM) is undecidable.
Theorem : Any FA accepts a language denoted by some RE. Proof : use “generalized finite automata” where a transition can be a regular expression (not just a symbol), and: Only 1 super start state and 1 (separate) super final state. Each state has transitions to all other states (including itself), except the super start state, with no incoming transitions, and the super final state, which has no outgoing transitions.
Now reduce the size of the GFA by one stateat each step. A transformation step is as follows:
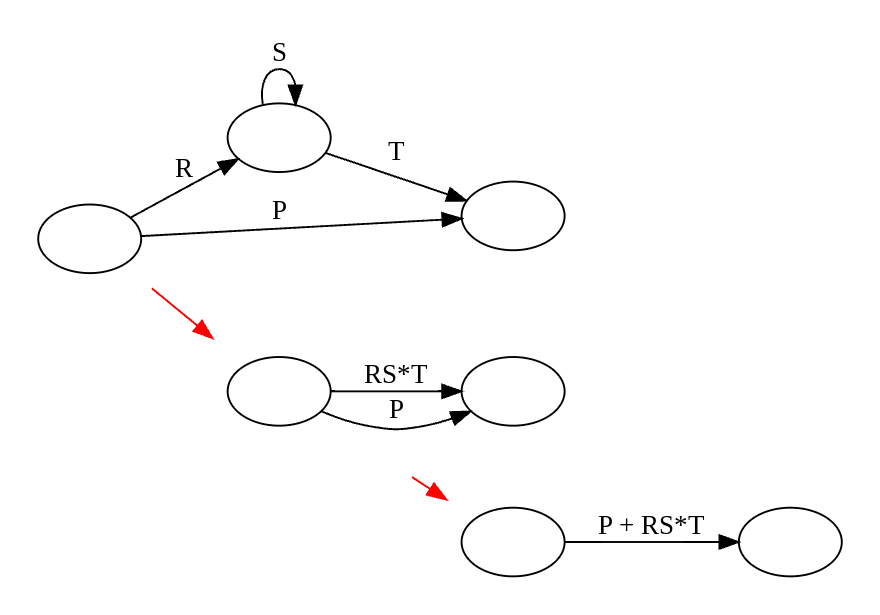
Such a transformation step is always possible, until the GFA has only two states, the super-start, and super-final states:
The label of the last remaining transition is the regular expression corresponding to the language of the original FA
Corollary : FAs and REs denote the same class of languages.
To be continued
Lectures from Robins are quite good…
I didn’t cover:
- ε-transitions in NFAs
- transformation and minimisation of FSMs
- Regular Expressions Identities
- Decidable Finite Automata Problems
See also:
- Automata theory. An algorithmic approach, Javier Esparza
-
A taxonomy of finite automata construction algorithms, Bruce W. Watson
- Thompson’s construction
- Berry-Sethi construction
- The McNaughton-Yamada-Glushkov construction. See: Introducing Glush: a robust, human-readable, top-down parser compiler
- The Aho-Sethi-Ullman DFA construction
- The Myhill-Nerode construction
- Brzozowski construction. Related: parsing with derivatives
- DeRemer construction


















