Welcome to #160 of the AWS open source newsletter, where we try and share all the important open source news, projects, events, and content that open source builders want. This week we have new projects that include tools to help you build data workflows, Terraform modules to help you incorporate temporary elevated access controls, integrating Tailscale to change your traffic flows, a neat AWS Lambda debugging tool, Go bindings for Cedar, and more.
We also feature content this week on lots of great open source technologies, including Apache Spark, Cedar, Keycloak, Apache Cassandra, Ray, Apache Airflow, deequ, Babelfish for Aurora PostgreSQL, MySQL, PyTorch, ROS, Kotlin, AWS SDK for pandas, Apache Kafka, Notation, and more! Finally, don't miss the videos and events sections, and make sure you check out events happening this week including the open source data meetup in London where I will be speaking.
Feedback
Please please please take 1 minute to complete this short survey and bask in the warmth of having helped improve how we support open source.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Suman Debnath, Justin Garrison, Aidan Steele, Nathan Glover, Lars Jacobsson, John Mille, Abdel Jaidi, Anton Kukushkin, Leon Luttenberger, Jimmy Ray, Jesse Butler, Stuti Deshpande, Jesus Max Hernandez, Divya Gaitonde, Joseph Barlan, Aniket Jiddigoudar, Parnab Basak, Fernando Gamero, Shubham Mehta, Michael Raney, Meet Bhagdev, Lotfi Mouhib, Vara Bonthu, Praveen Koorse, and Mike Hicks, Jeremy Cowan and Shane Corbett
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
aws-ddk
aws-ddk (DataOps Development Kit) is an open source development framework to help you build data workflows and modern data architecture on AWS. From the README:
The DDK offers high-level abstractions of AWS CDK constructs, allowing you to quickly build pipelines that manage data flows on AWS. You can create your pipelines using Typescript or Python. We want our customers to focus on writing code that adds business value, whether that is a data transformation, cleaning data to train a model, or creating a report. We believe that orchestrating pipelines, creating infrastructure, and creating the DevOps behind that infrastructure is undifferentiated heavy lifting and should be done as easily as possible using a robust framework.
terraform-aws-sso-elevator
terraform-aws-sso-elevator is a Terraform module for implementing temporary elevated access via AWS IAM Identity Center (Successor to AWS Single Sign-On) and Slack. From the README:
While temporary credentials through SSO/IAM Identity Center is a significant improvement compared to static IAM users, there is still a risk of IDP credentials compromise. It makes creating permanently assigned permission sets a tricky task - balancing between allowing enough and mitigating the risk of credentials compromise. To address this, we've created this Terraform module - AWS SSO Elevator. It allows requesting and granting temporary elevated access for AWS SSO through a Slack request/approval workflow to reduce security risks. And it is now open-sourced. Despite its recent debut in the open-source space, it's been used and proven valuable by our customers.
Check out the rest of the README for additional details and features this provides, and you can also check out the demo. This is certainly on my todo list to try out.
And here is a link to the Terraform registry.
freedata
freedata when it comes to pushing creativity boundaries in what you can do with AWS, few people reach AWS Hero Aidan Steele's level. Freedata alters the traffic patterns from your webapp-hosting EC2 instances via AWS Systems Manager Session Manager and Tailscale. Session Manager streams are limited to about 10mbit. Not to be taken seriously, but fun nevertheless.
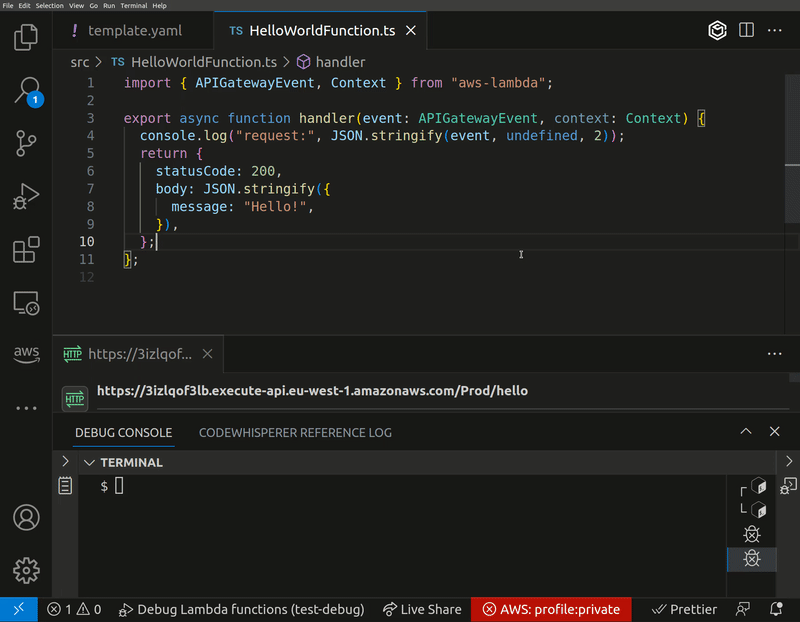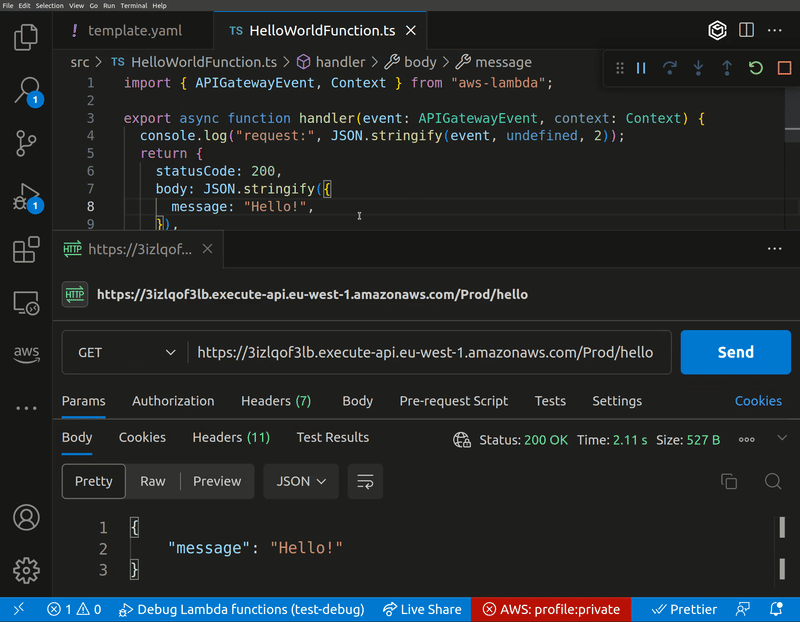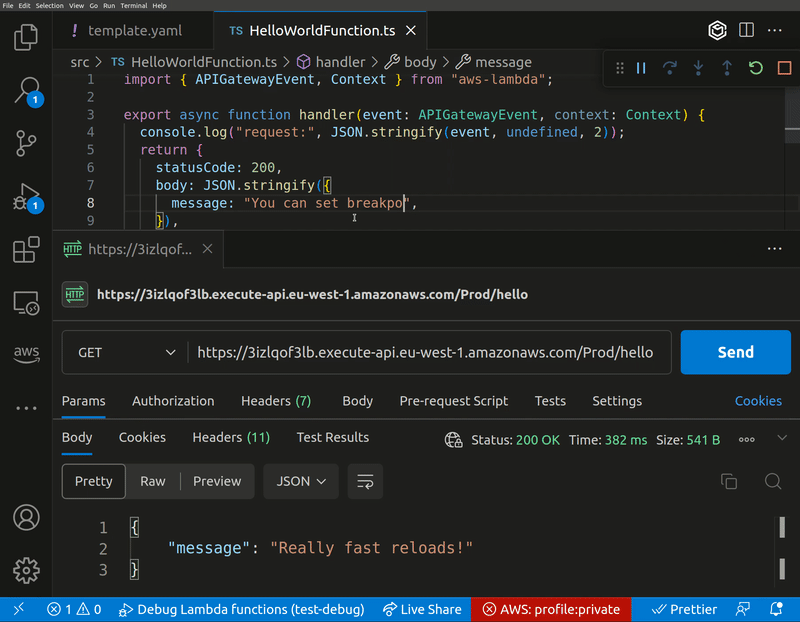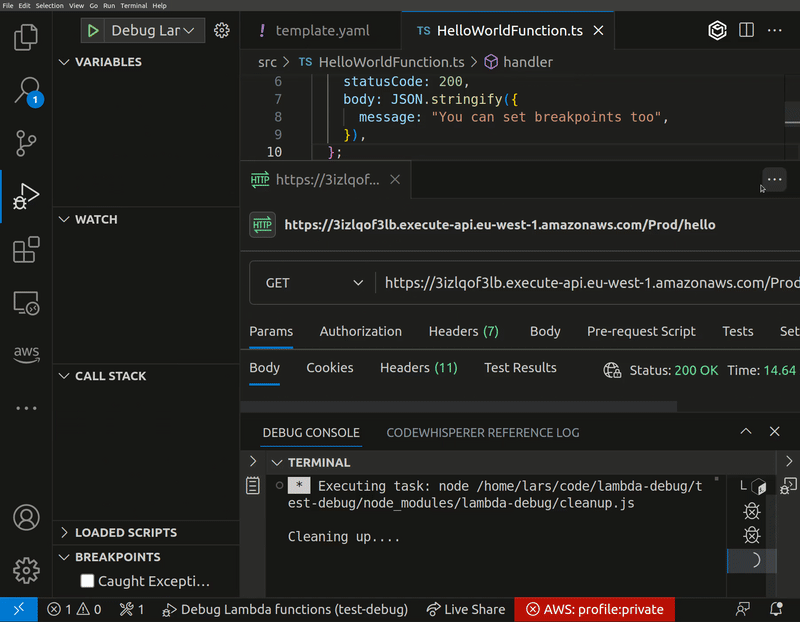
lambda-debug
lambda-debug is the latest update from our good friend and AWS Community Builder Lars Jacobsson. Lambda-Debug is a tool that enables you to invoke AWS Lambda functions in the cloud from any event source and intercept the requests with breakpoints locally. There's similar functionality in SST which this is inspired by, but is designed to work with AWS SAM and CloudFormation and, in a later version, CDK. As always, documentation and examples of how you can get started are bar raising.
aws-greengrass-json-gzip
aws-greengrass-json-gzip is an AWS Greengrass component from Nathan Glover that takes a stream of JSON messages from StreamManager and batches them into a gzip file. It uses a JSON Line (JSONL) format for the messages. This is a prototype component, and Nathan is experimenting how to approach batching high-frequency data direct to S3 pre-partitioned - without relying on Cloud services like Kinesis or Firehose.

cedar-go
cedar-go is a project from Mathis Joffre that provides a Go binding for Amazon Cedar Policy using wasm to embed the Cedar engine with near zero overhead. The repo provides an example of how to use the Cedar engine to evaluate a policy inside your Go code. Very cool.
Demos, Samples, Solutions and Workshops
game-streaming-on-kubernetes
game-streaming-on-kubernetes this repo from Justin Garrison is an example of how to set up a Kubernetes cluster and an example workload to stream a game from Kubernetes using Sunshine. Sunshine is an open source implementation of NVIDIA GameStream and Moonlight is an open source client for playing games. This repo heavily builds on the work from Games on Whales (GOW). They provided the main containers and an example implementation of a Kubernetes deployment. The workload in this example folder has been changed but will be upstreamed at some point.
pycon_polars101
pycon_polars101 is a workshop that my colleague Suman Debnath recently delivered at PyCon. In this workshop you will start with Polars basics and compare Polars with Pandas DataFrame. You will walk through code exploring functions and features of Polars, for example load and transform data from CSV, Excel, or Parquet, perform data analysis in parallel and prepare your data for machine learning pipelines and shall compare with Pandas and Spark. The workshop will focus on the following, which makes Polars special: parallel hashing, lazy execution, and expresive API
AWS and Community blog posts
Keycloak
As part of getting familiar with AWS Identity Centre and looking to integrate an identity provider other than Active Directory (and the other usual suspects) I decided to deploy Keycloak. Keycloak is a very feature rich, open source alternative for those folks who want to run their own identity and access management service. I thought this would be straight forward to setup on my AWS account, but it turned out anything other than that! I put together a quick post to share my findings and to help future explorers looking to deploy Keycloak on AWS. Check it out at Integrating Keycloak as my Identity Provider for IAM Identity Centre: Part one, deploying Keycloak on AWS [hands on]

AWS SDK for pandas
In the post, Advanced patterns with AWS SDK for pandas on AWS Glue for Ray, Abdel Jaidi, Anton Kukushkin, and Leon Luttenberger showcase some more advanced patterns to run your workloads using AWS SDK for pandas. In particular, these examples demonstrated how Ray is used within the library to distribute operations for several other AWS services, not just Amazon S3. [hands on]
Notation
Notation is a CLI project to add signatures as standard items in the registry ecosystem, and to build a set of simple tooling for signing and verifying these signatures. Jimmy Ray and Jesse Butler have put together this great post, Announcing Container Image Signing with AWS Signer and Amazon EKS that walks you through the newly launched AWS Signer Container Image Signing. This new service provides the capability for customers to have native AWS support for signing and verifying container images stored in container registries like Amazon Elastic Container Registry (Amazon ECR). AWS Signer is a fully managed code signing service to ensure trust and integrity of your code, and supports signing and verifying container images using Notation.
The blog post looks at some of the upstream projects that AWS teams have been contributing to (such as kyverno-notation-aws and Ratify). Also don't miss Jimmy's sample repo, k8s-notary-admission that provides a non-production example of how to use the Notation CLI with AWS Signer to verify container image signatures in Kubernetes for container images stored in private Amazon ECR registries.

Make sure you check out this weeks must read post.
deequ
AWS Glue Data Quality allows you to measure and monitor the quality of your data so that you can make good business decisions. Built on top of the open-source DeeQu framework, AWS Glue Data Quality provides a managed, serverless experience.
Last week there was a series of posts that are worth checking out if you are exploring this open source framework. The series kicked off with, Getting started with AWS Glue Data Quality from the AWS Glue Data Catalog where Stuti Deshpande, Jesus Max Hernandez, Divya Gaitonde, Joseph Barlan, and Aniket Jiddigoudar talk about the ease and speed of incorporating data quality rules using AWS Glue Data Quality into your Data Catalog tables and how to run recommendations and evaluate data quality against your tables. The post provides links to the other posts that explore different dimensions of how to use AWS Glue Data Quality. Make sure you check out this series of posts, top notch stuff.
ecs-compose-x
AWS Community Builder John Milne was a guest on Build on Open Source a while back (check out the session) talking about his open source journey and showing us some of his open source projects. In his latest blog post, Journey of creating a new AWS CloudFormation resource shows you how to create custom Cloudformation resources and how to integrate them using ecs-compose-x and troposphere.
LLM roundup
Last week we saw a number of interesting posts covering the very hot large language model space. The pick of these for me were:
- Train a Large Language Model on a single Amazon SageMaker GPU with Hugging Face and LoRA shows you how to train the 7-billion-parameter BloomZ model using just a single graphics processing unit (GPU) on Amazon SageMaker [hands on]
- Announcing the launch of new Hugging Face LLM Inference containers on Amazon SageMaker looks at the release of a new Hugging Face Deep Learning Container (DLC) for inference with Large Language Models (LLMs) [hands on]
Big data and analytics
- Best practices for migrating SQL Server MERGE statements to Babelfish for Aurora PostgreSQL covers one use case of the Babelfish Compass tool to convert them to equivalent Babelfish T-SQL code [hands on]

- Cross-account Amazon Aurora MySQL migration with Aurora cloning and binlog replication for reduced downtime explains the various steps involved to migrate your Aurora MySQL cluster from one AWS account to another AWS account while setting up binary log replication to reduce the downtime [hands on]

- Deep dive on Amazon MSK tiered storage dives deep into the underlying infrastructure affects Apache Kafka performance when you use Amazon Managed Streaming for Apache Kafka (Amazon MSK) tiered storage [hands on]

- Stream data with Amazon DocumentDB, Amazon MSK Serverless, and Amazon MSK Connect is a hands on guide to help you run and configure the open-source MongoDB Kafka connector to move data between Amazon MSK and Amazon DocumentDB [hands on]

Other posts and quick reads
- Build high-performance ML models using PyTorch 2.0 on AWS – Part 1 demonstrates the performance and ease of running large-scale, high-performance distributed ML model training and deployment using PyTorch 2.0 on AWS [hands on]

- Create RESTful APIs on AWS with OpenAPI Specification (With No Coding) looks at how you can use AWS serverless technologies and the OpenAPI specification [hands on]
- Announcing Amazon S3 checksums support in the AWS SDK for Kotlin shows you how to begin using Amazon S3 checksums with the AWS SDK for Kotlin [hands on]
- Orchestrate NVIDIA Isaac Sim and ROS 2 Navigation on AWS RoboMaker with a public container image dives deep into how to run high-fidelity simulations using NVIDIA Isaac Sim and ROS 2 Navigation on AWS RoboMaker [hands on]

Quick updates
Apache Airflow
Amazon Managed Workflows for Apache Airflow (MWAA) now supports in-place version upgrades for environments version 2.x and later.
Amazon MWAA is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud. With in-place version upgrades on Amazon MWAA, customers can seamlessly upgrade their existing version 2.x environments to newer available Airflow versions while retaining the execution history and configurations, enabling them to leverage the latest capabilities of the Airflow platform. Amazon MWAA manages the entire upgrade process, from provisioning new Apache Airflow versions to upgrading the metadata database. In case of a failure during the upgrade, Amazon MWAA is designed to roll back to the previous stable version and the associated metadata database snapshot.
Make sure you read Introducing in-place version upgrades with Amazon MWAA, where Parnab Basak, Fernando Gamero, and Shubham Mehta walk you through this in depth and look at typical use cases and considerations you need to think about.
Apache Cassandra
Amazon Keyspaces (for Apache Cassandra) is a scalable, serverless, highly available, and fully managed Apache Cassandra-compatible database service. Amazon Keyspaces now supports Multi-Region Replication. Amazon Keyspaces Multi-Region Replication is a new capability that provides you with automated, fully-managed, active-active replication across the AWS Regions of your choice. You can improve both availability and resiliency from regional degradation while also benefiting from low latency local reads and writes for global applications. With Multi-Region Replication, Keyspaces asynchronously replicates data between Regions and data is typically propagated within a second. Multi-Region Replication also eliminates the difficult work of resolving update conflicts and correcting for data divergence issues, enabling you to focus on your application.
For those wanting more details, then check out this post, Announcing Amazon Keyspaces Multi-Region Replication where Michael Raney and Meet Bhagdev look at the benefits and use cases of this new feature and demonstrate how to get started using Multi-Region Replication in Amazon Keyspaces.
Apache Spark
Amazon EMR on EKS now supports Spark Operator and spark-submit as new job submission models for Apache Spark, in addition to the existing StartJobRun API. With today’s launch, you now have the flexibility to submit your Apache Spark jobs via your preferred submission model on Amazon EMR on EKS without needing to change your application.
Prior to today’s launch, you could only submit Apache Spark jobs via the StartJobRun API, including using the AWS CLI and AWS Controllers for Kubernetes (ACK). Customers with existing Apache Spark applications running Spark Operator or spark-submit would have to make changes to their applications in order to use Amazon EMR on EKS. With this feature, you can now run your applications on EMR on EKS without changing them, benefit from the EMR Spark runtime performance and features, and save time by using the spark-submit and Spark Operator you are already familiar with.
Read Introducing Amazon EMR on EKS job submission with Spark Operator and spark-submit where Lotfi Mouhib and Vara Bonthu walk you through the process of setting up and running Spark jobs using both Spark Operator and spark-submit.
Ray
AWS Glue for Ray, a data integration engine option on AWS Glue, is now generally available. AWS Glue for Ray helps data engineers and ETL (extract, transform, and load) developers scale their Python jobs. AWS Glue for Ray combines that serverless capability for data integration with Ray (ray.io), a popular new open-source compute framework that helps you scale Python workloads.
Similar to Apache Spark and Python engines on AWS Glue, you only pay for the resources that you use while running code, and you don’t need to configure or tune the resources. AWS Glue for Ray facilitates the distributed processing of your Python code over multi-node clusters. You can create and run Ray jobs anywhere that you can run AWS Glue ETL jobs. This includes existing AWS Glue jobs, command line interfaces (CLIs), and APIs. You can select the AWS Glue for Ray engine locally or through notebooks on AWS Glue Studio and Amazon SageMaker Studio Notebook. When the Ray job is ready, you can run it on demand or on a schedule.
Ruby
AWS Lambda now supports Ruby 3.2 as both a managed runtime and a container base image. Developers creating serverless applications in Lambda with Ruby 3.2 can take advantage of new features such as endless methods, a new Data class, improved pattern matching, and performance improvements. For more information on Lambda’s support for Ruby 3.2, see our blog post at Ruby 3.2 runtime now available in AWS Lambda.
To deploy Lambda functions using Ruby 3.2, upload the code through the Lambda console and select the Ruby 3.2 runtime. You can also use the AWS CLI, AWS Serverless Application Model (AWS SAM) and AWS CloudFormation to deploy and manage serverless applications written in Ruby 3.2. Additionally, you can also use the AWS-provided Ruby 3.2 base image to build and deploy Ruby 3.2 functions using a container image. To migrate existing Lambda functions running earlier Ruby versions, review your code for compatibility with Ruby 3.2 and then update the function runtime to Ruby 3.2.
To dive deeper, read the post Ruby 3.2 runtime now available in AWS Lambda where Praveen Koorse goes into more details including stuff you need to know to get started.
Videos of the week
Cedar
Check out Mike Hicks as he demo's features of the Cedar policy language during the Open Source Summit NA in Vancouver last month. You should also read the supporting post in the New Stack, The Cedar Programming Language: Authorization Simplified
krr
Join Jeremy Cowan and Shane Corbett from the Containers from the Couch posse as they speak with guest Natan Yellin at how you can optimise your container resources using krr](https://aws-oss.beachgeek.co.uk/2vv), an open source project from Robusta.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
London Open Source Data Infrastructure Meetup
Huckletree Shoreditch, June 14th 6:30PM - 9:30PM
As part of London Tech Week Aiven are co-hosting the 'London Open Source Data Infrastructure Meetup' on the 14th of June. This event is in collaboration with Hugh Evans from Daemon the 'AI and Deep Learning for Enterprise' group. The speaker panel includes Ricardo Sueiras from Amazon Web Services (AWS) discussing the wonders of Apache Airflow, Davies Oludare from Confluent shedding light on the intricate world of Kafka, and Ed Shee from Seldon breaking down the nuances of ML-powered summarisation.
Spaces are limited, so make sure you reserve your spot by checking and out the meetup page
Open Source Festival
Lagos, Nigeria - June 15th-17th
An established and essential event for all open source developers, Open Source Festival promises to be even bigger and better than previous years. I feel very privileged to have spoken at this event in 2020, and so make sure you check this out if you are in the region or perhaps if you are maybe looking to sponsor an open source event, then maybe this is the one you should check out.
Check out more on their homepage, Open Source Festival
Live AWS and Apache Hudi Workshop
Online, June 22nd at 8am PT
Nadine Farah and Soumil S are teaming up to deliver a live workshop that will mimic a typical use case, in this instance, building near real time dashboards for a fictional ride sharing company.

Make sure you reserve your place by going to the registration page, Live AWS and Apache Hudi Workshop: Build a ride share lakehouse platform
Cortex
Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen


















