
Following up from my previous post on Ragna, I wanted to share following the announcement of Meta's Llama2 13b model availability within Amazon Bedrock, how you can incorporate that.
I have also put together a GitHub repo that shares the code, something that I got quite a few questions from the original post.
Adding Meta's Llama2
As with adding Amazon Bedrock's Anthropic's Claude support, it was pretty straight forward to modify the original code to add support for Llama2.
Note! One thing that did catch me out during testing, was that I had forgotten to enable Model access in the Amazon Bedrock console. It was also at this point I realised that Llama2 is currently only available in us-east-1, so I had to change my BEDROCK_AWS_REGION environment variable to reflect that.
The first thing I did was to add a new class for Llama2.
class AmazonBedRockLlama2(AmazonBedrockAssistant):
"""[Amazon Bedrock Llama2](https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html#models-supported)
!!! info "AWS credentials required. Please set BEDROCK_AWS_REGION="{amazon bedrock region}" environment variables"
"""
_MODEL = "llama2-13b-chat-v1"
_CONTEXT_SIZE = 4096
The observant reader will notice that the CONTEXT size is smaller than for Claude. Do not try and increase this as the API calls will fail, and this is the maximum current size.
I then modified the main function within this class to case switch based on whether we are calling Anthropic Claude models, or Meta's Llama model.
def _call_api(
self, prompt: str, sources: list[Source], *, max_new_tokens: int
) -> str:
print("Connecting to Amazon Bedrock region : " + os.environ["BEDROCK_AWS_REGION"])
bedrock = boto3.client(service_name='bedrock-runtime',
region_name=os.environ["BEDROCK_AWS_REGION"])
# See https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_InvokeModel.html
if self._MODEL == "claude-v2" or self._MODEL == "claude-instant-v1":
print ("Using Amazon Bedrock Anthropic Claude Model")
prompt_config = {
"prompt": self._instructize_prompt(prompt, sources),
"max_tokens_to_sample": max_new_tokens,
"temperature": 0.0
}
try:
response = bedrock.invoke_model(
body=json.dumps(prompt_config),
modelId=f"anthropic.{self._MODEL}"
)
response_body = json.loads(response.get("body").read())
return cast(str, response_body.get("completion"))
except Exception as e:
raise ValueError(f"Error raised by inference endpoint: {e}")
if self._MODEL == "llama2-13b-chat-v1":
print ("Using Amazon Bedrock Llama2")
prompt_config = {
"prompt": self._instructize_prompt(prompt, sources),
"temperature": 0.0,
"top_p": 0.9,
"max_gen_len": 4096,
}
try:
response = bedrock.invoke_model(
body=json.dumps(prompt_config),
modelId=f"meta.{self._MODEL}"
)
response_body = json.loads(response.get("body").read())
return cast(str, response_body.get("generation"))
except Exception as e:
raise ValueError(f"Error raised by inference endpoint: {e}")
You will notice that the parameters are changed slightly within this new provider to accommodate the needs when calling this model.
We now have to update the init.py file to include access to this:
"Claude",
"ClaudeInstant",
"Gpt35Turbo16k",
"Gpt4",
"Mpt7bInstruct",
"Mpt30bInstruct",
"RagnaDemoAssistant",
"AmazonBedRockClaude",
"AmazonBedRockClaudev1",
"AmazonBedRockLlama2"
]
from ._anthropic import Claude, ClaudeInstant
from ._demo import RagnaDemoAssistant
from ._mosaicml import Mpt7bInstruct, Mpt30bInstruct
from ._openai import Gpt4, Gpt35Turbo16k
from ._bedrock import AmazonBedRockClaude, AmazonBedRockClaudev1, AmazonBedRockLlama2
And that is it. After we save the files, we can check this works by running "ragna init" and making sure we see our new options.
? Which assistants do you want to use? (Use arrow keys to move, <space> to select, <a> to toggle, <i> to invert)
○ Anthropic/claude-2
○ Anthropic/claude-instant-1
» ○ Ragna/DemoAssistant
○ MosaicML/mpt-7b-instruct
○ MosaicML/mpt-30b-instruct
○ OpenAI/gpt-4
○ OpenAI/gpt-3.5-turbo-16k
● AmazonBedRock/claude-v2
● AmazonBedRock/claude-instant-v1
● AmazonBedRock/llama2-13b-chat-v1
When we select this new provider, our configuration file now looks like:
local_cache_root = "/Users/{user}/.cache/ragna"
[core]
queue_url = "/Users/{user}/.cache/ragna/queue"
document = "ragna.core.LocalDocument"
source_storages = ["ragna.source_storages.Chroma"]
assistants = ["ragna.assistants.AmazonBedRockClaude", "ragna.assistants.AmazonBedRockClaudev1", "ragna.assistants.AmazonBedRockLlama2"]
[api]
url = "http://127.0.0.1:31476"
origins = ["http://127.0.0.1:31477"]
database_url = "sqlite:////Users/{user}/.cache/ragna/ragna.db"
authentication = "ragna.core.RagnaDemoAuthentication"
[ui]
url = "http://127.0.0.1:31477"
origins = ["http://127.0.0.1:31477"]
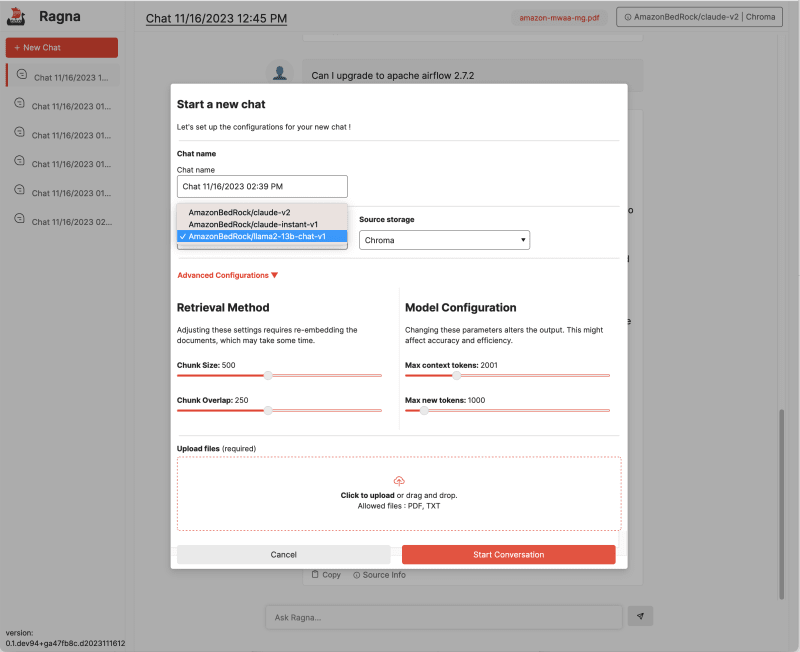
When we run "ragna ui" we need to create a NEW CHAT and specify Llama2 as the model.
And once uploaded we start interacting with our document.

We can now see that we are calling the Amazon Bedrock Llama2 APIs
INFO: 127.0.0.1:49599 - "POST /document HTTP/1.1" 200 OK
INFO: 127.0.0.1:49600 - "POST /chats HTTP/1.1" 200 OK
INFO:huey:Executing ragna.core._queue._Task: 4a46597d-edca-4a3a-8851-747cde783df3
INFO:huey:ragna.core._queue._Task: 4a46597d-edca-4a3a-8851-747cde783df3 executed in 7.835s
INFO: 127.0.0.1:49600 - "POST /chats/5c9b21fc-9069-4bef-a5f2-56925f5e6855/prepare HTTP/1.1" 200 OK
INFO: 127.0.0.1:49600 - "GET /chats HTTP/1.1" 200 OK
INFO:huey:Executing ragna.core._queue._Task: ac266052-7d1a-4d86-88f5-da9cc8ee3938
INFO:huey:ragna.core._queue._Task: ac266052-7d1a-4d86-88f5-da9cc8ee3938 executed in 0.036s
INFO:huey:Executing ragna.core._queue._Task: b17cfa24-ecb2-4150-98a8-f47b3afda0cf 2 retries
Connecting to Amazon Bedrock region : us-east-1
Using Amazon Bedrock Llama2
INFO:huey:ragna.core._queue._Task: b17cfa24-ecb2-4150-98a8-f47b3afda0cf 2 retries executed in 3.955s
INFO: 127.0.0.1:49631 - "POST /chats/5c9b21fc-9069-4bef-a5f2-56925f5e6855/answer?prompt=What%20is%20this%20doc%20about%3F HTTP/1.1" 200 OK
INFO:huey:Executing ragna.core._queue._Task: 968d4904-38b4-4ef8-b9cb-31d4e027460f
INFO:huey:ragna.core._queue._Task: 968d4904-38b4-4ef8-b9cb-31d4e027460f executed in 0.025s
INFO:huey:Executing ragna.core._queue._Task: a23e534a-0af1-4e17-9ac8-19f901735f13 2 retries
Connecting to Amazon Bedrock region : us-east-1
Using Amazon Bedrock Llama2
INFO:huey:ragna.core._queue._Task: a23e534a-0af1-4e17-9ac8-19f901735f13 2 retries executed in 5.999s
INFO: 127.0.0.1:49649 - "POST /chats/5c9b21fc-9069-4bef-a5f2-56925f5e6855/answer?prompt=What%20versions%20of%20Apache%20Airflow%20are%20supported%3F HTTP/1.1" 200 OK
Conclusion
Make sure you read the README file on how you can get started, and I hope that this will help any of you looking to explore Ragna and wanting to use these models available in Amazon Bedrock.


















