I blogged about FerretDB when it was out. FerretDB is an open-source alternative to MongoDB, providing the same API and storing the documents in PostgreSQL. What works on PostgreSQL works on YugabyteDB, with makes it able to scale out. YugabyteDB is the PostgreSQL open-source distributed SQL database.
The latest version of FerretDB introduced an interesting feature: Embedded FerretDB. As this proxy is stateless, it makes sense to embed it rather than running it as a separate process. They have provided a simple example: https://github.com/FerretDB/embedded-example and I'll run it with a YugabyteDB database instead of PostgreSQL.
Look at YugabyteDB Quick Start so start your database. The easiest is a free managed database in the YugabyteDB Managed Cloud, https://cloud.yugabyte.com, where you can provision it on any region of AWS or GCP. To test, I choose a free database, and look at the connection information in "Connect":
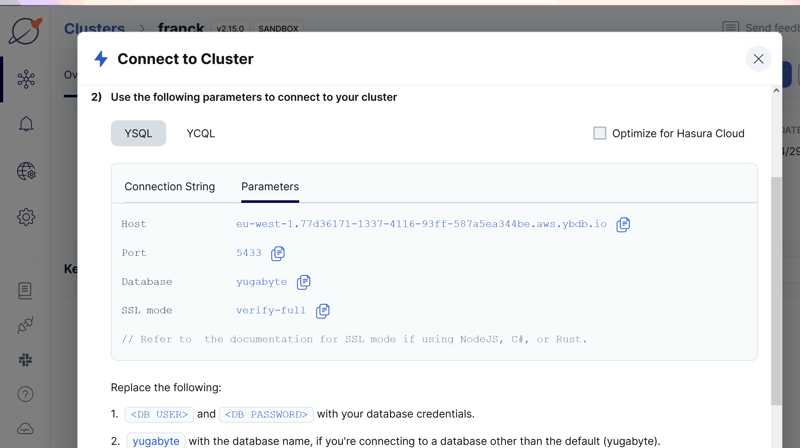
The password for admin is not displayed here, you provided it when creating the cluster. Of course, you should create additional database and user, but this is an example, let's keep it easy.
The FerretDB example code has the connection string hardcoded in main.go as PostgreSQLURL. I'll runn a simple sed command to replace it with my YugabyteDB Managed cloud connection string: postgres://admin:MyPassword@eu-west-1.77d36171-1337-4116-93ff-587a5ea344be.aws.ybdb.io:5433/yugabyte
git clone https://github.com/FerretDB/embedded-example.git
cd embedded-example
sed -e '/PostgreSQLURL/s?".*"?"postgres://admin:MyPassword@eu-west-1.77d36171-1337-4116-93ff-587a5ea344be.aws.ybdb.io:5433/yugabyte"?options=-c%20enable_nestloop%3Doff' -i main.go
go run main.go
Note that I have added enable_nestloop=off because FerretDB queries the information_schema many times and this can be slow when there is a latency to the YugabyteDB master (issue #7745). Disabling nested loop is ok here because FerretDB doesn't create indexes in the current version. The solution, if querying information_schema remains, will be to do this with a hint /*+ Set(enable_nestloop off) */ but it may be optimized on YugabyteDB side at that time.
The output tells you that an new document has been inserted:

It exposes a mongodb endpoint, but I can also query it in SQL, from the Cloud Shell provided by YugabyteDB managed:
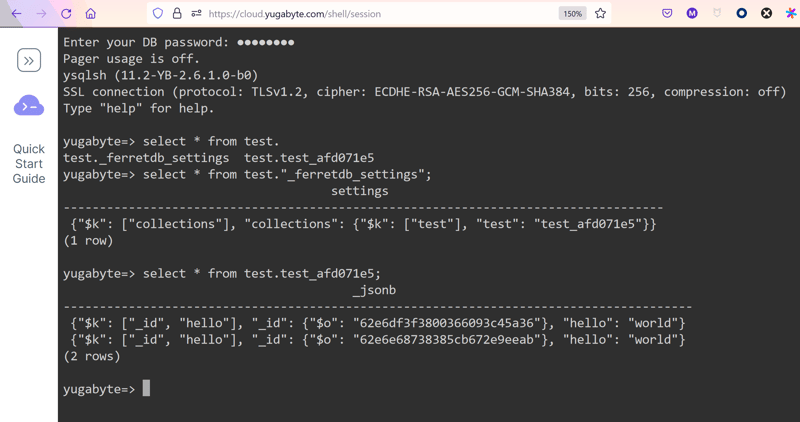
As you see, running with a YugabyteDB database instead of a PostgreSQL one is rally easy. With YugabyteDB Managed, the endpoint is a load balancer, which means that you have nothing to change in the application to benefit from the Scaling, High Availability and Geo Distribution provided by YugabyteDB.
If you run with an on-premises deployment without a load balancer, the only change is using the PGX driver from Yugabyte:
git clone https://github.com/FerretDB/FerretDB.git
cd FerretDB
sed -e 's?"github.com/jackc/pgx/v4"?"github.com/yugabyte/pgx/v4"?' \
-i $(grep -rl "github.com/jackc/pgx/v4")
With the Yugabyte PGX driver, you still provide only one endpoint, any node from the YugabyteDB cluster, and it automatically discovers the other nodes to balance the new connections. You can then benefit from the elasticity of the distributed database without any additional component.
What about performance?
In the current version (FerretDB 0.5.1) no indexes are created, there there's no point testing performance here. I mentioned in the previous post how it can be indexed. Of course, the way to go is having the primary key on the "_id" but to be MongoDB compatible, and ID can have different types. The issue Support field extraction into separate columns #226 is tagged as "code/feature", "not ready". The issue Support simple query pushdown for Postgres #896 is also looking at indexes as I did in my previous post. So, performance is still work on progress and for the moment you have to think about the indexes yourself if you want to scale as the table is really simple:
yugabyte=> \d test.test_afd071e5
Table "test.test_afd071e5"
Column | Type | Collation | Nullable | Default
--------+-------+-----------+----------+---------
_jsonb | jsonb | | |
The best for the moment is looking at the queries (from pg_stat_statement) and create the right indexes. Of course, this requires knowing the schema in advance.
Without indexes, all queries will be Seq Scan and then you may benefit from enabling predicate pushdown to avoid having rows sent from storage nodes (table servers) to the one that is processing the query (PostgreSQL backend):
yugabyte=> alter user admin set yb_enable_expression_pushdown = on;
ALTER ROLE


















