Technically, a database runs on servers that cannot be started on a per-query basis because it has to keep a state. On disk for persistence. In-memory for performance and concurrent transaction management. When a monolithic database is called "serverless", like Aurora Serverless v2, it runs on a VM that is always there, maybe with scaled-down resources, or even paused, but the server is still provisioned. The "serverless" part is about the billing start and stop, I've written about this in What is a serverless database?.
With a distributed database, which can scale-out, "serverless" means that only a minimal configuration is always up, similar to the free tier, and additional nodes can be started on demand. This minimal configuration doesn't count for usage, and then the service is serverless from a billing point of view.
Lambdas are stateless, but are not so much different. In order to avoid cold start latency, AWS leaves them up for a while, even beyond the billed duration. This can be used to lower the impedance mismatch between functions and database, by keeping connections open beyond the lambda invocation duration.
In short: without the need for a proxy connection pool, you can keep your database connection open by referencing it in a global variable. As long as the invocations are frequent enough, the connection will stay. This depends on many parameters: how long the lambda stays warm, and how the connections are managed. Here is an example from Node.JS
Lab environment
I'm using the deployment on EKS from YugabyteDB on Amazon EKS. I'll connect to only one AZ, with the yb-tserver-service load balancer in eu-west-1c:
kubectl get services -n yb-demo-eu-west-1c --field-selector "metadata.name=yb-tserver-service" -o jsonpath='postgresql://{.items[0].status.loadBalancer.ingress[0].hostname}:{.items[0].spec.ports[?(@.name=="tcp-ysql-port")].port}'
postgresql://a0b821173a97b49ef90c6dd7d9b26551-79341159.eu-west-1.elb.amazonaws.com:5433
I'm using the public endpoint here for the lab but you should run the lambda in the database VPC. And with 3 availability zones, one lambda in each, connecting to the database pod in the same zone.
create table
I'll use a table to log the connection activity. My lambda function will insert all rows from pg_stat_activity, adding the sequence number of the call (callseq), an identifier of the lambda container generated randomly (lambda), the transaction timestamp (now), the server and port we are connected to (inet_server_addr and pg_backend_pid). The information for the current session will be the one where pid=pg_backend_pid but I'll also do some analytics on the other sessions from the same server (don't forget that YugabyteDB is a distributed database, the PostgreSQL views show the statistics for the node we are connected to).
drop table if exists ybdemo_stat_activity;
create table if not exists ybdemo_stat_activity as
select 0 id, 0 lambda, now(), inet_server_addr(), pg_backend_pid(), * from pg_stat_activity;
create role
I'm creating an execution role:
cat > ybdemo-lambda-trust-policy.json <<'CAT'
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
CAT
aws iam create-role --role-name ybdemo-lambda-role \
--assume-role-policy-document file://ybdemo-lambda-trust-policy.json
lambda code:
My lambda code is simple. A simple node-postgres connection initialized in the global section, out of the event handler, to stay during the lambda container lifecycle. A SQL query to insert from pg_stat_activity and return a summary. The handler section will simply execute this and return the result.
I do one more thing in the global session: keep a random number to identify my lambda container.
// imports the PostgreSQL connector, create a connection
const {
Pool,
Client
} = require('pg')
// connect and define the sql query
const db = new Client({application_name:"lambda"});
db.connect();
// query
const sql = `
with insert_statement as (
insert into ybdemo_stat_activity
select $1 callseq, $2 lambda, now()
,inet_server_addr(),pg_backend_pid()
,*
from pg_stat_activity
returning *
) select format(
'%5s sessions, %6s th call, %6s seconds up, %s:%s->%s %s'
,(select count(*) from insert_statement where application_name=\'lambda\')
,$1, to_char(extract(epoch from now()-backend_start),'99999.9')
, client_addr,client_port,inet_server_addr,pid ) result
from insert_statement
where pg_backend_pid=pid
`;
// a random number to identify the lambda container state
const lambda = Math.floor(1000 * Math.random());
// lambda handler that is called on each invocation
exports.handler = async (event) => {
// Insert info from event and from pg_stat_activity
const result = await db.query(sql, [event["id"], lambda]);
return result.rows[0].result;
};
I did not mention connection info as I'll use the libpq environment variables. Even for the password, which is ok for a lab, but should to to a secret in real life.
Deploy
I get the node-postgres module, zip it with my code (the above was saved in ybdemo-lambda.js), and create the function with the environement variables for the connection (and setting PGAPPNAME to identify my connections in pg_stat_activity.application_name)
npm install pg
zip -r ybdemo-lambda-role.zip node_modules ybdemo-lambda.js
aws lambda create-function --runtime nodejs14.x
--function-name ybdemo-lambda \
--zip-file fileb://ybdemo-lambda-role.zip \
--handler ybdemo-lambda.handler \
--environment 'Variables={PGAPPNAME=lambda, PGUSER=yugabyte, PGDBNAME=yugabyte, PGHOST=a0b821173a97b49ef90c6dd7d9b26551-79341159.eu-west-1.elb.amazonaws.com, PGPORT=5433}' \
--role $( aws iam get-role --role-name ybdemo-lambda-role --output json | jq -r '."Role"."Arn"' )
aws lambda wait function-updated --function-name ybdemo-lambda
The lambda can be tested easily, with a simple {"id":"0"} payload. And the table can be reset with a truncate ybdemo_stat_activity.
invoke
I run the following script to invoke the lambda in the following way:
- send 20 invocations in parallel
- wait an increasing number of seconds My goal is to look at the connection duration when the idle time increases.
id=0
for sequential in {1..36000}
do
sleep $sequential
for parallel in {1..20}
do
id=$(( $id + 1 ))
(
aws lambda invoke --function-name ybdemo-lambda \
--cli-binary-format raw-in-base64-out \
--payload '{"id":"'$id'"}' /tmp/$parallel.log
)&
done > /dev/null
wait
for parallel in {1..10} ; do
awk '/sessions/{if($6<60){x="<"}else{x=">"};print x,$0}' /tmp/$parallel.log | ts
done
done | tee out.log
Here is the stdout log at the interesting points. At 21:40, just after starting it, I have between 2 and 10 sessions actives. Some were started 10 second before, some 5 seconds before and some just started. This is the warmup when invoking the function every second:
Mar 15 21:40:44 > " 2 sessions, 28 th call, 5.2 seconds up, 192.168.50.252:39869->192.168.89.91 31263"
Mar 15 21:40:44 > " 2 sessions, 29 th call, 5.3 seconds up, 192.168.50.252:58333->192.168.89.91 31262"
Mar 15 21:40:44 > " 2 sessions, 30 th call, 5.2 seconds up, 192.168.50.252:58333->192.168.89.91 31262"
Mar 15 21:40:50 > " 10 sessions, 41 th call, .2 seconds up, 192.168.86.136:56035->192.168.73.172 31085"
Mar 15 21:40:50 > " 3 sessions, 42 th call, 11.6 seconds up, 192.168.19.243:36648->192.168.73.172 31003"
Mar 15 21:40:50 > " 8 sessions, 43 th call, .2 seconds up, 192.168.86.136:64244->192.168.89.91 31311"
Mar 15 21:40:50 > " 8 sessions, 44 th call, .1 seconds up, 192.168.86.136:23390->192.168.89.91 31324"
Mar 15 21:40:50 > " 8 sessions, 45 th call, .2 seconds up, 192.168.86.136:28169->192.168.89.91 31309"
Mar 15 21:40:50 > " 3 sessions, 46 th call, 11.6 seconds up, 192.168.19.243:28818->192.168.73.172 31004"
Mar 15 21:40:50 > " 10 sessions, 47 th call, 11.9 seconds up, 192.168.19.243:44767->192.168.73.172 30999"
Mar 15 21:40:50 > " 5 sessions, 48 th call, 11.6 seconds up, 192.168.19.243:36648->192.168.73.172 31003"
Mar 15 21:40:50 > " 8 sessions, 49 th call, .1 seconds up, 192.168.86.136:54003->192.168.89.91 31312"
After 10 minutes where waits between invocations is about 30 seconds (according to my script, the 600th call is 30*20) the number of active sessions has been reduced. Some are there from 466 seconds so several minutes. And some have bee created recently:
Mar 15 21:50:04 > " 4 sessions, 586 th call, 97.3 seconds up, 192.168.19.243:9147->192.168.89.91 31784"
Mar 15 21:50:04 > " 4 sessions, 587 th call, 97.2 seconds up, 192.168.19.243:9147->192.168.89.91 31784"
Mar 15 21:50:04 > " 3 sessions, 588 th call, 34.2 seconds up, 192.168.86.136:56220->192.168.73.172 31587"
Mar 15 21:50:04 > " 4 sessions, 589 th call, 239.5 seconds up, 192.168.50.252:18790->192.168.89.91 31637"
Mar 15 21:50:04 > " 3 sessions, 590 th call, 466.0 seconds up, 192.168.86.136:7508->192.168.73.172 31200"
Mar 15 21:50:38 > " 3 sessions, 601 th call, 68.5 seconds up, 192.168.86.136:56220->192.168.73.172 31587"
Mar 15 21:50:38 > " 5 sessions, 602 th call, .1 seconds up, 192.168.50.252:10586->192.168.89.91 31904"
Mar 15 21:50:38 > " 5 sessions, 603 th call, .5 seconds up, 192.168.50.252:10586->192.168.89.91 31904"
Mar 15 21:50:38 > " 3 sessions, 604 th call, 68.6 seconds up, 192.168.86.136:56220->192.168.73.172 31587"
Mar 15 21:50:38 > " 3 sessions, 605 th call, 68.4 seconds up, 192.168.86.136:56220->192.168.73.172 31587"
10 minutes later where batches of invocations occur every 45 seconds, I have a stable situation where sessions are used for several minutes:
Mar 15 21:59:38 > " 3 sessions, 866 th call, 227.5 seconds up, 192.168.86.136:64034->192.168.89.91 32160"
Mar 15 21:59:38 > " 2 sessions, 867 th call, 353.1 seconds up, 192.168.19.243:51923->192.168.73.172 31795"
Mar 15 21:59:38 > " 3 sessions, 868 th call, 227.4 seconds up, 192.168.86.136:64034->192.168.89.91 32160"
Mar 15 21:59:39 > " 2 sessions, 869 th call, 353.2 seconds up, 192.168.19.243:51923->192.168.73.172 31795"
Mar 15 21:59:39 > " 2 sessions, 870 th call, 139.7 seconds up, 192.168.50.252:27110->192.168.73.172 32013"
Mar 15 22:00:27 > " 2 sessions, 881 th call, 401.3 seconds up, 192.168.19.243:51923->192.168.73.172 31795"
Mar 15 22:00:27 > " 1 sessions, 882 th call, 276.0 seconds up, 192.168.86.136:64034->192.168.89.91 32160"
Mar 15 22:00:27 > " 2 sessions, 883 th call, 401.7 seconds up, 192.168.19.243:51923->192.168.73.172 31795"
Mar 15 22:00:27 > " 2 sessions, 884 th call, 401.2 seconds up, 192.168.19.243:51923->192.168.73.172 31795"
Mar 15 22:00:27 > " 2 sessions, 885 th call, 188.2 seconds up, 192.168.50.252:27110->192.168.73.172 32013"
Mar 15 22:00:27 > " 2 sessions, 886 th call, 401.6 seconds up, 192.168.19.243:51923->192.168.73.172 31795"
Mar 15 22:00:27 > " 1 sessions, 887 th call, 275.8 seconds up, 192.168.86.136:64034->192.168.89.91 32160"
Mar 15 22:00:27 > " 2 sessions, 888 th call, 401.4 seconds up, 192.168.19.243:51923->192.168.73.172 31795"
Mar 15 22:00:27 > " 1 sessions, 889 th call, 276.0 seconds up, 192.168.86.136:64034->192.168.89.91 32160"
10 minutes later, when I reach 1 minute idle with no calls, I see that all sessions were recycled and stay only for a short time:
Mar 15 22:10:27 > " 1 sessions, 1102 th call, 599.1 seconds up, 192.168.50.252:6316->192.168.89.91 32404"
Mar 15 22:10:27 > " 1 sessions, 1103 th call, 599.4 seconds up, 192.168.50.252:6316->192.168.89.91 32404"
Mar 15 22:10:27 > " 1 sessions, 1106 th call, 598.9 seconds up, 192.168.50.252:6316->192.168.89.91 32404"
Mar 15 22:10:27 > " 1 sessions, 1107 th call, 599.2 seconds up, 192.168.50.252:6316->192.168.89.91 32404"
Mar 15 22:10:27 > " 1 sessions, 1109 th call, 599.3 seconds up, 192.168.50.252:6316->192.168.89.91 32404"
Mar 15 22:10:27 > " 1 sessions, 1110 th call, 599.2 seconds up, 192.168.50.252:6316->192.168.89.91 32404"
Mar 15 22:11:27 > " 1 sessions, 1122 th call, .4 seconds up, 192.168.19.243:31600->192.168.89.91 470"
Mar 15 22:11:28 > " 4 sessions, 1124 th call, .0 seconds up, 192.168.50.252:3844->192.168.73.172 329"
Mar 15 22:11:28 > " 1 sessions, 1125 th call, .5 seconds up, 192.168.19.243:31600->192.168.89.91 470"
Mar 15 22:11:28 > " 1 sessions, 1126 th call, .2 seconds up, 192.168.19.243:31600->192.168.89.91 470"
Mar 15 22:11:28 > " 3 sessions, 1127 th call, .2 seconds up, 192.168.19.243:23089->192.168.73.172 32759"
Mar 15 22:11:28 > " 4 sessions, 1129 th call, .1 seconds up, 192.168.50.252:55413->192.168.89.91 485"
Mar 15 22:11:28 > " 4 sessions, 1130 th call, .0 seconds up, 192.168.19.243:44858->192.168.89.91 512"
This situation is not very good because, even if the thoughput is low, we probably want to avoid the high latency of connection establishment.
Here is the CloudWatch info about invocations per minutes during that time. And the duration (around 10 milliseconds when connection is already established, and up to 400ms when it has to be established):
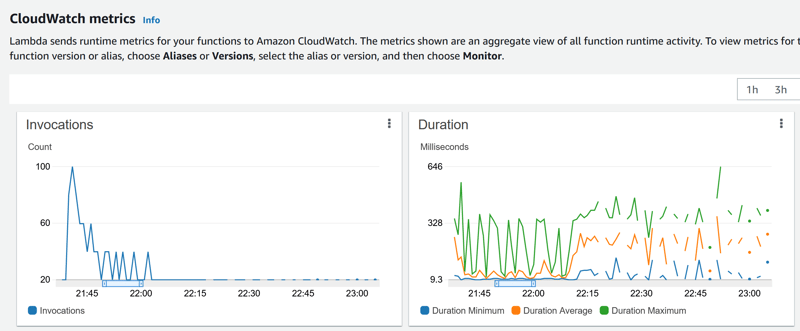
We see the two consequences when the delay between the 20 parallel calls was more than 60 seconds, after 22:10:
- 20 invocations per minutes
- an average duration that increases
Interestingly, with this side effect on connection reuse, the latency is better when the throughput is high.
This gives an idea when the one-connection-per-lambda is a good pattern: low response time on high throughput, but higher response time for the calls coming after a 50 second idle period where resources were released. Note that this threshold of 50 seconds may change. Lambda stays longer in a VPC, probably because the cold start takes longer to establish the network interfaces. But basically you don't know. Serverless is to reduce the cost, not for performance predictability. There's a penalty on the first activity after an idle period, and database connection adds latency on top of the lambda cold start.
Queries
CloudWatch metrics are nice to put colors on a dashboard displayed in the open space, or the manager's dashboard, but useless to get a proper understanding. The 1 minute collection is too large granularity, and, worse, not even mentioned with the metric. You have to guess that "Invocations" means "Invocations per minute". Displaying metrics without their unit is beyond my understanding.
This is why I logged all activity into a SQL table and here are some queries to look at it.
Duration of connexions:
select inet_server_addr, pg_backend_pid, count(*) num_transactions
,count(distinct client_addr||'.'||client_port) cli
,max(now-backend_start) duration
,min(backend_start),max(state_change)
from ybdemo_stat_activity
where pid=pg_backend_pid and application_name='lambda'
group by inet_server_addr, pg_backend_pid
order by min(backend_start),num_transactions;
\watch 1
I've been running that, while it was running, to see the efficiency of my connection. This shows that the first connections established (at 21:40) were reused (num_transactions) for several minutes (duration):
inet_server_addr | pg_backend_pid | num_transactions | cli | duration | min | max
------------------+----------------+------------------+-----+-----------------+-------------------------------+-------------------------------
192.168.73.172 | 30986 | 7 | 1 | 00:00:11.932485 | 2022-03-15 21:40:37.907971+00 | 2022-03-15 21:40:49.841667+00
192.168.89.91 | 31262 | 10 | 1 | 00:00:11.872039 | 2022-03-15 21:40:37.965718+00 | 2022-03-15 21:40:49.838397+00
192.168.89.91 | 31263 | 7 | 1 | 00:00:11.872959 | 2022-03-15 21:40:37.974278+00 | 2022-03-15 21:40:49.848074+00
192.168.73.172 | 30999 | 21 | 1 | 00:02:29.675678 | 2022-03-15 21:40:38.064616+00 | 2022-03-15 21:43:07.741319+00
192.168.89.91 | 31291 | 1 | 1 | 00:00:11.706519 | 2022-03-15 21:40:38.184802+00 | 2022-03-15 21:40:50.019467+00
192.168.73.172 | 31002 | 17 | 1 | 00:01:25.486407 | 2022-03-15 21:40:38.213024+00 | 2022-03-15 21:42:03.700187+00
192.168.73.172 | 31003 | 3 | 1 | 00:00:11.648665 | 2022-03-15 21:40:38.228717+00 | 2022-03-15 21:40:49.878288+00
192.168.73.172 | 31004 | 2 | 1 | 00:00:11.556312 | 2022-03-15 21:40:38.27944+00 | 2022-03-15 21:40:49.837692+00
192.168.73.172 | 31036 | 118 | 1 | 00:16:28.970863 | 2022-03-15 21:40:49.801615+00 | 2022-03-15 21:57:18.773253+00
192.168.89.91 | 31299 | 27 | 1 | 00:02:17.919504 | 2022-03-15 21:40:49.825594+00 | 2022-03-15 21:43:07.746279+00
192.168.73.172 | 31047 | 42 | 1 | 00:05:14.147926 | 2022-03-15 21:40:49.827667+00 | 2022-03-15 21:46:03.9762+00
192.168.89.91 | 31309 | 42 | 1 | 00:05:14.165137 | 2022-03-15 21:40:49.831468+00 | 2022-03-15 21:46:03.997366+00
192.168.73.172 | 31058 | 4 | 1 | 00:00:07.674117 | 2022-03-15 21:40:49.839944+00 | 2022-03-15 21:40:57.51483+00
192.168.89.91 | 31311 | 26 | 1 | 00:01:44.038435 | 2022-03-15 21:40:49.842479+00 | 2022-03-15 21:42:33.881741+00
192.168.73.172 | 31061 | 17 | 1 | 00:01:13.860713 | 2022-03-15 21:40:49.848705+00 | 2022-03-15 21:42:03.710331+00
However, after 22:10 they were rarely used for more than one call:
192.168.73.172 | 32759 | 1 | 1 | 00:00:00.168741 | 2022-03-15 22:11:27.342908+00 | 2022-03-15 22:11:27.634174+00
192.168.89.91 | 485 | 1 | 1 | 00:00:00.119303 | 2022-03-15 22:11:27.360684+00 | 2022-03-15 22:11:27.599676+00
192.168.73.172 | 32760 | 1 | 1 | 00:00:00.163574 | 2022-03-15 22:11:27.363632+00 | 2022-03-15 22:11:27.647167+00
192.168.89.91 | 487 | 1 | 1 | 00:00:00.14798 | 2022-03-15 22:11:27.372015+00 | 2022-03-15 22:11:27.645778+00
192.168.73.172 | 315 | 1 | 1 | 00:00:00.039631 | 2022-03-15 22:11:27.523149+00 | 2022-03-15 22:11:27.689861+00
192.168.89.91 | 512 | 1 | 1 | 00:00:00.030133 | 2022-03-15 22:11:27.540862+00 | 2022-03-15 22:11:27.697848+00
192.168.73.172 | 329 | 1 | 1 | 00:00:00.033113 | 2022-03-15 22:11:27.691827+00 | 2022-03-15 22:11:27.837617+00
192.168.89.91 | 566 | 6 | 1 | 00:00:00.527789 | 2022-03-15 22:12:28.470938+00 | 2022-03-15 22:12:28.999546+00
192.168.89.91 | 583 | 1 | 1 | 00:00:00.098232 | 2022-03-15 22:12:28.982645+00 | 2022-03-15 22:12:29.185139+00
192.168.89.91 | 584 | 1 | 1 | 00:00:00.119772 | 2022-03-15 22:12:28.98966+00 | 2022-03-15 22:12:29.217498+00
192.168.89.91 | 606 | 1 | 1 | 00:00:00.026619 | 2022-03-15 22:12:29.209509+00 | 2022-03-15 22:12:29.33623+00
192.168.89.91 | 619 | 2 | 2 | 00:00:00.139565 | 2022-03-15 22:12:29.248371+00 | 2022-03-16 07:17:18.408112+00
Total count
select count(*) total_transactions, max(now)-min(now) total_time
, count(*)/extract(epoch from max(now)-min(now)) "tx/sec"
from ybdemo_stat_activity
where pid=pg_backend_pid and application_name='lambda';
This shows the total number of calls recorded, and the transactions per second. Here is an example just few minutes after starting:
total_transactions | total_time | tx/sec
--------------------+-----------------+------------------
120 | 00:00:39.303633 | 3.05315287266192
(1 row)
Please remember that I'm not testing the performance here. The way I invoke the lambda is not efficient. And my goal is to test what happens with some idle activity.
Full log
select inet_server_addr,id,now,count(*) sessions
,count(distinct lambda) lambdas
,count(distinct client_addr) client_addrs
,count(distinct client_addr||'.'||client_port) client_ports
,round(extract(epoch from now-lag(now) over(order by now)))seconds_after
--,string_agg(distinct client_addr||'.'||client_port,',')
--,string_agg(distinct lambda::text,',')
,string_agg(distinct host(client_addr),',')
from ybdemo_stat_activity
where application_name='lambda'
group by inet_server_addr,id,now
order by id;
Here is when the idle period between invocations were was short (7 to 8 seconds) with 8 and 10 connections per node (I have 2 nodes here behind the load balancer, as you see in the inet_server_addr IP addresses) which serves the batch of 20 parallel calls. They all come from the same lambda (according to the random value I generate in a global variable. I see 3 client IP addresses, and 8 and 10 client ports per server.
inet_server_addr | id | now | sessions | lambdas | client_addrs | client_ports | seconds_after
------------------+------+-------------------------------+----------+---------+--------------+--------------+---------------
...
192.168.73.172 | 73 | 2022-03-15 21:40:57.14564+00 | 10 | 1 | 3 | 10 | 7 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.89.91 | 74 | 2022-03-15 21:40:57.567308+00 | 8 | 1 | 3 | 8 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.89.91 | 75 | 2022-03-15 21:40:57.515185+00 | 8 | 1 | 3 | 8 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 76 | 2022-03-15 21:40:57.568885+00 | 10 | 1 | 3 | 10 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 77 | 2022-03-15 21:40:57.558027+00 | 10 | 1 | 3 | 10 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.89.91 | 78 | 2022-03-15 21:40:57.344756+00 | 8 | 1 | 3 | 8 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 79 | 2022-03-15 21:40:57.544275+00 | 10 | 1 | 3 | 10 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.89.91 | 80 | 2022-03-15 21:40:57.49861+00 | 8 | 1 | 3 | 8 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.89.91 | 81 | 2022-03-15 21:41:05.876078+00 | 8 | 1 | 3 | 8 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 82 | 2022-03-15 21:41:05.916025+00 | 10 | 1 | 3 | 10 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 83 | 2022-03-15 21:41:05.856773+00 | 10 | 1 | 3 | 10 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 84 | 2022-03-15 21:41:05.872317+00 | 10 | 1 | 3 | 10 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.89.91 | 85 | 2022-03-15 21:41:05.958298+00 | 8 | 1 | 3 | 8 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 86 | 2022-03-15 21:41:05.817871+00 | 10 | 1 | 3 | 10 | 8 | 192.168.19.243,192.168.50.252,192.168.86.136
192.168.73.172 | 87 | 2022-03-15 21:41:05.876524+00 | 10 | 1 | 3 | 10 | 0 | 192.168.19.243,192.168.50.252,192.168.86.136
🤔 My knowledge on the lambda internals is too limited to understand all this. Is it one container (serving the 20 calls (8 and 10 TCP connections seen in each of the 2 database nodes) from threads balancing their TCP connections to 3 network interfaces (the 3 client IP addresses seen) in each. I'm guessing all that from the the PostgreSQL info in pg_stat_activity. YugabyteDB here, which is distributed to many nodes, uses PostgreSQL for the protocol and connection.
The numbers match, 18 TCP connections and CloudWatch showing 18 concurrent executions:
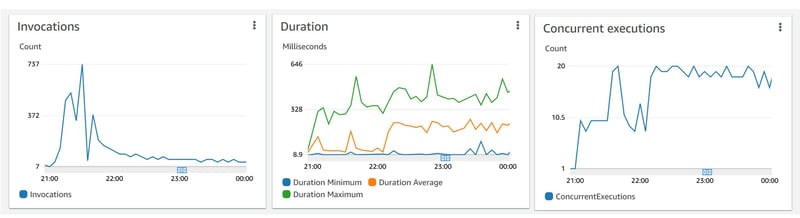
However, seeing only one value for the random global variable makes me think that, despite what is documented, concurrent executions can run on the same container, sharing the same global variables. I believe this, as it would not be thread safe to allow multiple executions. But this is not what I observe.
Billing duration
The cost when re-establishing the connection is not only in database resource usage, but also accounts in the billed duration of the lambdas:
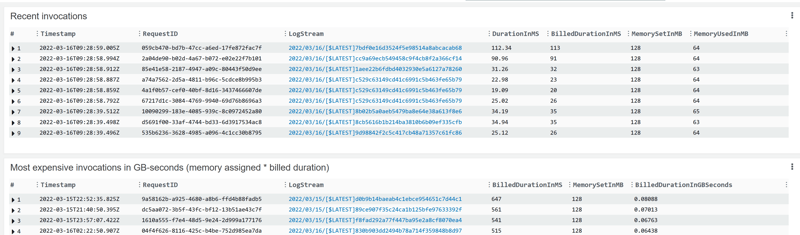
However, given that this occurs only with low throughput, the consequence is limited. Note that in order to get this to be logged I have added the AWSLambdaBasicExecutionRole to ybdemo-lambda-role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
This blog post shows how to investigate. Without full understanding, I don't think it is a good recommendation to rely on a global connection handle staying for a while. For predictable performance and safe executions, it is probably better to setup a pgBouncer in each AZ. Or, instead of deploying your procedural code in a lambda, why not deploy as a stored procedure and call it though PostgREST as I did there?


















