Hi!
In part of my demos / explanations on Prompt Engineering, I use Azure OpenAI Services, and the Azure OpenAI Studio.
Note: You can request access to Azure OpenAI Services here: https://aka.ms/oai/access.
In the Completion Playground there are several parameters that we can use to change the performance of our model.
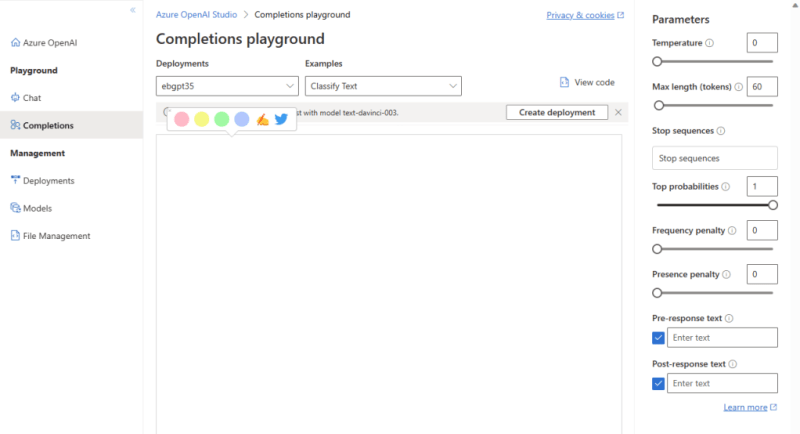
These are the ones I usually explain:
How “creative” the model should be
Temperature:
- Temperature controls randomness in the model’s responses.
- Lowering the temperature makes the responses more repetitive and predictable.
- Increasing the temperature makes the responses more creative and unexpected.
- Adjusting the temperature can be done independently of adjusting Top P.
Top probabilities (Top P):
- Top P is another way to control randomness in the model’s responses.
- Lowering Top P limits the model’s token selection to more likely tokens.
- Increasing Top P allows the model to choose from tokens with both high and low likelihood.
- Adjusting Top P can be done independently of adjusting temperature.
How to control the token usage
Max length (tokens):
- Max length sets a limit on the number of tokens in the model’s response.
- The API supports a maximum of 4000 tokens for both the prompt and the response.
- One token is roughly equivalent to four characters in typical English text.
Stop sequences:
- Stop sequences allow you to specify where the model should stop generating tokens in a response.
- You can define up to four sequences as stop points.
- The returned text won’t include the stop sequences.
How to add Pre and Post text to the output
Pre-response text:
- Pre-response text is inserted after the user’s input and before the model’s response.
- It helps provide context or additional information to the model for generating a response.
- The inserted text prepares the model to better understand and address the user’s query.
Post-response text:
- Post-response text is inserted after the model’s generated response.
- It encourages further user input and promotes a conversational flow.
- By adding text after the response, you can guide the user to provide more information or continue the conversation.
There are other parameters and other options to change the behavior of a model. However, these are the ones that I mostly explain and use on live prompting demos.
Happy coding!
Greetings
El Bruno
More posts in my blog ElBruno.com.
More info in https://beacons.ai/elbruno


















