
Quem me segue há algum tempo sabe que eu sou um grande fã de falar sobre novas tecnologias – também daquelas que não são tão novas assim – e, principalmente, sou um grande fã do gRPC!
Já fiz algumas palestras antes sobre o assunto, como você pode ver no vídeo a seguir (não deixe de ver os slides no meu SpeakerDeck) e este é um tema bastante recorrente para mim porque, pelo menos aqui no Brasil, a maioria das pessoas não sabe o que é ou nunca utilizou gRPC em nenhum projeto.
Porém, o gRPC não é uma tecnologia muito nova, ele já está aqui há algum tempo e já vem sendo utilizado em larga escala em projetos muito grandes como o Docker e o Kubernetes, então decidi montar esta série de artigos para explicar de uma vez por todas o que é o gRPC e como você consegue criar suas aplicações JavaScript e TypeScript com ele de forma simples e fácil!
Roadmap
Antes de começarmos com a informação em si, vamos entender o que iremos ver ao longo desta jornada. Dividi este guia em três partes, nesta primeira parte vamos passar pela história do gRPC, entender as ideias por trás da construção desta tecnologia, problemas, vantagens e muito mais.
Já na segunda parte, vamos por mais a mão na massa e construir nossa aplicação usando gRPC enquanto entendemos todo o ecossistemas e as ferramentas que compõem a aplicação. Tudo isso usando JavaScript.
Por fim, na terceira parte vamos modificar a aplicação e melhorá-la para usar TypeScript ao invés de JavaScript. Desta forma vamos ter a inferência nativa de tipos da nossa API e como podemos nos comunicar com todas as camadas de forma correta.
História
O gRPC foi criado pela Google como um projeto de código aberto em 2015 como uma melhoria em uma arquitetura de comunicação chamada de RPC (Remote Procedure Call).
O RPC é um modelo de comunicação que remonta desde meados dos anos 70 quando Bruce Jay Nelson em 1981, que trabalhava na Xerox PARC utilizou essa nomenclatura para descrever a comunicação entre dois processos dentro do mesmo sistema operacional – isso ainda é utilizado – porém, o modelo RPC é mais usado para comunicação de baixo nível, até que o Java implementou uma API chamada JRMI (Java Remote Method Invocation) que funciona basicamente da mesma forma que o gRPC funciona hoje em dia, porém de uma maneira mais voltada para métodos e classes e não para comunicação entre processos.
Nós vamos falar um pouco mais sobre a arquitetura de uma chamada gRPC nos próximos parágrafos.
O "g" no gRPC não significa Google, na verdade, ele não tem um significado único, ele muda de acordo com cada release do engine do gRPC. Existe até um documento mostrando todos os nomes que o "g" teve ao longo das versões.
A ideia base do gRPC era ser muito mais performático do que a sua contraparte ReST por ser baseado no HTTP/2 e utilizar uma Linguagem de Definição de Interfaces (IDL) conhecida como Protocol Buffers (protobuf). Este conjunto de ferramentas torna possível que o gRPC seja utilizado em diversas linguagens ao mesmo tempo com um overhead muito baixo enquanto continua sendo mais rápido e mais eficiente do que as demais arquiteturas de chamadas de rede.
Além disso, a chamada de um método remoto é, essencialmente, uma chamada comum de um método local, que é interceptada por um modelo local do objeto remoto e transformada em uma chamada de rede, ou seja, você está chamando um método local como se fosse um método remoto. Vamos ver um exemplo.
Exemplo de funcionamento
Vamos mostrar um exemplo de um servidor gRPC escrito em Node.js para o controle de livros, como falamos, o gRPC utiliza o protobuf, que vamos ver em mais detalhes nos próximos parágrafos, este é o nosso arquivo protobuf que gerou nosso serviço:
syntax = "proto3";
message Void {}
service NoteService {
rpc List (Void) returns (NoteList);
rpc Find (NoteId) returns (Note);
}
message NoteId {
string id = 1;
}
message Note {
string id = 1;
string title = 2;
string description = 3;
}
message NoteList {
repeated Note notes = 1;
}
Nele estamos definindo toda a nossa API gRPC de forma simples, rápida e, o melhor de tudo, versionável. Agora podemos carregar nosso servidor com este código:
const grpc = require('grpc')
const NotesDefinition = grpc.load(require('path').resolve('../proto/notes.proto'))
const notes = [
{ id: '1', title: 'Note 1', description: 'Content 1' },
{ id: '2', title: 'Note 2', description: 'Content 2' }
]
function List (_, callback) {
return callback(null, notes)
}
function Find ({ request: { id } }, callback) {
return callback(null, notes.find((note) => note.id === id))
}
const server = new grpc.Server()
server.addService(NotesDefinition.NoteService.service, { List, Find })
server.bind('0.0.0.0:50051', grpc.ServerCredentials.createInsecure())
server.start()
E veja como nosso client fica simples nas chamadas:
const grpc = require('grpc')
const NotesDefinition = grpc.load(require('path').resolve('../proto/notes.proto'))
const client = new NotesDefinition.NoteService('localhost:50051', grpc.credentials.createInsecure())
client.list({}, (err, notes) => {
if (err) throw err
console.log(notes)
})
client.find(Math.floor(Math.random() * 2 + 1).toString(), (err, note) => {
if (err) throw err
if (!note.id) return console.log('Note not found')
return console.log(note)
})
Veja que, basicamente as nossas chamadas são como se estivéssemos chamando um método de um objeto client local, e este método vai ser convertido em uma chamada de rede e enviado para o servidor, que irá receber a chamada e converter novamente em um objeto local e devolver a resposta.
Arquitetura
Arquiteturas RPC são muito parecidas. A ideia base é que temos sempre um servidor e um cliente, do lado do servidor temos uma camada que é chamada de skeleton , que é essencialmente um decriptador de uma chamada de rede para uma chamada de função, este é o responsável por chamar a função do lado do servidor.
Enquanto isso, do lado do cliente, temos uma chamada de rede feita por um stub , que é como um "falso" objeto representando o objeto do lado do servidor. Este objeto tem todos os métodos com suas assinaturas.
Estes nomes variam de implementação para implementação, no JRMI tínhamos skeleton e stub, porém a implementação do gRPC nomeia os dois lados como stubs.
Este é o diagrama de funcionamento de uma chamada RPC comum.

O gRPC tem um funcionamento muito próximo do diagrama que acabamos de ver, a diferença é que temos uma camada extra que é o framework gRPC interpretando as chamadas codificadas com a IDL do protobuf:

Como você pode ver, o funcionamento é basicamente o mesmo, temos um cliente que converte as chamadas feitas localmente em chamadas de rede binárias com o protobuf e as envia pela rede até o servidor gRPC que as decodifica e responde para o cliente.
HTTP/2
O HTTP/2 já é utilizado faz algum tempo e vem se tornando a principal forma de comunicação na web desde 2015.

Entre as muitas vantagens do HTTP/2 (que também foi criado pela Google), está o fato de que ele é muito mais rápido do que o HTTP/1.1 por conta de vários fatores que vamos entender.
Multiplexação de requests e respostas
Tradicionalmente, o HTTP não pode enviar mais de uma requisição por vez para um servidor, ou então receber mais de uma resposta na mesma conexão, isso torna o HTTP/1.1 mais lento, já que ele precisa criar uma nova conexão para cada requisição.
No HTTP/2 temos o que é chamado de multiplexação, que consiste em poder justamente receber várias respostas e enviar várias chamadas em uma mesma conexão. Isto só é possível por conta da criação de um novo frame no pacote HTTP chamado de Binary Framing. Este frame essencialmente separa as duas partes (headers e payload) da mensagem em dois frames separados, porém contidos na mesma mensagem dentro de um encoding específico.
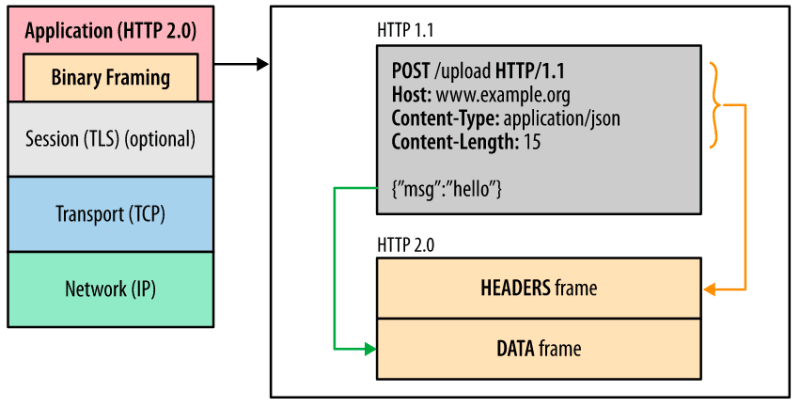
Compressão de headers
Outro fator que transforma o HTTP/2 em um protocolo mais rápido é a compressão de headers. Em alguns casos os headers de uma chamada HTTP podem ser maiores do que o seu payload, por isso o HTTP/2 tem uma técnica chamada HPack que faz um trabalho bastante interessante.
Inicialmente tudo na chamada é comprimido, inclusive os headers, isso ajuda na performance porque podemos trafegar os dados binários ao invés de texto. Além disso, o HTTP/2 mapeia os headers que vão e vem de cada lado da chamada, dessa forma é possível saber se os headers foram alterados ou se eles estão iguais aos da última chamada.
Se os headers foram alterados, somente os headers alterados são enviados, e os que não foram alterados recebem um índice para o valor anterior do header, evitando que headers sejam enviados repetidamente.

Como você pode ver, somente o path dessa requisição mudou, portanto só ele será enviado.
Protocol Buffers
Os protocol buffers (ou só protobuf ), são um método de serialização e desserialização de dados que funciona através de uma linguagem de definição de interfaces (IDL).
Foi criado pela Google em 2008 para facilitar a comunicação entre microsserviços diversos. A grande vantagem do protobuf é que ele é agnóstico de plataforma, então você poderia escrever a especificação em uma linguagem neutra (o próprio proto) e compilar esse contrato para vários outros serviços, dessa forma a Google conseguiu unificar o desenvolvimento de diversos microsserviços utilizando uma linguagem única de contratos entre seus serviços.
O protobuf em si não contém nenhuma funcionalidade, ele é apenas um descritivo de um serviço. O serviço no gRPC é um conjunto de métodos, pense nele como se fosse uma classe. Então podemos descrever cada serviços com seus parâmetros, entradas e saídas.
Cada método (ou RPC) de um serviço só pode receber um único parâmetro de entrada e um de saída, por isso é importante podermos compor as mensagens de forma que elas formem um único componente.
Além disso, toda mensagem serializada com o protobuf é enviada em formato binário, de forma que a sua velocidade de transmissão para seu receptor é muito mais alta do que o texto puro, já que o binário ocupa menos banda e, como o dado é comprimido pelo HTTP/2, o uso de CPU também é muito menor.
Outra grande vantagem que contribui para o aumento da velocidade do protobuf é a separação de contexto e conteúdo. Quando estamos usando formatos como JSON, o contexto vem junto com a mensagem, por exemplo:
{
"name": "Lucas",
"age": 26
}
Quando convertemos isso para uma mensagem no formato protobuf, vamos ter o seguinte arquivo:
syntax = "proto3";
message Name {
string name = 1;
int32 age = 2;
}
Veja que não temos o header da mensagem junto da mensagem, apenas um índice informando qual é o local que aquele campo deve estar.
Encoding
Quando utilizamos o compilador do protobuf (chamado de protoc), podemos rodar o comando a seguir usando o nosso exemplo anterior: echo 'name: "Lucas";age: 26' | protoc --encode=Name name.proto > name.bin.
Isso vai criar um arquivo binário com o nome name.bin, se abrirmos o arquivo binário em um hex viewer (como o do VSCode), teremos a seguinte cadeia de bits:
0A 05 4C 75 63 61 73 10 1A
Temos 9 bytes representados aqui, contra os 24 do JSON, e isso é o suficiente para poder entender a mensagem, por exemplo, o que temos aqui é o seguinte:

- O primeiro byte
0A, diz o índice e o tipo da mensagem.0Aem decimal é 10, ou seja,0000 1010em binário, de acordo com a especificação de encoding do protobuf, os últimos três bits são reservados para o tipo e o MSB (primeiro bit da esquerda) pode ser descartado, então reagrupando os bits temos0001 010, portanto nosso tipo é010, que é 2 em binário, o numero que representa umastringno protobuf. Já no primeiro byte0001temos o índice do campo, que é 1, como definimos na nossa mensagem. - O byte seguinte
05nos diz o tamanho desta string, que é de 5 bytes porque "Lucas" tem 5 letras. - Os 5 bytes seguintes
4C 75 63 61 73são a string "Lucas" convertidas para hexadecimal e desconvertidas para UTF-8. - O penúltimo byte
10é relativo ao segundo campo, se convertermos em binário o numero10teremos0001 0000, como fizemos no primeiro campo, vamos agrupar os 3 bits da direita passando o zero mais a esquerda (4º bit da direita para a esquerda) para o grupo seguinte e removemos o MSB ficando0010 000, ou seja, temos o tipo0, que é varint , pelos últimos 3 bits, e o primeiro grupo nos dá0010, ou 2 em binário, que é o índice do segundo campo. - O último bit é o valor deste varint, o valor
0x1Apara binário é0001 1010, então podemos somente converter para um decimal comum somando as potências de 2:2 + 8 + 16 = 26, que é o valor que colocamos no segundo campo.
Então essencialmente, nossa mensagem é 125Lucas2026 , veja que temos 12 bytes aqui, mas no encoding temos apenas 9, isto porque dois bytes representam 2 valores ao mesmo tempo e temos apenas 1 byte para o número 26 enquanto usamos 2 para a string "26".
É possível usar o protobuf sem o gRPC?
Sim, uma das coisas mais legais no gRPC é que ele é um conjunto de ferramentas, que juntas, trabalham muito bem. Portanto o gRPC é um conjunto de HTTP/2 com protobuf e um sistema de chamadas remotas muito rápido.
Isso significa que podemos utilizar o compilador do protobuf para gerar um SDK de encoding, que vai permitir que você codifique e decodifique suas mensagens utilizando o protobuf.
Por exemplo, vamos criar um arquivo simples:
syntax = "proto3";
message Pessoa {
uint64 id = 1;
string email = 2;
}
Agora podemos executar a seguinte linha no nosso terminal para gerar um arquivo .js que conterá uma classe Pessoa com os setters e getters configurados, bem como os encoders e decoders:
mkdir -p dist && protoc --js_out=import_style=commonjs,binary:dist ./pessoa.proto
O compilador vai criar um arquivo pessoa_pb.js na pasta dist usando o modelo de importação CommonJS (isso é obrigatório se você for executar com Node.js), e ai podemos escrever um arquivo index.js:
const {Pessoa} = require('./pessoa_pb')
const p = new Pessoa()
p.setId(1)
p.setEmail('hello@lsantos.dev')
const serialized = p.serializeBinary()
console.log(serialized)
const deserialized = Pessoa.deserializeBinary(serialized)
console.table(deserialized.toObject())
console.log(deserialized)
Então vamos precisar instalar o protobuf com npm install google-protobuf e executamos o código:
Uint8Array(21) [
8, 1, 18, 17, 104, 101,
108, 108, 111, 64, 108, 115,
97, 110, 116, 111, 115, 46,
100, 101, 118
]
┌─────────┬─────────────────────┐
│ (index) │ Values │
├─────────┼─────────────────────┤
│ id │ 1 │
│ email │ 'hello@lsantos.dev' │
└─────────┴─────────────────────┘
{
wrappers_: null,
messageId_: undefined,
arrayIndexOffset_: -1,
array: [1, 'hello@lsantos.dev'],
pivot_: 1.7976931348623157e+308,
convertedPrimitiveFields_: {}
}
Veja que temos um encoding igual ao que analizamos antes, uma tabela dos valores em objetos e a classe inteira.
Utilizar o protobuf como camada de contratos é muito útil, por exemplo, para padronizar as mensagens enviadas entre serviços de mensageria e entre microsserviços. Como estes serviços podem receber qualquer tipo de entrada, o protobuf acaba criando uma forma de garantir que todas as entradas sejam válidas.
Vantagens do gRPC
Como pudemos ver, o gRPC tem várias vantagens sobre o modelo ReST tradicional:
- Mais leve e mais rápido por utilizar codificação binária e HTTP/2
- Multi plataforma com a mesma interface de contratos
- Funciona em muitas plataformas com pouco ou nenhum overhead
- O código é auto documentado
- Implementação relativamente fácil depois do desenvolvimento inicial
- Excelente para trabalhos entre times que não vão se encontrar, principalmente para definir contratos de projetos open source.
Problemas
Assim como toda a tecnologia, o gRPC não é uma bala de prata e não resolve todos os problemas, temos alguns defeitos:
- O protobuf não possui um package manager para poder gerenciar as dependências entre arquivos de interface
- Exige uma pequena mudança de paradigma em relação ao modelo ReST
- Curva de aprendizado inicial é mais complexa
- Não é uma especificação conhecida por muitos
- Por conta de não ser muito conhecido, a documentação é esparsa
- A arquitetura de um sistema usando gRPC pode se tornar um pouco mais complexa
Casos de uso
Independente dos problemas e de tudo que a tecnologia tem para oferecer, temos uma série de casos de uso bem famosos no mundo open source que utiliza o gRPC como meio de comunicação.
Kubernetes
O Kubernetes em si utiliza o gRPC como meio de comunicação entre o Kubelet e os CRIs que compõe a plataforma de execução de containers (como já falamos em vários artigos, como este, este e este).
A facilidade de implementar uma interface usando o protobuf facilita a comunicação entre os times, ainda mais um time como o do Kubernetes que tem que suportar uma larga quantidade de provedores que não são nem conhecidos.
KEDA
O projeto KEDA, também para Kubernetes, utiliza como uma funcionalidade principal a capacidade de se criar external scalers usando uma interface gRPC para a comunicação com o operador principal.
Um dos projetos da CNCF no qual sou um contribuidor, o HTTP add on para o KEDA, utilizar este meio para criar um scaler externo que se comunica com o KEDA para aumentar a quantidade de pods em um cluster baseado na quantidade de requisições HTTP, como você pode ver aqui.
containerd
O principal runtime de containers da atualidade, o containerd é o projeto que dá vida ao Docker e ao Kubernetes atualmente. Ele também possui uma interface gRPC para comunicação com serviços externos.
Conclusão
Nesta primeira parte mergulhamos um pouco sobre como funciona e o que é o gRPC e seus componentes, nas próximas partes deste guia vamos construir algumas aplicações e mostrar o ecossistema de ferramentas que existe para esta tecnologia sensacional.


















