The Llama Run: A Deep Dive into the World of LLAMA Models
Introduction:
The field of artificial intelligence is constantly evolving, with new advancements emerging at an unprecedented pace. One of the most exciting developments in recent years has been the emergence of large language models (LLMs), powerful algorithms capable of understanding and generating human-like text. These models have revolutionized various domains, including natural language processing, machine translation, and code generation. Among the prominent LLMs, the Llama family has emerged as a force to be reckoned with, offering remarkable capabilities and accessibility. This article delves into the world of Llama models, exploring their architecture, training process, applications, and potential impact.
Understanding LLAMA Models:
LLAMA (Large Language Model for Application Massive) models are a series of foundational LLMs developed by Meta AI. These models are known for their impressive performance across a wide range of natural language tasks, thanks to their massive size and extensive training data. The Llama family currently includes several variants, each with its own unique set of strengths and weaknesses:
- Llama 7B: The smallest model in the family, with 7 billion parameters, designed for resource-constrained environments.
- Llama 13B: A mid-sized model with 13 billion parameters, offering a balance of performance and efficiency.
- Llama 33B: A larger model with 33 billion parameters, capable of handling more complex tasks.
- Llama 65B: The largest model in the family, with 65 billion parameters, demonstrating state-of-the-art performance.
Architecture and Training:
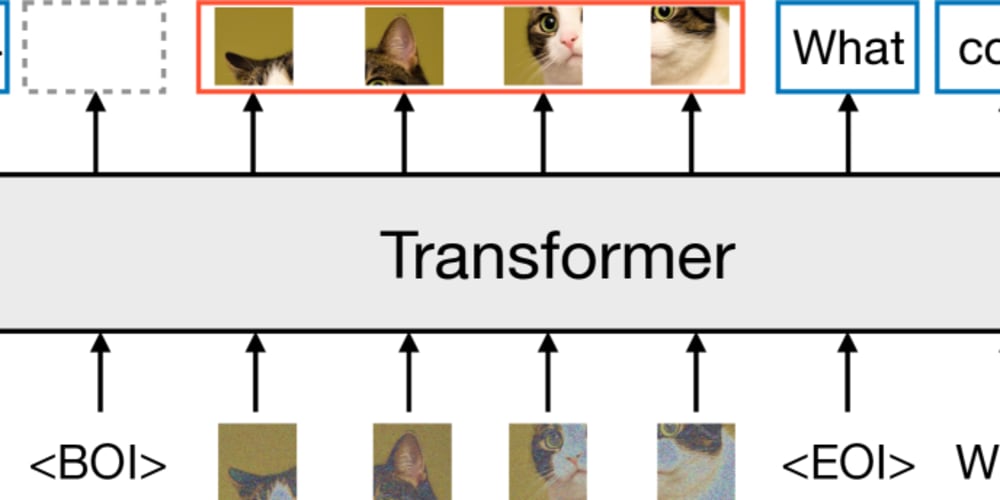
LLAMA models are based on a transformer architecture, which is the cornerstone of many advanced NLP models. The transformer architecture employs a self-attention mechanism, allowing the model to process long sequences of text efficiently and capture complex dependencies between words.
Key Components of the Transformer Architecture:
- Encoder: The encoder part of the transformer takes the input text and transforms it into a sequence of numerical representations called embeddings.
- Decoder: The decoder receives the encoded input and generates the output text, using the self-attention mechanism to understand the context and relationships between words.
- Multi-Head Attention: This mechanism allows the model to attend to different aspects of the input sequence simultaneously, improving its ability to understand complex relationships.
- Feedforward Networks: These networks are responsible for processing the information from the attention mechanism and generating the output.
Training LLAMA Models:
Training a LLAMA model requires a massive amount of data and computational resources. The models are trained on a massive corpus of text, including books, articles, code, and other publicly available data. The training process involves minimizing a loss function, which measures the difference between the predicted output and the actual target. Gradient descent algorithms are used to adjust the model's parameters iteratively until the loss is minimized.
Applications of LLAMA Models:
LLAMA models have a wide range of applications, spanning various domains:
- Natural Language Understanding: LLAMA models can analyze text, identify key concepts, and understand the sentiment expressed in it. This enables them to power applications like chatbots, question answering systems, and text summarization tools.
- Text Generation: LLAMA models can generate human-like text, writing articles, poems, stories, and even code. This capability has opened up possibilities for content creation, creative writing assistance, and code generation tools.
- Machine Translation: LLAMA models can translate text between different languages, providing accurate and fluent translations. This technology has revolutionized communication and access to information across language barriers.
- Code Generation: LLAMA models have demonstrated remarkable proficiency in generating code in various programming languages. This opens up exciting possibilities for automating code development tasks and improving software development efficiency.
Step-by-Step Guide: Using a LLAMA Model
This section outlines a simplified guide for utilizing a LLAMA model for text generation:
- Installation: Install the necessary libraries and tools (e.g., Python, Hugging Face Transformers).
- Loading the Model: Load a pre-trained LLAMA model from a repository (e.g., Hugging Face Model Hub).
- Input Processing: Prepare the input text, ensuring it is properly formatted and tokenized.
- Model Inference: Run the input text through the loaded model to obtain the generated output text.
- Output Post-Processing: Decode the generated output, converting tokens back into readable text.
Example:
from transformers import pipeline
# Load a pre-trained Llama 7B model
generator = pipeline('text-generation', model='facebook/bart-large')
# Define the input text
input_text = "The quick brown fox jumps over the lazy dog."
# Generate the output text
output_text = generator(input_text, max_length=50, num_return_sequences=1)[0]['generated_text']
# Print the generated output
print(output_text)
Conclusion:
LLAMA models represent a significant advancement in the field of artificial intelligence. Their impressive performance, accessibility, and wide range of applications have made them a valuable tool for various industries and domains. As research and development in this area continue, we can expect even more powerful and sophisticated LLAMA models to emerge, driving innovation in natural language processing and artificial intelligence.
Best Practices for LLAMA Model Usage:
- Choose the right model: Select the appropriate model size based on your specific needs and computational resources.
- Fine-tuning: Fine-tune the model on your specific domain data to enhance its performance on relevant tasks.
- Ethical considerations: Ensure responsible usage of LLAMA models, considering potential biases and societal implications.
- Stay updated: Keep up with the latest advancements in LLAMA models and related technologies to leverage the latest capabilities.
Image:

Note: This image depicts a general transformer architecture, as there are no official visuals of the LLAMA model's internal architecture publicly available.